补一篇内容,聊聊处理五大互联网注册机构提供的 IP 数据中的小坑。
写在前面
上个月,我写了一篇文章《正确处理全球五大互联网注册机构的 IP 数据》,来介绍如何处理全球五大互联网注册机构所提供的 IP 数据。
在实践的过程中,有一位读者在 GitHub 项目 Home-Network-Note 的 issue 里反馈了一个问题,有一部分国家和地区的 IP 处理结果是错误的:
109.94.112.0/20.1926
109.95.136.0/21.6781
129.181.0.0/13.6781
130.248.58.0/21.415
130.248.68.0/18.6781
134.98.184.0/17.8301
由于历史原因,互联网注册机构 IP 分配和管理是先松后紧的,最初看似海量的 IP,分配到最后变成了稀缺资源,为了避免 IP 分配浪费,在分配后期的时候,有一些 IP 段中的可用地址数量没有严格的按照 2 的指数来进行分配。这也是为什么,只有一部分国家和地区会出现这个问题。
举一个实际的例子(瑞士的一条分配记录):
ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6
这个地址分配描述中,是注册管理机构,为瑞士( “海尔维地亚联邦”Confoederatio Helvetica )分配了从 91.216.83.0 开始的 768 个 IPv4 地址。然而在 RIPE NCC 的文档中,我们可以看到并没有哪一个掩码对应的数量是 768,最接近的掩码是 /23(512)和 /22(1k)。
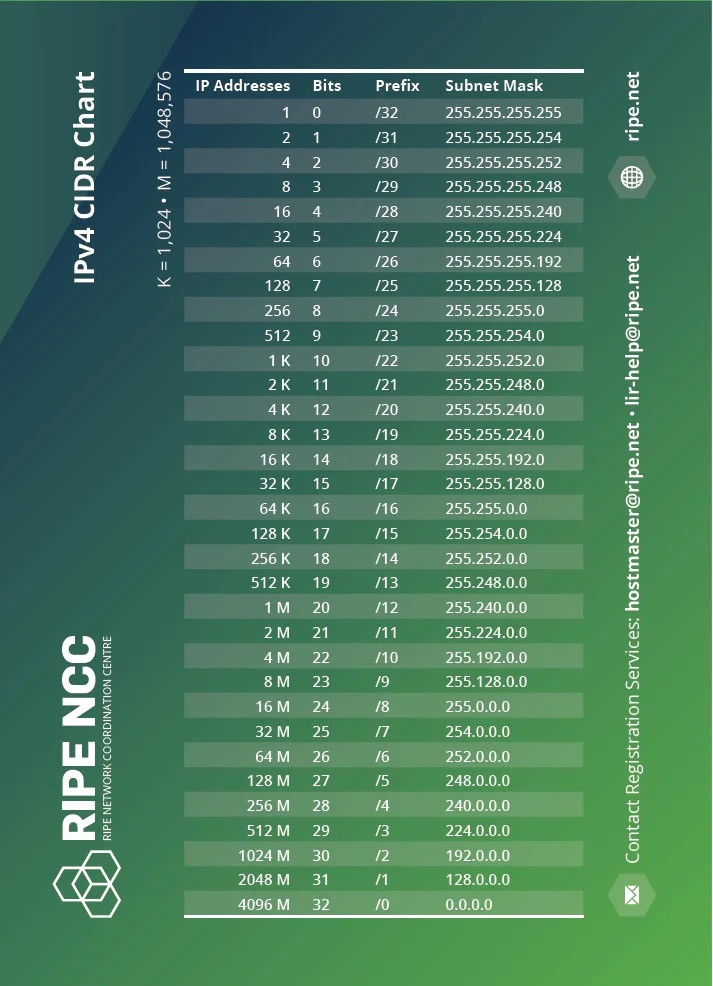
所以,当我们使用上一篇文章中提到的 32-log($5)/log(2) 的方式进行计算的话,将会得到下面的包含小数的错误结果:
91.216.83.0/22.415
解决这个问题并不难,如果一个 CIDR 不能够描述某个 IP 段,那么我们用两个(多个)就好。
比如,虽然没有能够直接表示 768 个 IP 的 CIDR,但是我们可以使用能够表示 256 个 IP 的 CIDR 和 能够表示 512 个 IP 的 CIDR 来完成我们的诉求。
在上一篇文章中,我们使用 bash 和 awk 来完成数据的计算和处理,但是如果想完成上文中的需求,我们会涉及诸如:IP 地址到数值的转换计算、数值到 IP 地址的转换、关于掩码的计算,以及相关数值的校验、程序的异常处理等逻辑。
为了更简单的解决战斗,我们可以用 Golang 来完成处理程序。关于如搭建可维护的 Golang 开发环境,可以阅读之前的文章,这里就不再赘述啦。
设计 IP 数据处理程序
接下来,我们还是使用上文中“搞事情”的数据为例:
ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6
来看看如何设计一个简单、高效的程序,来正确处理这些 IP 数据。
为了方便我的读者偷懒,完整的程序,我已经上传到了 GitHub,有需要可以自取。
实现通用数据转换逻辑
为了相对高性能的完成数据处理,我们需要先定义两个函数,来解决 IP 字符串和 IP 数值之间的来回转换。
好在 Golang 中内置了不少方便的计算函数,实现它们只需要不到二十行代码:
func ipToValue(ipAddr string) (uint32, error) {
ip := net.ParseIP(ipAddr)
if ip == nil {
return 0, errors.New("Malformed IP address")
}
ip = ip.To4()
if ip == nil {
return 0, errors.New("Malformed IP address")
}
return binary.BigEndian.Uint32(ip), nil
}
func valueToIP(val uint32) net.IP {
bytes := make([]byte, 4)
binary.BigEndian.PutUint32(bytes, val)
ip := net.IP(bytes)
return ip
}
获取 IP 地址段的起止点
想要获取 IP 地址段的“起止点”,我们需要先将原始数据中的第4个(IP起始地址)和第5个(IP个数)字段取出,然后将起始 IP 地址转换为数值,将两个字段数据进行相加,得到这个 IP 地址段的“起止点”:
func getRangeEndpointWithLine(line string) (ipStart string, ipEnd string, err error) {
data := strings.Split(line, "|")
if len(data) < 4 {
return "", "", errors.New("Malformed data format.")
}
count, err := strconv.Atoi(data[4])
if err != nil {
return "", "", errors.New("The text contains an invalid number of IPs.")
}
ipStart = data[3]
ipStartValue, err := ipToValue(ipStart)
if err != nil {
return "", "", err
}
ipEndValue := ipStartValue + uint32(count)
ipEnd = valueToIP(ipEndValue).String()
return ipStart, ipEnd, nil
}
我们可以写一段简单的程序,来进行程序调用:
const src = "ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6"
fmt.Println(src)
ipStart, ipEnd, err := getRangeEndpointWithLine(src)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(fmt.Sprintf("[IP Start-End] %s - %s", ipStart, ipEnd))
运行这段代码,我们可以得到和下面一致的结果:
ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6
[IP Start-End] 91.216.83.0 - 91.216.86.0
枚举 IP 地址段所有地址
当我们得到了 IP 地址段的开始地址和结束地址之后,可以根据这个范围,来计算所有地址的 CIDR 地址啦:
func getCidrRangeList(ipStart string, ipEnd string) ([]string, error) {
ipStartValue, err := ipToValue(ipStart)
if err != nil {
return nil, err
}
ipEndValue, err := ipToValue(ipEnd)
if err != nil {
return nil, err
}
if ipEndValue != 0 {
ipEndValue--
}
cidr := getCidrByRangeEndpoint(ipStartValue, ipEndValue)
return cidr, nil
}
因为在上一小节中,我们使用 IP 地址的方式,来展示过程中的结果,所以这里多了一次“IP地址”到数值的转化,在最终版本的程序中,我们可以将这一步进行简化。此处的核心计算逻辑如下:
func getCidrByRangeEndpoint(start, end uint32) []string {
if start > end {
return nil
}
// use uint64 to prevent overflow
ip := int64(start)
tail := int64(0)
cidr := make([]string, 0)
// decrease mask bit
for {
// count number of tailing zero bits
for ; tail < 32; tail++ {
if (ip>>(tail+1))<<(tail+1) != ip {
break
}
}
if ip+(1<<tail)-1 > int64(end) {
break
}
cidr = append(cidr, fmt.Sprintf("%s/%d", valueToIP(uint32(ip)).String(), 32-tail))
ip += 1 << tail
}
// increase mask bit
for {
for ; tail >= 0; tail-- {
if ip+(1<<tail)-1 <= int64(end) {
break
}
}
if tail < 0 {
break
}
cidr = append(cidr, fmt.Sprintf("%s/%d", valueToIP(uint32(ip)).String(), 32-tail))
ip += 1 << tail
if ip-1 == int64(end) {
break
}
}
return cidr
}
执行上面的程序之后,将会遍历 IP 区间内的所有地址,以及尝试使用不同的掩码来判断是否能够包含该 IP。
结合上一小节,我们搞定调用程序:
cidrs, err := getCidrRangeList(ipStart, ipEnd)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(cidrs)
在程序执行完毕,我们将得到和下面一致的结果:
[91.216.83.0/24 91.216.84.0/23]
至此,我们已经完成了 IP 处理程序的核心逻辑。
编写入口函数
我们将上面的“调用程序”的片段组合在一起,可以得到一个简单的入口函数:
func main() {
const src = "ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6"
fmt.Println(src)
ipStart, ipEnd, err := getRangeEndpointWithLine(src)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(fmt.Sprintf("[IP Start-End] %s - %s", ipStart, ipEnd))
cidrs, err := getCidrRangeList(ipStart, ipEnd)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(cidrs)
}
将上面的程序组合到一起,保存为 main.go,接着执行 go run main.go,不出意外,我们将得到类似下面的执行结果:
ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6
[IP Start-End] 91.216.83.0 - 91.216.86.0
[91.216.83.0/24 91.216.84.0/23]
但是,这样的程序并不适合使用,在上一篇文章中,通过使用 Linux Pipeline 的方式来组合调用程序,可以对数据进行高效处理。所以,接下来,我们就针对上面的程序进行一些“简单”的调整吧:
func main() {
fi, err := os.Stdin.Stat()
if err != nil {
panic(err)
}
if fi.Mode()&os.ModeNamedPipe == 0 {
fmt.Println("Need to use linux shell pipe method to use")
return
}
r := bufio.NewReader(os.Stdin)
for {
line, _, err := r.ReadLine()
if err == io.EOF {
break
}
ipStart, ipEnd, err := getRangeEndpointWithLine(string(line))
if err == nil {
cidrs, err := getCidrRangeList(ipStart, ipEnd)
if err == nil {
for _, cidr := range cidrs {
fmt.Println(cidr)
}
}
}
}
}
在上面的程序中,我们限定了这个程序只能和 Linux Shell Pipe 组合使用,在接收到 Linux Pipeline 源源不断的数据之后,会根据换行符拆分数据,然后喂给上文中我们实现的 CIDR 计算函数,并将计算结果进行输出。
根据上一篇文章,我们不难得到包含了各种区域的 IP 数据文件,假设我们将数据文件名称保存为 ip.txt,接下来只需要执行 cat ip.txt | go run main.go ,就能够看到正确的数据处理结果啦:
...
195.85.233.0/24
195.130.196.0/24
195.138.217.0/24
195.144.22.0/24
195.184.76.0/23
195.189.244.0/23
195.191.230.0/23
195.206.242.0/23
195.211.164.0/22
195.216.248.0/24
195.226.211.0/24
195.226.216.0/24
195.242.146.0/23
195.248.81.0/24
195.254.164.0/23
212.6.36.0/24
194.36.0.0/24
调整流式处理函数
虽然上面的程序已经实现了我们所需要的功能,不过,为了确保我们的核心计算逻辑都是正确的。最好还是补充一些测试代码,但如果保持上文中的 main 函数的写法,后续编写测试逻辑将会十分麻烦。
所以,我们还需要针对上面的程序进行一些简单的调整:
func processPipe(src *os.File, dest *os.File, testMode bool) {
fi, err := src.Stat()
if err != nil {
panic(err)
}
if !testMode {
if fi.Mode()&os.ModeNamedPipe == 0 {
fmt.Println("Need to use linux shell pipe method to use")
return
}
}
r := bufio.NewReader(src)
for {
line, _, err := r.ReadLine()
if err == io.EOF {
break
}
ipStart, ipEnd, err := getRangeEndpointWithLine(string(line))
if err == nil {
cidrs, err := getCidrRangeList(ipStart, ipEnd)
if err == nil {
for _, cidr := range cidrs {
fmt.Fprint(dest, fmt.Sprintf("%s\n", cidr))
}
}
}
}
}
func main() {
processPipe(os.Stdin, os.Stdout, false)
}
在完成程序对于流式处理逻辑和入口函数的拆分之后,我们就可以开始编写测试程序,来进一步验证程序的正确性啦。
验证程序
相比较程序设计,单元测试比较枯燥无味,这里直接给出实现代码:
package main
import (
"bytes"
"errors"
"fmt"
"io/ioutil"
"math"
"os"
"strconv"
"strings"
"testing"
)
func TestIpToValue(t *testing.T) {
_, err := ipToValue("1.1.1")
if err == nil {
t.Fatal("program does not catch errors")
}
_, err = ipToValue("2001:0db8:0000:0000:0000:ff00:0042:8329")
if err == nil {
t.Fatal("program does not catch errors")
}
}
func TestGetRangeEndpointWithLine(t *testing.T) {
const example1 = "ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6"
start, end, err := getRangeEndpointWithLine(example1)
if err != nil {
t.Fatal("program execution error")
}
if start != "91.216.83.0" || end != "91.216.86.0" {
t.Fatal("Calculation result is wrong")
}
_, _, err = getRangeEndpointWithLine("")
if err == nil {
t.Fatal("program does not catch errors")
}
const example2 = "ripencc|CH|ipv4|91.a.b.c|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6"
_, _, err = getRangeEndpointWithLine(example2)
if err == nil {
t.Fatal("program does not catch errors")
}
const example3 = "ripencc|CH|ipv4|1.2.3.4|aaa|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6"
_, _, err = getRangeEndpointWithLine(example3)
if err == nil {
t.Fatal("program does not catch errors")
}
}
func TestGetCidrByRangeEndpoint(t *testing.T) {
start, _ := ipToValue("91.216.83.0")
end, _ := ipToValue("91.216.86.0")
val := getCidrByRangeEndpoint(start, end)
if val == nil {
t.Fatal("program does not catch errors")
}
start, _ = ipToValue("91.216.87.0")
end, _ = ipToValue("91.216.86.0")
val = getCidrByRangeEndpoint(start, end)
if val != nil {
t.Fatal("program does not catch errors")
}
}
func TestGetCidrRangeList(t *testing.T) {
result, err := getCidrRangeList("91.216.83.0", "91.216.86.0")
if err != nil {
t.Fatal("program execution error")
}
if len(result) != 2 {
t.Fatal("program execution error")
}
if result[0] != "91.216.83.0/24" || result[1] != "91.216.84.0/23" {
t.Fatal("program execution error")
}
_, err = getCidrRangeList("0.1.2.a", "1.1.1.1")
if err == nil {
t.Fatal("program does not catch errors")
}
_, err = getCidrRangeList("1.1.1.1", "1.1.b")
if err == nil {
t.Fatal("program does not catch errors")
}
}
func getRangeListByCidr(cidr string) (result []string, err error) {
maskAndIP := strings.Split(cidr, "/")
octets := make([]int, 4)
for index, octet := range strings.Split(maskAndIP[0], ".") {
octets[index], err = strconv.Atoi(octet)
if err != nil {
return nil, err
}
if octets[index] < 0 {
return nil, errors.New("[ERROR] " + octet + " is an invalid octet.")
}
}
if len(octets) < 4 {
return nil, errors.New("[ERROR] CIDR range must include 4 octets.")
}
maskDigit, err := strconv.Atoi(maskAndIP[1])
if err != nil {
return nil, err
}
if maskDigit < 16 || maskDigit > 32 {
return nil, errors.New("[ERROR] Invalid mask => " + maskAndIP[1] + ".")
}
numberOfIps := int(math.Pow(2, float64(32-maskDigit)))
for index := 0; index < numberOfIps; index++ {
if octets[0] > 255 {
return nil, errors.New("[ERROR] Invalid address/mask specified: leftmost octet would be greater than 255.")
}
result = append(result, fmt.Sprintf("%d.%d.%d.%d", octets[0], octets[1], octets[2], octets[3]))
octets[3]++
if octets[3] > 255 {
octets[2]++
octets[3] = 0
}
if octets[2] > 255 {
octets[1]++
octets[2] = 0
}
if octets[1] > 255 {
octets[0]++
octets[1] = 0
}
}
return result, nil
}
func TestExpendCIDR(t *testing.T) {
cidrs, _ := getCidrRangeList("91.216.83.0", "91.216.86.0")
var ipList []string
for _, cidr := range cidrs {
ipSubList, err := getRangeListByCidr(cidr)
if err == nil {
ipList = append(ipList, ipSubList...)
}
}
if len(ipList) != 768 {
t.Fatal("Tried to expand CIDR , got IP number mismatch")
}
}
func TestProcessPipe(t *testing.T) {
content := []byte("ripencc|CH|ipv4|91.216.83.0|768|20100512|assigned|dda39a5e-9b71-4fce-b6fd-d857491ce5e6")
mockInput, err := ioutil.TempFile("", "test-process-pipe")
if err != nil {
t.Fatal(err)
}
defer os.Remove(mockInput.Name())
if _, err := mockInput.Write(content); err != nil {
t.Fatal(err)
}
if _, err := mockInput.Seek(0, 0); err != nil {
t.Fatal(err)
}
mockSuccessOutput, err := ioutil.TempFile("", "test-pipe-output-success")
if err != nil {
t.Fatal(err)
}
defer os.Remove(mockSuccessOutput.Name())
mockFailOutput, err := ioutil.TempFile("", "test-pipe-output-fail")
if err != nil {
t.Fatal(err)
}
defer os.Remove(mockFailOutput.Name())
processPipe(mockInput, mockSuccessOutput, true)
processPipe(mockInput, mockFailOutput, false)
success, err := os.ReadFile(mockSuccessOutput.Name())
if err != nil {
t.Fatal(err)
}
fail, err := os.ReadFile(mockFailOutput.Name())
if err != nil {
t.Fatal(err)
}
if !(bytes.Contains(success, []byte("91.216.83.0/2491.216.84.0/23")) &&
bytes.Contains(success, []byte("91.216.83.0/2491.216.84.0/23"))) {
t.Fatal("content output is incorrect")
}
if !bytes.Contains(fail, []byte("Need to use linux shell pipe method to use")) {
t.Fatal("content output is incorrect2")
}
if err := mockSuccessOutput.Close(); err != nil {
t.Fatal(err)
}
if err := mockFailOutput.Close(); err != nil {
t.Fatal(err)
}
if err := mockInput.Close(); err != nil {
t.Fatal(err)
}
}
上面的程序实现了绝大多数函数的功能和分支覆盖,将上面的内容保存为 main_test.go,并和上文中的程序放置在相同的目录中,接着,执行 go test -v 来进行基础功能验证,不出意外,我们将会得到类似下面的执行结果:
=== RUN TestIpToValue
--- PASS: TestIpToValue (0.00s)
=== RUN TestGetRangeEndpointWithLine
--- PASS: TestGetRangeEndpointWithLine (0.00s)
=== RUN TestGetCidrByRangeEndpoint
--- PASS: TestGetCidrByRangeEndpoint (0.00s)
=== RUN TestGetCidrRangeList
--- PASS: TestGetCidrRangeList (0.00s)
=== RUN TestExpendCIDR
--- PASS: TestExpendCIDR (0.00s)
=== RUN TestProcessPipe
--- PASS: TestProcessPipe (0.00s)
PASS
ok github.com/soulteary/ip-cidr 0.608s
当然,为了更加直观的了解程序的健壮程度,我们还可以使用下面的命令来查看代码覆盖率:
go test -coverprofile=coverage.out ./... && go tool cover -html=coverage.out && rm coverage.out
命令执行完毕,我们的浏览器会直接打开,并提示我们代码覆盖率已经达到了 96%+,基本算是一个比较健康的程序啦。
在完成了程序验证之后,我们就可以进行程序的编译和使用啦。
编译程序
在开始编译程序之前,我们还需要创建一个名为 go.mod 的文件,用来声明程序的名称,举个例子:
module github.com/soulteary/ip-cidr
go 1.18
保存好文件之后,我们在目录中执行下面的命令,进行程序的构建:
go build -ldflags "-w -s"
当命令执行完毕之后,我们就能够在当前文件夹中得到一个名为 ip-cidr 的可执行文件了。
使用程序处理 IP CIDR 数据
使用编译好的程序也非常简单,我们将需要处理的 IP 列表用 cat 读取,然后发送到程序中,然后使用输出重定向,将结果进行保存即可:
cat data.txt | ./ip-cidr > result.txt
最后
写到这里,正确处理 CIDR 数据就介绍完啦。如果你还有什么问题,欢迎在 GitHub 或者专栏中提出。
我们,下一篇文章再见。
–EOF