本文将介绍如何使用 GAN 模型来生成属于你自己的动漫风格的视频,为自己、喜欢的菇凉或者调皮可爱孩子生成一个别具一格的动漫风格的视频。
本文操作难度较低,适合想要试玩了解 GAN 模型的同学。可以同时使用 CPU / GPU (包括 ARM M1)来完成。
写在前面
这阵子在翻阅和学习一些模型相关的内容,当我看到大名鼎鼎的《你的名字》、《秒速五厘米》、《天气之子》等经典作品的导演新海诚,因为一组对比图发出了下面的感叹的时候,我的好奇心一下子就上来了。

图片中新海诚的感叹内容翻译过来的大概意思是:“很有趣,我感觉到了各种可能性。如果这是由美术工作人员提出的,电影将会重拍。笑”
在我看来,能够得到如新海诚这样的大佬翻牌子,或许这类模型值得一玩。于是,我试着用这类模型将我的结婚纪念视频进行了风格转换,发现效果还行啊。

接着,我又针对一些以往的照片试了试这个“滤镜”,发现针对部分照片来说,效果真的很不错。



独乐乐不如众乐乐,如果你也有计划为喜欢的人、或者孩子,甚至是自己做一些卡通风格化的视频/照片留念的话,那么跟着我一起来折腾下本篇内容吧。
本篇将依次介绍两种模型的使用,关于这两个模型的简单介绍,在本文结尾有提到,如果你感兴趣的话,可以跳转阅读。
好了,我们先来进行一些准备工作吧。
准备工作
在开始为我们的视频或者照片“加滤镜”之前,我们需要先进行环境准备。
本篇文章为了更简单一些,就不再在文章中展开如何进行模型的 Docker 镜像封装了,感兴趣的同学可以自行翻阅上篇《使用 Docker 来运行 HuggingFace 海量模型》文章内容,来学习相关内容。
使用 Conda 简化 Python 程序环境准备工作
和上篇文章一样,我推荐使用 Conda 完成基础的程序运行环境的安装。

你可以从Conda 官方网站下载合适的安装程序(安装包比较大,大概 500M左右,需要一些耐心)。
- 如果你是 Mac x86 用户,可以下载 Anaconda3-2022.05-MacOSX-x86_64.sh
- 如果你是 Mac M1 用户,可以下载 Anaconda3-2022.05-MacOSX-arm64.sh
- 如果你是 Linux 用户,可以下载 Anaconda3-2022.05-Linux-x86_64.sh
- 如果你是 Windows 用户,可以下载 Anaconda3-2022.05-Windows-x86_64.exe
接下来,我们先以 Mac 和 Ubuntu 为例,来演示如何完成环境的准备。
从上面的地址下载好 Conda 安装文件之后,一行命令完成程序安装即可。
# 先进行 conda 的安装
bash Anaconda3-2022.05.(你的安装文件名称).sh
如果你在使用 Ubuntu,和我一样,需要经常测试不同的模型和项目,可以在安装完毕之后,执行下面的命令,让 conda shell 环境常驻。
# 在完成安装之后,可以考虑hi
eval "$(~/anaconda3/bin/conda shell.bash hook)"
至于 Mac,我更推荐什么时候使用,什么时候手动激活 conda shell。比如在安装完毕 conda,并初始化好了某一个程序的专用环境之后,我们可以通过执行 conda activate [环境名称] 命令来激活这个环境所需要的 shell。(关于如何初始化环境,请耐心往下看)
国内用户,推荐在使用 Conda 时,先进行软件源配置操作。这样可以减少在下载软件包过程中造成的不必要时间浪费。
编辑 vi ~/.condarc 文件,在其中加入下面的内容(以“清华源”为例):
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- defaults
show_channel_urls: true
当我们完成了 ~/.condarc 的内容修改之后,先重启 Shell,接着使用 conda info 就可以检查软件源是否配置成功了:
(base) soulteary@ubuntu:~# conda info
active environment : base
...
channel URLs : https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/linux-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/noarch
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/linux-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/noarch
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/noarch
https://repo.anaconda.com/pkgs/main/linux-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/r/linux-64
https://repo.anaconda.com/pkgs/r/noarch
...
可以看到,日志输出中包含了我们刚刚填写的“清华源”。
接下来,我们来通过 conda 命令,来快速创建我们所需要的模型应用程序所需要的运行环境:
conda create -n my-anime-video python=3.10
上面的命令执行完毕之后,将会创建一个名为 my-anime-video 的基于 Python 3.10 的基础运行环境;如果你需要其他版本的 Python 来运行自己的模型,可以调整命令中的版本号。
当环境创建完毕之后,我们需要先执行命令,将环境激活(用过 GVM、NVM 的同学应该会很熟悉)。
conda activate my-anime-video
当环境激活之后,我们的 shell 命令行提示的开始处将会出现这个环境名称提示,告诉我们现在正位于这个环境之下:
(my-anime-video) # your shell command here...
当完成环境激活之后,我们同样先来完成软件源的切换(上篇文章有详细介绍,感兴趣可以自行阅读):
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
接着来完成 PyTorch 常用依赖的安装:
pip install torch torchvision torchaudio
最后安装一个用来“偷懒”的工具 Towhee:
pip install towhee
至于这个工具能省多大事,我先卖个关子不提,看到后面你就知道了。
安装 ffmpeg 来处理多媒体素材
如果你只是希望处理图片,那么这部分可以跳过,如果你希望处理的内容包含视频,我们需要借助 ffmpeg 这个工具的力量。
在 macOS 中,我们可以通过 brew 来进行安装:
brew install ffmpeg
在 Linux 环境中,比如 Ubuntu,我们可以通过 apt 来进行安装:
apt install ffmpeg -y
在 ffmpeg 安装就绪之后,我们来针对视频进行处理,将视频转换为待处理的图片。
比如,我们要将当前目录的视频 wedding-video.mp4 按照每秒 25 帧拆解为图片,并将图片保存在当前目录的 images 目录下,可以执行下面的命令:
ffmpeg -i ./wedding-video.mp4 -vf fps=25 images/video%d.png
当命令执行完毕之后,我们将得到满满一个文件夹的图片,它们都将以命令中的 video 为前缀,数字为结尾。我选择的视频文件接近 15 分钟,当转换完毕之后,得到了两万多张图片。
ls images/| wc -l
21628
当上面的准备工作都就绪之后,我们来看看如何使用两种模型来生成属于我们自己的卡通/动漫风格的视频。
先来看看第一个模型:CartoonGAN。
CartoonGAN
关于这个模型,我找到了一个 HuggingFace 上的在线试玩地址:https://huggingface.co/spaces/akiyamasho/AnimeBackgroundGAN。
这个在线工具来自一位日本开发者,在它的另外一个项目 AnimeBackgroundGAN-Shinkai (新海诚风格)中,我们能够找到一个预训练模型(关联项目中还有宫崎骏、细田守、今敏的风格),而在 GitHub 中,我们能够找到这个项目对应的代码仓库 venture-anime/anime-background-gan-hf-space。
在进行上文提到的视频素材(大量图片)处理之前,我们先来试着在本地运行起来一个同款的 Web 工具,来验证模型代码是否能够正确运行。
验证项目模型效果
这个项目可以使用 CPU 或 GPU 运行,如果你手头有 macOS、Ubuntu 的话,可以直接运行。
不过原始项目对于最新版本的 PyTorch 支持有一些问题,使用 GPU 运行会报错,并且不支持指定显卡运行,以及项目依赖有一些问题,所以我做了一个 fork 版本:https://github.com/soulteary/anime-background-gan-hf-space。
我们使用 Git 下载项目,然后切换到项目目录中:
git clone https://github.com/soulteary/anime-background-gan-hf-space.git
cd anime-background-gan-hf-space
在进一步进行之前,我们需要确认已经用 conda 将之前准备的 Python 环境激活,如果你不确定或者还没有进行切换,可以再次执行下面的命令(重复执行没有副作用):
conda activate my-anime-video
在切换到 my-anime-video 这个环境之后,我们使用 Python 启动项目:
python app.py
在命令执行之后(可能需要稍等片刻),我们将得到类似下面的日志:
/Users/soulteary/anaconda3/envs/my-anime-video/lib/python3.10/site-packages/gradio/deprecation.py:40: UserWarning: `optional` parameter is deprecated, and it has no effect
warnings.warn(value)
Running on local URL: http://127.0.0.1:7860/
To create a public link, set `share=True` in `launch()`.
然后打开浏览器,输入上面日志中提示的地址 http://127.0.0.1:7860/,就能够看到一个在线的 Web 工具界面啦。
要进行模型和应用代码验证也很简单,点击左边的图片上传区域,上传一个你想要测试的图片,然后点击“提交”即可。
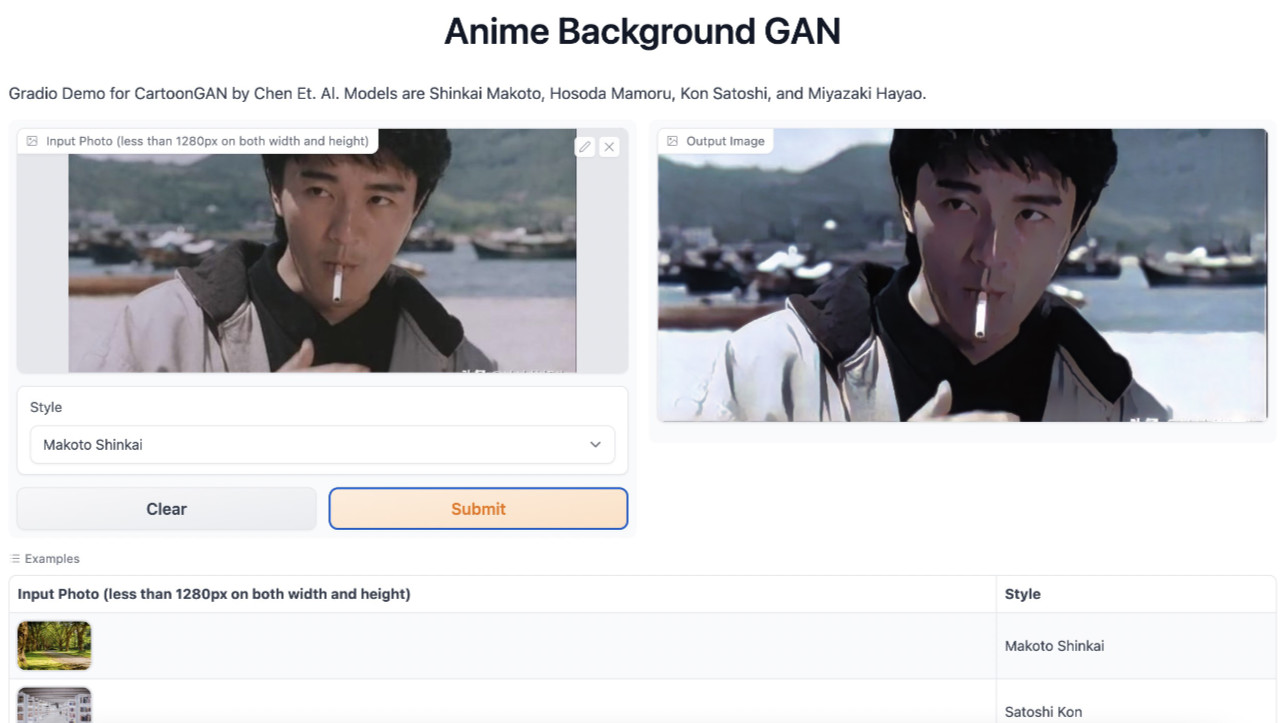
可以看到,一张颇有卡通感的图片出现在了右侧。这里如果使用 CPU 运行,一般需要 3~10s 来处理一张图,如果使用 GPU,则一般需要 1s 左右。
在完成了程序和模型的验证之后,我们来编写批量处理图片的程序。
编写模型调用程序进行批量图片处理
完整程序,我已经上传到了 GitHub https://github.com/soulteary/have-fun-with-AnimeGAN/blob/main/CartoonGAN/app.py 方便大家自取。
原始的项目中,并不支持批量读取图片,并且默认会加载四个模型,比较浪费资源,所以我这里进行了一些功能完善。
import argparse
import glob, os
import time
from pathlib import Path
from PIL import Image
import torch
import numpy as np
import torchvision.transforms as transforms
from torch.autograd import Variable
from network.Transformer import Transformer
from huggingface_hub import hf_hub_download
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def parse_args():
desc = "CartoonGAN CLI by soulteary"
parser = argparse.ArgumentParser(description=desc)
parser.add_argument('--model', type=str, default='Shinkai', help='Shinkai / Hosoda / Miyazaki / Kon')
parser.add_argument('--input', type=str, default='./images', help='images directory')
parser.add_argument('--output', type=str, default='./result/', help='output path')
parser.add_argument('--resize', type=int, default=0,
help='Do you need a program to adjust the image size?')
parser.add_argument('--maxsize', type=int, default=0,
help='your desired image output size')
"""
If you want to resize, you need to specify both --resize and --maxsize
"""
return parser.parse_args()
def prepare_dirs(path):
Path(path).mkdir(parents=True, exist_ok=True)
arg = parse_args()
enable_gpu = torch.cuda.is_available()
if enable_gpu:
# If you have multiple cards,
# you can assign to a specific card, eg: "cuda:0"("cuda") or "cuda:1"
# Use the first card by default: "cuda"
device = torch.device("cuda")
else:
device = "cpu"
def get_model(style):
# Makoto Shinkai
if style == "Shinkai":
MODEL_REPO_SHINKAI = "akiyamasho/AnimeBackgroundGAN-Shinkai"
MODEL_FILE_SHINKAI = "shinkai_makoto.pth"
model_hfhub = hf_hub_download(repo_id=MODEL_REPO_SHINKAI, filename=MODEL_FILE_SHINKAI)
# Mamoru Hosoda
elif style == "Hosoda":
MODEL_REPO_HOSODA = "akiyamasho/AnimeBackgroundGAN-Hosoda"
MODEL_FILE_HOSODA = "hosoda_mamoru.pth"
model_hfhub = hf_hub_download(repo_id=MODEL_REPO_HOSODA, filename=MODEL_FILE_HOSODA)
# Hayao Miyazaki
elif style == "Miyazaki":
MODEL_REPO_MIYAZAKI = "akiyamasho/AnimeBackgroundGAN-Miyazaki"
MODEL_FILE_MIYAZAKI = "miyazaki_hayao.pth"
model_hfhub = hf_hub_download(repo_id=MODEL_REPO_MIYAZAKI, filename=MODEL_FILE_MIYAZAKI)
# Satoshi Kon
elif style == "Kon":
MODEL_REPO_KON = "akiyamasho/AnimeBackgroundGAN-Kon"
MODEL_FILE_KON = "kon_satoshi.pth"
model_hfhub = hf_hub_download(repo_id=MODEL_REPO_KON, filename=MODEL_FILE_KON)
model = Transformer()
model.load_state_dict(torch.load(model_hfhub, device))
if enable_gpu:
model = model.to(device)
model.eval()
return model
def inference(img, model):
# load image
input_image = img.convert("RGB")
input_image = np.asarray(input_image)
# RGB -> BGR
input_image = input_image[:, :, [2, 1, 0]]
input_image = transforms.ToTensor()(input_image).unsqueeze(0)
# preprocess, (-1, 1)
input_image = -1 + 2 * input_image
if enable_gpu:
logger.info(f"CUDA found. Using GPU.")
# Allows to specify a card for calculation
input_image = Variable(input_image).to(device)
else:
logger.info(f"CUDA not found. Using CPU.")
input_image = Variable(input_image).float()
# forward
output_image = model(input_image)
output_image = output_image[0]
# BGR -> RGB
output_image = output_image[[2, 1, 0], :, :]
output_image = output_image.data.cpu().float() * 0.5 + 0.5
return transforms.ToPILImage()(output_image)
prepare_dirs(arg.output)
model = get_model(arg.model)
enable_resize = False
max_dimensions = -1
if arg.maxsize > 0:
max_dimensions = arg.maxsize
if arg.resize :
enable_resize = True
globPattern = arg.input + "/*.png"
for filePath in glob.glob(globPattern):
basename = os.path.basename(filePath)
with Image.open(filePath) as img:
if(enable_resize):
img.thumbnail((max_dimensions, max_dimensions), Image.Resampling.LANCZOS)
start_time = time.time()
inference(img, model).save(arg.output + "/" + basename, "PNG")
print("--- %s seconds ---" % (time.time() - start_time))
上面这段一百来行的程序大概做了这么几件事,会根据传递参数来动态的载入必要的模型,而不是所有的模型。默认情况下,它会读取当前目录 images 子目录的所有图片,并依次调用 CPU / GPU 来进行图片处理,并将处理结果保存在 result 子目录中。如果你希望对输出图片进行尺寸调整,可以传递参数来做限制。
我们来试着运行下这个程序:
python app.py --model=Shinkai
当命令开始执行后,我们就能够批量处理视频图片啦,如果不出意外,你将会看到类似下面的日志:
...
--- 1.5597078800201416 seconds ---
INFO:__main__:Image Height: 1080, Image Width: 1920
--- 0.44031572341918945 seconds ---
INFO:__main__:Image Height: 1080, Image Width: 1920
--- 1.5004260540008545 seconds ---
INFO:__main__:Image Height: 1080, Image Width: 1920
--- 1.510758876800537 seconds ---
INFO:__main__:Image Height: 1080, Image Width: 1920
--- 1.362170696258545 seconds ---
INFO:__main__:Image Height: 1080, Image Width: 1920
...
这里需要处理的时间可能会比较久,如果我们有 GPU 会极大的提升速度,或者适当调整输出图片的大小,也能够在使用 CPU 进行渲染的情况下,得到比较快的处理速度。
当程序运行结束之后,我们在 result 目录中,就能够得到经过 AI 模型处理的图片内容了,这时我们只要再次使用 ffmpeg 将图片转换为视频就好啦:
ffmpeg -f image2 -r 25 -i result/video%d.jpg -vcodec libx264 -crf 18 -pix_fmt yuv420p result.mp4
接下来,我们先来聊聊如何使用 GPU 进行提速,然后再来看看有没有更通用的、低成本的提速方案。
使用 GPU 进行模型执行提速
如果你没有 GPU,想用最小成本来玩,那么可以直接阅读下一小节内容。
言归正传,假设我们要处理上万甚至十万张图片,最好的方式便是使用 GPU 进行数据处理。考虑到当前一块能高效跑 AI 模型的具备大显存的显卡至少一万起步,我更推荐使用按量付费的云主机,大概每小时 10~20 块钱,跑个个把小时,就能拿到你想要的结果啦。我个人测试下来,几个云厂商带有显卡的主机都差不多,大家根据自己情况和喜欢的方式选择就行,如果是学生身份,或许有些平台还能有教育折扣。
为了能够相对快速的得到结果,我选择了一台双卡云主机,在不做程序的深度优化前,能够直接让数据处理时间减半。
想要让两张显卡各处理一半的数据,我们可以选择修改上面的程序,也可以用 Linux Shell 把数据直接分为两堆儿。作为一个懒人,我们选择后者。(如果你只有一张卡,可以跳过这个步骤)
先来确认当前待处理的数据总量,有两万多张图片。
ls images/| wc -l
21628
接着使用组合命令,将一半的图片挪到新创建的文件夹中:
mkdir images2
ls | sort | head -10814 | xargs -I {} mv {} images2/
在准备完数据之后,我们同样需要对程序做一点小的调整,让程序分别使用两张不同的显卡设备,我们可以选择像程序读取输入输出文件夹使用参数相同的方式,来让用户指定显卡设备;也可以选择更简单的方式,将上面的程序复制一份,调整原来的程序和新程序中要调用的显卡设备名称,比如,将 device = torch.device("cuda") 调整为 device = torch.device("cuda:0") 和 device = torch.device("cuda:1")。
当完成上述调整和准备之后,分别使用 python 执行两个程序即可:python app1.py、python app2.py。如果你不能保证你通过 SSH 连接到服务器的会话稳定,那么可以试试使用 screen、tmux 这类工具。
程序开始运行之后,接下来就是漫长的等待,在处理过程中,我们可以使用 nvidia-smi 查看显卡状态,可以看到如果这台“电脑”搁家里,应该是蛮费电的,而且大概率会很吵。
nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.102.04 Driver Version: 450.102.04 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:08.0 Off | 0 |
| N/A 54C P0 263W / 300W | 25365MiB / 32510MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla V100-SXM2... On | 00000000:00:09.0 Off | 0 |
| N/A 55C P0 265W / 300W | 25365MiB / 32510MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 61933 C python 25363MiB |
| 1 N/A N/A 62081 C python 25363MiB |
+-----------------------------------------------------------------------------+
当程序处理完所有图片之后,会自动退出。这个时候,我们可以再次使用 ffmpeg 将图片还原为视频:
time ffmpeg -f image2 -r 25 -i result/video%d.png -vcodec libx264 -crf 18 -pix_fmt yuv420p result.mp4
当程序运行完毕,我们将看到类似下面的日志:
Output #0, mp4, to 'result.mp4':
Metadata:
encoder : Lavf58.29.100
Stream #0:0: Video: h264 (libx264) (avc1 / 0x31637661), yuv420p, 1920x1080, q=-1--1, 25 fps, 12800 tbn, 25 tbc
Metadata:
encoder : Lavc58.54.100 libx264
Side data:
cpb: bitrate max/min/avg: 0/0/0 buffer size: 0 vbv_delay: -1
frame=21628 fps= 75 q=-1.0 Lsize= 1135449kB time=00:14:25.00 bitrate=10753.3kbits/s speed=2.99x
video:1135185kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.023257%
[libx264 @ 0x55779059b380] frame I:253 Avg QP:15.48 size:194386
[libx264 @ 0x55779059b380] frame P:6147 Avg QP:17.74 size: 95962
[libx264 @ 0x55779059b380] frame B:15228 Avg QP:20.43 size: 34369
[libx264 @ 0x55779059b380] consecutive B-frames: 4.7% 2.9% 4.0% 88.4%
[libx264 @ 0x55779059b380] mb I I16..4: 16.0% 47.1% 36.9%
[libx264 @ 0x55779059b380] mb P I16..4: 7.9% 13.9% 6.1% P16..4: 31.2% 18.5% 9.3% 0.0% 0.0% skip:13.0%
[libx264 @ 0x55779059b380] mb B I16..4: 1.6% 1.6% 0.5% B16..8: 34.3% 9.6% 2.7% direct:11.8% skip:37.9% L0:42.2% L1:42.3% BI:15.5%
[libx264 @ 0x55779059b380] 8x8 transform intra:48.1% inter:59.5%
[libx264 @ 0x55779059b380] coded y,uvDC,uvAC intra: 47.2% 66.3% 35.9% inter: 30.7% 35.6% 1.6%
[libx264 @ 0x55779059b380] i16 v,h,dc,p: 39% 32% 6% 23%
[libx264 @ 0x55779059b380] i8 v,h,dc,ddl,ddr,vr,hd,vl,hu: 27% 20% 26% 4% 5% 4% 5% 4% 5%
[libx264 @ 0x55779059b380] i4 v,h,dc,ddl,ddr,vr,hd,vl,hu: 33% 20% 16% 5% 6% 6% 5% 5% 4%
[libx264 @ 0x55779059b380] i8c dc,h,v,p: 50% 21% 21% 8%
[libx264 @ 0x55779059b380] Weighted P-Frames: Y:24.2% UV:17.1%
[libx264 @ 0x55779059b380] ref P L0: 49.1% 14.5% 22.1% 12.4% 1.9%
[libx264 @ 0x55779059b380] ref B L0: 81.3% 14.0% 4.7%
[libx264 @ 0x55779059b380] ref B L1: 93.6% 6.4%
[libx264 @ 0x55779059b380] kb/s:10749.30
real 4m49.667s
user 78m36.497s
sys 0m44.806s
当我打开处理完毕的视频,就个人观感而言,光线充足的场景下,模型的发挥还是比较好的。这里由于上传图片压缩,效果没有本地看到的惊艳,感兴趣的同学不妨试试。

或许你想知道,有没有什么不用 GPU 也能进行一些加速效果的方案呢?答案是有的。
使用并行计算和流式处理来加速图片处理
Python 3 支持 concurrent API,来做并行计算。不过处理并发计算,一般还需要折腾队列,涉及到多线程调度,涉及到流式 IO 等等一坨麻烦事。而且并发代码调试也比较恶心,尤其是在 Python 中…(个人观点)
还记得我在上文中曾经 pip install 的 towhee 么,这个软件包里包含了一些快捷的工具方法,能够简化上面一系列麻烦事情,让我们处理相同的事情,花更少的代价,因为很多时候,一些基本的带有复杂度的麻烦事,应该交给基础工具来解决,而不是都由开发者吭哧吭哧的填。
我们以上文中一百多行的模型应用代码举例,如果换用 Towhee 做一个“平替”程序,那么可以这样来实现:
import towhee
towhee.glob('./*.png') \
.image_decode() \
.img2img_translation.cartoongan(model_name = 'Shikai') \
.save_image(dir='./result')
.to_list()
几行代码,就完成了核心逻辑:批量读取图片、将图片进行 RGB 编码转换,然后将图片数据传递给模型进行处理,最后进行模型计算结果保存到某个文件夹里。
接下来,我们再对上面的代码进行一些调整,来完成上面提到的麻烦事,并行计算。其实需要的改动很少,只需要我们在“处理图片编码转换”之前,加上一行 .set_parallel(5) 来告诉程序,我们要使用多个线程来搞事情就行啦。
当程序运行起来的时候,就会默认调用 5 个并发来执行计算,所以即使没有 GPU,只使用 CPU 的情况下,我们也能够获取更高的执行效率。
import towhee
towhee.glob('./*.png') \
.set_parallel(5) \
.image_decode() \
.img2img_translation.cartoongan(model_name = 'Shikai') \
.save_image(dir='./result')
.to_list()
在玩 Towhee 的过程中,我也遇到了一些小问题。比如 Towhee 这个工具的设计初衷是为了科学计算,所以像是保存图片、折腾视频文件都不是它的主业,默认情况下,它会以 UUID 的形式来保存处理后的图片。
为了能够让图片结果为我们所用,输出的图片能够按照原始文件名称进行存储,让模型处理完的结果能够“还原成视频”。我特别向它的开源仓库提交了一个 PR (#1293)来解决这个问题。
当然,我们也需要对上面的几行代码做一些额外的调整,添加一些参数:
import towhee
towhee.glob['path']("./*.png") \
.set_parallel(5) \
.image_decode['path','img']() \
.img2img_translation.cartoongan['img', 'img_new'](model_name = "Shikai") \
.save_image[('img_new','path'), 'new_path'](dir="./result") \
.to_list()
不过,截止本文发布的时候,包含我的 PR 的主干版本,还没有被正式发布,所以暂时还需要安装 Python PyPI 每日构建的开发版的软件包来使用这个功能。
pip install -i https://test.pypi.org/simple/ towhee==0.6.2.dev48
如果大家觉得这个偷懒的玩法还不错,可以代我去官方开源仓库去提 Issue,催催维护团队更新版本。
那么,为啥作为 Towhee 用户的我不去催呢?其实是因为不好意思。为啥不好意思呢?你接着看下去就知道啦。
AnimeGAN
在聊完 CartoonGAN 之后,我们来试试另外一个模型:AnimeGAN。目前模型有三个版本,除了第三个版本外,都是免费使用的开源项目。
为了方便演示以及一些特别的原因(文末详述),我这里选择开源且较为稳定的第二个版本。
在开始折腾之前,同样也可以先试试它的在线试玩的 Demo:https://huggingface.co/spaces/akhaliq/AnimeGANv2。
还是先来进行本地项目验证,来验证模型代码是否能够正确运行。
验证项目模型效果
考虑到文章篇幅和工程师“美德”(偷懒),我们就不再折腾冗长的模型调用程序代码了,我选择继续用 Python 版 “jQuery” 来 “Write Less, Do More”:
import towhee
arg = parse_args()
towhee.glob['path']("./*.png") \
.set_parallel(5) \
.image_decode['path', 'img']() \
.img2img_translation.animegan['img', 'new_img'](model_name ="Shinkai") \
.save_image[('new_img', 'path'), 'new_path'](dir="./result", format="png") \
.to_list()
逻辑和上文中调用 CartoonGAN 一样,唯一的差别是使用了 animegan 的模型。
我们将上面的代码保存为 lazy.py,然后从网上随便找些图片放在程序所在的目录,执行 python lazy.py,稍等片刻就能够在程序同级目录发现一个新的名为 result 的文件夹,里面放着的就是我们用模型处理过的图片啦。
相关代码,我已经上传到了 https://github.com/soulteary/have-fun-with-AnimeGAN/blob/main/AnimeGAN/lazy.py 感兴趣的同学可以自取。
在验证完毕模型效果之后,我们同样可以使用这个模型来生成一段卡通风格的视频。
虽然上文中使用 ffmpeg 拼合视频的效率非常高,但是毕竟要执行额外的两条命令,有没有什么办法可以进一步偷懒呢?答案显然是有的。
编写模型调用程序进行视频处理
不知道是否还有同学记得,在上篇文章中我提到的 Towhee 核心开发者之一的 @侯杰 同学。在我死缠烂打之下,他帮我这个 Python 菜鸟,搞了一个 read_video 方法。
所以,上文中需要先用 ffmpeg 把视频转换为图片,然后在模型处理之后,再把图片拼合成视频的繁琐操作,就可以被几行代码替代掉啦!相比较之前的玩法,新的代码行数瞬间缩短到了五行左右(算空行也就六行),节约了原本需要写的 80% 的代码行数。
import towhee
towhee.read_video("./video.mp4") \
.set_parallel(5) \
.img2img_translation.animegan['img', 'new_img'](model_name = 'Skinkai') \
.to_video('./result.mp4', 'x264', 15)
上面这几行代码执行下来,分别会自动套用模型处理视频的每一帧内容,然后将模型处理结果重新编码为每秒 15 帧的视频文件。实际使用的时候,你可以根据自己的需求进行码率调整。
为了方便你的使用,我也将代码上传到了 GitHub,需要的同学可以自取。
针对视频文件进行快速预览
相比较图片内容处理,相同分辨率的视频的数据量其实会大不少。
所以如果我们想对视频进行一个快速效果预览,可以考虑在代码中添加一个尺寸调整的功能,将每一帧需要处理的图片尺寸进行缩放,减少计算量。
一如上文中的偷懒原则,想要搞定这个“需求”的方法也很简单,只需要加一行 image_resize 在合适的位置:
import towhee
towhee.read_video("./video.mp4") \
.set_parallel(5) \
.image_resize(fx=0.2, fy=0.2) \
.img2img_translation.animegan['img', 'new_img'](model_name = 'Skinkai') \
.to_video('./result.mp4', 'x264', 15)
这部分的代码,我依旧上传到了 GitHub,希望对你有帮助。
其他
好啦!到这里为止,我已经讲完了:
- 如何准备一个快速上手的 Python 环境
- 如何快速上手使用 CartoonGAN、AnimeGAN 两个模型;
- 如何用这两个模型处理图片或者视频;
- 如何使用 Python 模型里的 “jQuery”:Towhee 来偷懒,少写代码多搞事情。
- 如何进行 GitHub 上“野生”模型项目的基本调优和封装
接下来,我们来简单聊聊文章开头提到的模型。
关于 AnimeGAN 和 CartoonGAN
关于使用 GAN(生成对抗网络) 模型来对图片做动漫卡通风格化处理,就国内而言,目前有两个知名度较高的国产项目。
一个是来自清华大学团队在 2018 年公开的 CartoonGAN,该模型的论文中选 CVPR 2018,在 GitHub 上有 700 余颗星星。另外一个是来自湖北科技大学,在 2019 年公开的 AnimeGAN,该模型至今已迭代了三个版本(前两个版本开源),并在 GitHub 上累计收获了近 8 千颗星星。
关于两个模型和论文,媒体都曾进行过报道宣传:《实景照片秒变新海诚风格漫画:清华大学提出CartoonGAN》、《强烈安利试试这个!效果爆炸的漫画变身AI,火到服务器几度挤爆》,其中 AnimeGAN 处理的图片结果,甚至得到了新海诚的感叹。
我个人使用下来,CartoonGAN 和 AnimeGAN 各有优势和不足,至于模型效果,以及各自适合哪些场景。相信聪明的读者们,可以通过本文提到的方式,和自己的实践来找到答案。
这两个项目的开源仓库地址:
- https://github.com/mnicnc404/CartoonGan-tensorflow / 模型下载:http://cg.cs.tsinghua.edu.cn/people/~Yongjin/CartoonGAN-Models.rar
- https://github.com/TachibanaYoshino/AnimeGAN
- https://github.com/TachibanaYoshino/AnimeGANv2
目前,因为 AnimeGAN v3 正在进行商业化尝试,并且是闭源发布,为了不对作者造成影响,这里就先不做相关模型封装和尝试啦。
开源不易,模型项目开源尤为不易,能够做商业化转型更是不易,需要社区、需要国人同胞的支持和鼓励。只有不断支持和反馈开源生态,国内的开源生态才有可能向好的方向变化,而当生态变好之时,我们这些从业者定然能够从中获得更多的益处。
最后
在一周前,我在朋友圈晒过使用模型来处理之前结婚的纪念视频,有不少朋友点赞和表示好奇如何“折腾自己的照片或视频”,当时承诺大家会出一篇教程,趁着端午节,赶出了这篇内容,希望大家玩的愉快。
最后,再次感谢被我死缠烂打之下添加了新功能的 @侯杰 同学,同样感谢为我的 PR 提供了大量建议,帮助我把模型传递到 Towhee Hub,解决国内下载模型缓慢问题的、来自彩云之南的程序媛 @室余 妹纸。
–EOF