本篇是系列中的第二篇内容,我们继续聊聊如何把一个简化过的私有云环境部署在笔记本里,以满足低成本、低功耗、低延时的实验环境。
在上篇《准备篇》中,我们聊过了基础虚拟化相关的事情,在虚拟机环境准备就绪之后,在继续折腾容器集群之前,我们还需要做一些基础技术设施建设,监控就是其中比较重要的一个组成部分。
写在前面
说起监控,我相信许多时候,这是一个很容易被忽略或者被省略的部分。
尤其是在个人场景或者小公司或者团队,因为业务量小,不容易出问题,出了问题使出 “关机重启敲一敲” 的解决方案的也大有人在。在长久的工作过程中,我们都知道,没有监控最好的情况是无事发生,最糟糕的情况则是,问题发生了但是在早期没有被发现,随着时间推移,这个事情越来越严重,我们需要付出数倍的成本来解决问题。
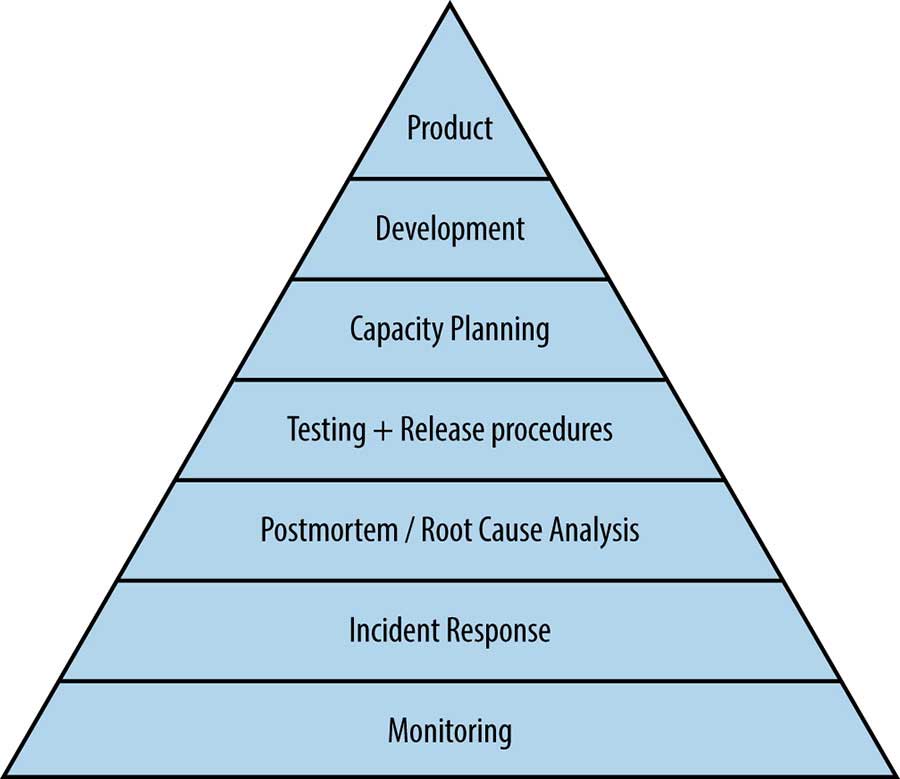
《Google SRE》 一书中提到的“服务可靠性金字塔”中的基石,同样也是监控。虽然我们很难达到 Google 业务的复杂度和量级,但是重视监控,以客观的数据事实来推动我们做相对正确的决策,还是值得每个人和团队去践行的。书中有一段比较形象的例子:
Without monitoring, you have no way to tell whether the service is even working; absent a thoughtfully designed monitoring infrastructure, you’re flying blind.
如果在搭建环境的早期,就规划设计了监控服务,那么在完善整体的过程中,便可以在有数据支撑的情况下,快速定位和判断哪些新增组件需要完善和调整,这样一来就避免了盲人摸象的状况发生。
监控选型
如果你的业务都“跑在云上”,那么监控选型的事情其实可以变的很简单。尤其是如果你没有定制需求,那么在你的预算之内,云平台提供什么,你用什么就是了。甚至如果我们只跑一两台“虚拟机/服务器”,预设的运行程序数量也比较少的话,使用云平台提供的“探针式”的监控也是可以的。
因为本文的初衷是搭建简化的云服务环境,并且希望能满足低成本、低功耗、低延时的实验环境, 故需要从开源产品中进行选型、部署和使用。
选型细节经验
在开始具体选择之前,先来分享一些之前折腾监控时的小经验:
- 如果你不能为所有的点都设置监控,以及设定合适的监控规则。那么至少要监控关键位置,形成你自己的监控网,而不是一个个监控散点。
- 监控设施的监控策略、监控指标要灵活变通,而不是从“创业”初期开始到中后期还一成不变,僵硬的监控规则会遗漏非常多重要的信息。
- 尽量不做“补作业”的事情,事后补监控的成本相比较事前做功课,只高不低(别忘记业务实际损失)
- 尽可能提高采样率,避免不准确的、“懒惰的”监控数据掩盖了发生的事情。
- 数据可视化和易观察有关联性,但是不一定是正相关。所以在选型上,不要追求酷炫,要时刻明确你的需要到底是什么。
- 根据自己的经济实力,去选择基础平台和,避免选择“大而全”的“银弹”(众所周知,没有银弹),除非你对这个方案的提供团队非常信任。
- 适当选择开源开放的平台,在有人同行的情况下,群策群力始终是有效的问题解决方式(你遇到的问题不会只有你一个人遇到)。
那么,比较通用的、适合从零到一阶段使用的监控系统,该选择谁呢?
开源监控产品:“普罗米修斯”
时值 2021 年末,考虑搭建监控平台,相对主流的选择都在 Prometheus 和 Zabbix 之间摇摆。前者从 CNCF 带着光环毕业,在许多场景下泛指 “Prom Stacks”,能够模块化灵活提供快速搭建整套监控体系的方案 ,而不单单只是作为对标 InfluxDB 而存在的时序数据库。而后者则单纯的多,或者说最在某些程度上能够代表上一世代的监控思路的产品:大而全。
至于日志落地存储,一般的选择有直接使用类似 Prometheus 的 “TSDB”的方案、也有类似 Zabbix 使用的 MySQL / PostgreSQL,有一些希望精细化搜索日志的场景,我们甚至会选择使用 ES 来作为落地方案。当然,如果你的数据量小的话,使用按日期归档的纯文本也不是不可以。
考虑到易于集成的需求,本文选择比较有代表性的 “Prom” 全家桶来搭建基础的监控服务,还不熟悉 Prometheus 的同学可以先看看它的光辉履历。
Prometheus 具备了许多用户喜欢的功能特点:
部署灵活,环境适应性强 。除了易于安装部署外,本身对于运行模式和存储模式也都比较宽容,可以多节点分布式运行,搭配分布式存储水平扩展,也可以多节点单一数据库,也可以单节点单一数据库模式运行。它既可以使用静态配置使用,也可以使用服务发现的方式来动态的汇聚需要监控的项目。
内置查询语言,数据查询灵活,还有大量现成模版,减少了定制软件本身的需要。如果使用 MySQL 或者其他数据库为后端的监控方案,还需要使用类似 ClickHouse 之类的方案进行查询加速,至于使用 ES 进行查询的方案嘛。众所周知,在资源性价比上,这个方案比较没有优势。
支持灵活的数据交互,数据监控依赖客户端和服务端的信息交换,而这个交换无非“推”、“拉”两个模式,多数监控采用拉模式定期收取数据。Prometheus 则支持使用网关插件集成的方式支持按需上报的“主动推送”模式。而且它的交互形式为容易调整的 HTTP 响应,如果需要调整和加工,直接在上报/拉取的过程中添加一个过程进行流程化修改也很方便。
语言支持、软件生态相对完善,Prom 覆盖了主流的开发语言,以及多数庞大用户量的软件的集成接入,能省不少功夫做集成。剩下的时间可以去做其他更有价值的事情。
报警定制灵活、简单,不论是报警规则策略管理,还是集成三方通知模块,在 Prom 里都只需要几行配置。只要你喜欢,也可以将它集成到各种 IM 里,比如 Slack、钉钉、企业微信、飞书、以及企业里自己定制开发的 IM里。或者通过云平台的短信和机器人电话进行告警通知。
可视化容易,这点应该是许多人选择的主要原因之一。不论是使用自带的 HTML 模版,还是搭配 Prom Stack 中的 Grafana 使用,都非常容易,甚至可以搭配公有云更酷炫的可视化产品一起使用。
聊了这么多,让我们使用容器来快速搭建一套适合本系列,或者说小团队使用的监控服务吧。
使用容器搭建一套最简单的监控
为了方便读者的使用,我将下面的配置上传到了 GitHub 上,可以自取。和基础篇中一样,为了省事,我在 DHCP 中配置了一条规则,给这台专门用于监控服务的虚拟机起了一个名字“monitor.lab.com”,方便后续调试和访问:
address=/monitor.lab.com/10.11.12.186
主应用及数据库:Prometheus
Prometheus 作为监控服务中数据落地存储的数据库,所以我们需要先配置它。
version: "3"
services:
prometheus:
image: prom/prometheus:v2.30.3
container_name: prometheus
restart: always
user: root
volumes:
- ./config:/etc/prometheus
- ./data:/prometheus
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--web.console.libraries=/etc/prometheus/console_libraries"
- "--web.console.templates=/etc/prometheus/consoles"
- "--storage.tsdb.retention.time=1y"
# 根据自己需求来考虑是否开启
# https://prometheus.io/docs/prometheus/latest/migration/#prometheus-lifecycle
- "--web.enable-lifecycle"
expose:
- 9090
ports:
- 9090:9090
networks:
- monitor
logging:
driver: "json-file"
options:
max-size: "1m"
networks:
monitor:
external: true
上面的内容中,配置了一个基本能开箱即用的 Prometheus 服务,我们将接收到的数据默认存储一年,并将采集的数据直接持久化到本机中,相对于配置文件的 data 目录中。将上面的内容保存为 docker-compose.yml 后,我们来继续编写它的配置文件。
global:
# 监控自身状态
scrape_interval: 15s
# 报警评估周期
# 可以关联阅读,理解报警的生命周期
# https://pracucci.com/prometheus-understanding-the-delays-on-alerting.html
evaluation_interval: 15s
# 和其他组件时通讯时使用,起个名字区别不同的数据来源
external_labels:
monitor: 'docker-prometheus'
# 监控规则文件列表
rule_files:
- "alert.rules"
# 配置要与 Prometheus 通信(被抓取)的服务接口
scrape_configs:
- job_name: 'nodeexporter'
scrape_interval: 5s
static_configs:
- targets: ['nodeexporter:9100']
- job_name: 'cadvisor'
scrape_interval: 5s
static_configs:
- targets: ['cadvisor:8080']
- job_name: 'prometheus'
scrape_interval: 10s
static_configs:
- targets: ['localhost:9090']
- job_name: 'pushgateway'
scrape_interval: 10s
honor_labels: true
static_configs:
- targets: ['pushgateway:9091']
# 配置监控报警服务
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- 'alertmanager:9093'
上面的配置中,出现了许多不同的服务以及这些服务的具体访问端口,未来我们可以针对这些服务具体部署的位置进行调整,为了跑通第一个服务,我们目前先不动它。将上面的内容保存到 config/prometheus.yml,我们继续编写监控规则文件。如果能想阅读完整的配置规范,可以阅读这里。
参考官方配置,我们不难写出类似下面的监控配置:
groups:
- name: example
rules:
- alert: service_down
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- alert: high_load
expr: node_load1 > 0.5
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} under high load"
description: "{{ $labels.instance }} of job {{ $labels.job }} is under high load."
这里入门的模版,我推荐使用包含了容器基础模版的开源项目 stefanprodan/dockprom 并在它的基础上进行调整。将内容保存到 config/alert.rules 后,使用 docker-compose logs -f启动服务,看到类似下面的日志后,就说明 应用启动成功啦。
prometheus | level=info ts=2021-10-29T13:08:11.712Z caller=main.go:438 msg="Starting Prometheus" version="(version=2.30.3, branch=HEAD, revision=f29caccc42557f6a8ec30ea9b3c8c089391bd5df)"
...
prometheus | level=info ts=2021-10-29T13:08:11.724Z caller=main.go:794 msg="Server is ready to receive web requests.
服务启动之后,在浏览器中访问 http://monitor.lab.com:9090/ 就能看到 Prometheus 的默认界面了,不过因为我们目前什么数据都没有上报,所以就先不进行查询啦。
系统采样组件:Node Exporter
一般情况下,我们需要采集的监控数据,除了应用状态之外,还有服务器硬件的基础状态,Prometheus 应用默认不具备检测和采样操作系统状态的能力。所以官方推出了 Node Exporter 这个应用组件,以及一个简单的入门文档。
虽然官方出于容器和主机需要充分隔离的思考,不推荐将 Node Exporter 使用容器部署,但是实际上,我们只需要将系统内的文件以只读方式映射到容器内,就可以使用“绿色无污染”的容器方式来运行这个服务了。
version: "3"
services:
nodeexporter:
image: prom/node-exporter:v1.2.2
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- "--path.procfs=/host/proc"
- "--path.rootfs=/rootfs"
- "--path.sysfs=/host/sys"
- "--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)"
restart: always
expose:
- 9100
ports:
- 9100:9100
networks:
- monitor
logging:
driver: "json-file"
options:
max-size: "1m"
networks:
monitor:
external: true
还是使用 docker-compose up -d 将应用运行起来即可。如果你使用 docker-compose logs -f 查看日志,看到类似下面的内容,那么你的应用就已经在正常工作啦。
nodeexporter | level=info ts=2021-10-30T04:42:11.428Z caller=node_exporter.go:182 msg="Starting node_exporter" version="(version=1.2.2, branch=HEAD, revision=26645363b486e12be40af7ce4fc91e731a33104e)"
nodeexporter | level=info ts=2021-10-30T04:42:11.428Z caller=node_exporter.go:183 msg="Build context" build_context="(go=go1.16.7, user=root@b9cb4aa2eb17, date=20210806-13:44:18)"
nodeexporter | level=info ts=2021-10-30T04:42:11.428Z caller=filesystem_common.go:110 collector=filesystem msg="Parsed flag --collector.filesystem.mount-points-exclude" flag=^/(sys|proc|dev|host|etc)($|/)
nodeexporter | level=info ts=2021-10-30T04:42:11.428Z caller=filesystem_common.go:112 collector=filesystem msg="Parsed flag --collector.filesystem.fs-types-exclude" flag=^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$
nodeexporter | level=info ts=2021-10-30T04:42:11.428Z caller=node_exporter.go:108 msg="Enabled collectors"
nodeexporter | level=info ts=2021-10-30T04:42:11.429Z caller=node_exporter.go:115 collector=arp
nodeexporter | level=info ts=2021-10-30T04:42:11.429Z
...
nodeexporter | level=info ts=2021-10-30T04:42:11.429Z caller=node_exporter.go:115 collector=zfs
nodeexporter | level=info ts=2021-10-30T04:42:11.429Z caller=node_exporter.go:199 msg="Listening on" address=:9100
nodeexporter | level=info ts=2021-10-30T04:42:11.434Z caller=tls_config.go:191 msg="TLS is disabled." http2=false
当服务运行完毕之后,我们访问 http://monitor.lab.com:9100,可以看到类似下面的文本日志数据,这些就是当前主机的实时运行状态啦。

如果你的服务器是 Windows ,那么建议使用它专用的 Exporter,或者如果你需要监控 Nvidia GPU,也可以使用显卡官方提供的 Exporter。
容器采样应用:cAdvisor
cAdvisor(Container Advisor)是谷歌技术团队出品的一个“容器探针”。可以让用户了解到正在运行过程中的容器资源使用情况,以及某一时刻下的性能状况。将 c Advisor 和 Prometheus 一起使用,我们就能够对系统中的容器运行状态有更直观的了解啦。
version: "3"
services:
cadvisor:
image: google/cadvisor:v0.33.0
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg:/dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
# 仅限 Linux 环境使用
- /cgroup:/cgroup:ro
restart: always
ports:
- 8080:8080
expose:
- 8080
networks:
- monitor
logging:
driver: "json-file"
options:
max-size: "1m"
networks:
monitor:
external: true
将上面的配置保存为 docker-compose.yml ,然后使用 docker-compose up -d 启动应用,我们直接打开浏览器,访问应用页面,不出意外的话,你将看到类似下面的界面。

推送网关:Push-Gateway
上面的采样工具和 Prometheus 配合工作的时候,使用的都是默认的拉取模式。如果我们的服务只需要在某一个时刻进行数据记录,那么这个拉取模式就显得比较“啰嗦”了,相比之下“推送”模式会更适合。
官方文档中对于 Push Gateway 的使用建议非常保守,主要原因有两个:服务可靠性需要做额外的工作,使用推送而非默认的拉取模型不利于使用 prometheus 进行统一、自动的服务监控管理。官方对于推送模型的建议使用场景仅限低频非周期性的批处理任务。
其实可靠性还是比较好处理的,使用 Traefik 或者传统的负载均衡很容易快速完成水平
version: '3'
services:
pushgateway:
image: prom/pushgateway:v1.4.2
container_name: pushgateway
restart: always
ports:
- 9091:9091
expose:
- 9091
networks:
- monitor
logging:
driver: "json-file"
options:
max-size: "1m"
networks:
monitor:
external: true
另外,如果 Prom 和 Push Gateway 不在相同网络,官方除了推荐将它们放置在相同网络之外,推荐使用 PushProx。
同样,启动应用之后,我们使用浏览器访问,http://monitor.lab.com:9091/,能够看到应用运行中的状态。
监控告警:Alert Manager
Alert Manager 是 Prom 非常重要的官方组件之一,负责管理以及执行报警通知策略。使用容器来运行它的配置非常简单:
version: "3"
services:
alertmanager:
image: prom/alertmanager:v0.23.0
container_name: alertmanager
volumes:
- ./config.yml:/etc/alertmanager/config.yml
command:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
restart: always
expose:
- 9093
ports:
- 9093:9093
networks:
- monitor
logging:
driver: "json-file"
options:
max-size: "1m"
networks:
monitor:
external: true
在配置规则之前,我建议先阅读官方文档中对“沉默”、“抑制”、“分组”的告警相关概念的定义,然后直接参考 alertmanager GitHub 官方配置进行调整即可。当然,结合我们日常实际使用情况,你可以搜索“ alertmanager 微信、钉钉、飞书 ” 的具体配置,进行酌情修改,因为配置过程比较冗长,这里就不再展开了。
将告警配置配置完毕之后,保存到和上面的 docker-compose.yml 相同目录下,文件名设置为 config.yml ,然后使用 docker-compose up -d 启动应用即可。
不出意外的话,使用 docker-compose logs -f 将看到类似下面的日志:
alertmanager | level=info ts=2021-10-30T05:36:48.479Z caller=main.go:225 msg="Starting Alertmanager" version="(version=0.23.0, branch=HEAD, revision=61046b17771a57cfd4c4a51be370ab930a4d7d54)"
alertmanager | level=info ts=2021-10-30T05:36:48.479Z caller=main.go:226 build_context="(go=go1.16.7, user=root@e21a959be8d2, date=20210825-10:48:55)"
alertmanager | level=info ts=2021-10-30T05:36:48.479Z caller=cluster.go:184 component=cluster msg="setting advertise address explicitly" addr=172.19.0.7 port=9094
alertmanager | level=info ts=2021-10-30T05:36:48.480Z caller=cluster.go:671 component=cluster msg="Waiting for gossip to settle..." interval=2s
alertmanager | level=info ts=2021-10-30T05:36:48.529Z caller=coordinator.go:113 component=configuration msg="Loading configuration file" file=/etc/alertmanager/config.yml
alertmanager | level=info ts=2021-10-30T05:36:48.529Z caller=coordinator.go:126 component=configuration msg="Completed loading of configuration file" file=/etc/alertmanager/config.yml
alertmanager | level=info ts=2021-10-30T05:36:48.531Z caller=main.go:518 msg=Listening address=:9093
alertmanager | level=info ts=2021-10-30T05:36:48.531Z caller=tls_config.go:191 msg="TLS is disabled." http2=false
alertmanager | level=info ts=2021-10-30T05:36:50.481Z caller=cluster.go:696 component=cluster msg="gossip not settled" polls=0 before=0 now=1 elapsed=2.001143672s
alertmanager | level=info ts=2021-10-30T05:36:58.482Z caller=cluster.go:688 component=cluster msg="gossip settled; proceeding" elapsed=10.002273404s
...
然后使用浏览器访问 http://10.11.12.186:9093/ 就能看到默认的界面了,并且默认会出现我们之前在 Prometheus 中配置的应用名称 “docker-prometheus”。
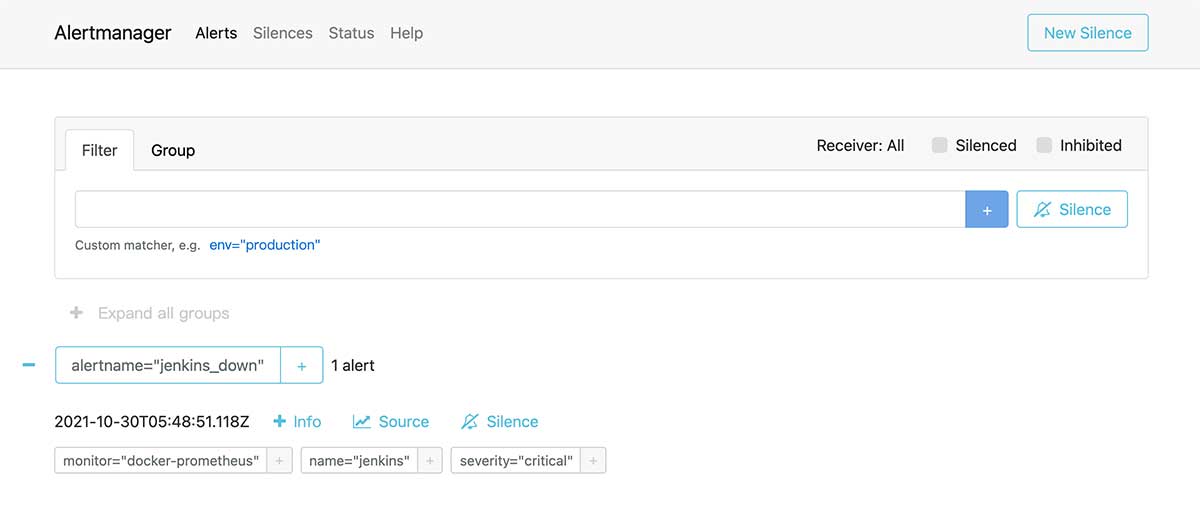
可视化面板:Grafana
将上面的应用和组件部署完毕之后,如果不要求视觉体验,其实使用 Prometheus 默认自带的绘图已经能够定位和说明一些问题了,但是相比较 Grafana 而言,Prometheus 默认的绘图功能相当简陋,无法直观的展示多个指标和趋势,并且有些时候,我们并不单单需要展示单一来源的数据,可能还牵扯到外部网站、应用的数据源。Grafana 就是为此而生的。
还是先来编写容器配置文件:
version: "3"
services:
grafana:
image: grafana/grafana:8.2.2
container_name: grafana
user: "472"
volumes:
- ./data:/data:rw
# 根据自己情况,是否需要持久化面板配置 :)
# - ./dashboards:/etc/grafana/provisioning/dashboards
- ./datasources:/etc/grafana/provisioning/datasources
environment:
- GF_PATHS_DATA=/data
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_USERS_ALLOW_SIGN_UP=false
restart: always
expose:
- 3000
ports:
- 3000:3000
networks:
- monitor
logging:
driver: "json-file"
options:
max-size: "1m"
networks:
monitor:
external: true
上面的配置里声明了我们要将 Grafana 的数据存储在本地相对于容器配置文件的 data 目录中,以方便我们的管理和迁移。此外默认的账号和密码也都暂时指定为了 admin ,实际使用过程中,可以根据自己的需求进行调整。
接下来我们来编写 grafana 具体的应用配置,先来处理“数据源”。
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
orgId: 1
url: http://prometheus:9090
basicAuth: false
isDefault: true
editable: true
因为在相同的容器网络中,所以这里我们可以直接使用配置 prometheus 时,声明的容器名称,作为访问域名。将文件保存为 datasources/datasource.yml 后,便可以使用 docker-compose up -d 启动服务开始进一步的配置了。
使用容器启动 Grafana 的过程中,你可能会遇到容器提示权限不足,而无法启动的问题。通过手动创建数据目录,并参考当前 grafana 容器内部用户信息,赋予权限即可解决这个问题。
mkdir data
chown 472 data
成功运行之后,我们使用浏览器访问 http://monitor.lab.com:3000/ 就能看到久违的登陆界面啦。
使用我们之前配置中声明的账号密码登陆之后,便能够开始配置我们的监控看板啦。这里为了省事,我们可以直接使用网友们在 Grafana 官网共享的模版,并在这些模版的基础上进行进一步调整。(在官方挑选模版时,可以使用关键词搜索并根据下载量等条件进行排序)
想要偷这个懒,我们需要在首页侧边栏选择“Create”->“Import”,先打开导入页面。

我使用 “Docker” 为关键词进行了搜索,这其中有四个下载量比较高的面板:893、1160、179、10619,你可以根据你自己的喜好选择使用。
在成功导入之后,我们就能够直观的看到监控系统的运行状态啦。
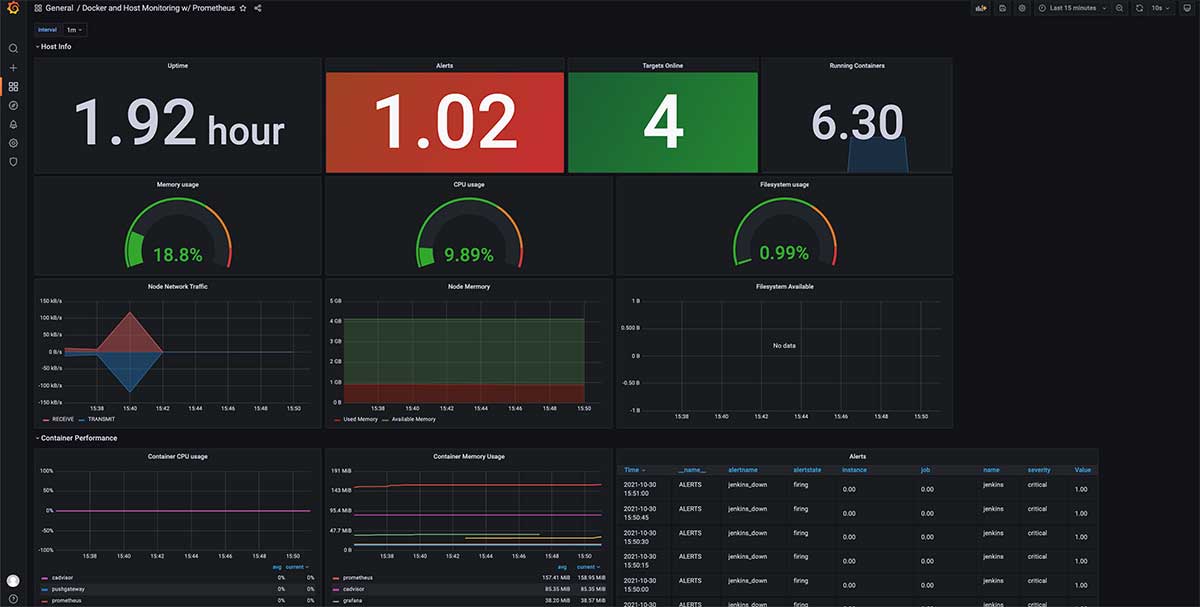
默认面板中功能大概率不能完全满足我们的使用需求,好在每一个小模块都可以根据自己的需求进一步调整,这里的查询语法就是我们在 Prometheus 小节里提到的内置的查询语言,可以翻阅官方文档进行简单学习。
其他:关于系统监控为什么不使用 ESXi / Proxmox VE 默认的监控
有几个原因,虚拟化系统默认监控粒度比较粗,适合判断大概哪里有问题,但是不能够第一时间帮我们进行精准定位;此外,这些监控默认不一定会持久化存储(考虑到存储成本、以及使用价值),比如 ESXi 默认只统计最近一段时间的数据。
最重要的一点,这些监控不能够作为开放的平台应用使用,也就是说监控项目基本都是“死”的,我们想要集成某些应用、某些业务逻辑的监控观测,比较难或者根本做不到。
最后
写到这里,字数应该又超过了多数文章分享平台的字数限制了。好在使用容器的方式,简单快速的搭建一套监控服务也讲的差不多了,相信聪明的你参考文章中的配置模版应该能够快速的添加或者修改数据源、定制适合自己的面板。
余下的实际使用过程中的集成部分,我将在接下来的文章小节中陆续展开,欢迎继续关注。如果在忙起来之前还有时间,我会陆续聊聊如何在混合部署的情况下,进行数据接入,以及相比较 Prometheus 更轻量简单的监控工具。
系列中的下一篇内容,我将聊聊如何搭建共享的网络存储。
–EOF