聊聊之前做过的一个小东西的踩坑历程,如果你也想高效获取信息,或许这个系列的内容会对你有用。
这个事情涉及的东西比较多,所以我考虑拆成一个系列来聊,每篇的内容不要太长,整理负担和阅读负担都轻一些。
本篇是系列第一篇内容。
写在前面
两个月前,我创建了一个新的项目 “potted”,尝试使用 Golang 写了一个小工具,用来取代之前使用的基于 Node 编写的 RSS Hub,在折腾过程中做了一些比较关键的技术点验证。
在得到了确定答案之后,我觉得是一个合适的时间点,将这个点子变成一个新的开源的工具项目:RSS Can(RSS 罐头),项目的地址是:soulteary/RSS-Can 。
项目中的代码,将会伴随文章更新而更新,如果你觉得项目有趣,欢迎“一键三连”。当然,如果你觉得这个事情有价值,也有趣,也欢迎加入项目,一起折腾。
在验证过程中,折腾了一些有趣的实现,比如:
- 让 Golang 在运行时能够结合 JS 来实现动态配置(你当然也可以结合 Python、Lua 等你自己喜欢的语言),能够灵活选择哪种语言,来让“静态语言”的产物更“灵动”一些。
- 能够灵活的从各种网络环境获取不同网站的资讯内容,以及支持不同技术方式生成的页面信息内容,比如服务端生成、客户端生成(比如 JS)。
- 不仅仅输出 RSS 格式数据,也能够输出 JSON 数据,用来形成 Info Pipeline,让信息最终呈现结果,可以经过 AI 服务的处理,再提供给我来阅读使用。
- 相比较 Node 服务,更低的运行资源诉求,可以将这个服务运行在廉价的设备或者云主机上,有效降低运行、运维成本。
如果你本地没有 Golang 环境,可以阅读《搭建可维护的 Golang 开发环境》、《M1 芯片 Mac 上更好的 Golang 使用方案》这两篇文章,来快速搞定开发环境。如果你还没有使用过 RSS,也可以阅读 RSS 标签下的文章,来体验下算法推荐之外的定向获取信息的方式。
先来聊聊最基础的,对于传统网站的信息获取和整理。
信息阅读的痛点
我用一个“偶尔会看”的网站 36Kr 为例,在聊具体技术实现之前,先来聊聊我遇到了哪些问题。
36Kr 上有一些专业编辑写出来的稿子还是很棒的,尤其是和我关注领域重合的时候。但之所以我说只是“偶尔使用”,我个人认为原因主要有下面三个:
首先,网站资讯更新还是比较多的,需要在一堆消息里挑选自己感兴趣的内容,要花费不少时间。
但是,让我每天定时上网站搜索,看看有没有新的内容,这样做效率太低了,难以坚持。我希望得到的信息,至少是能够根据关键词进行筛选出来的。
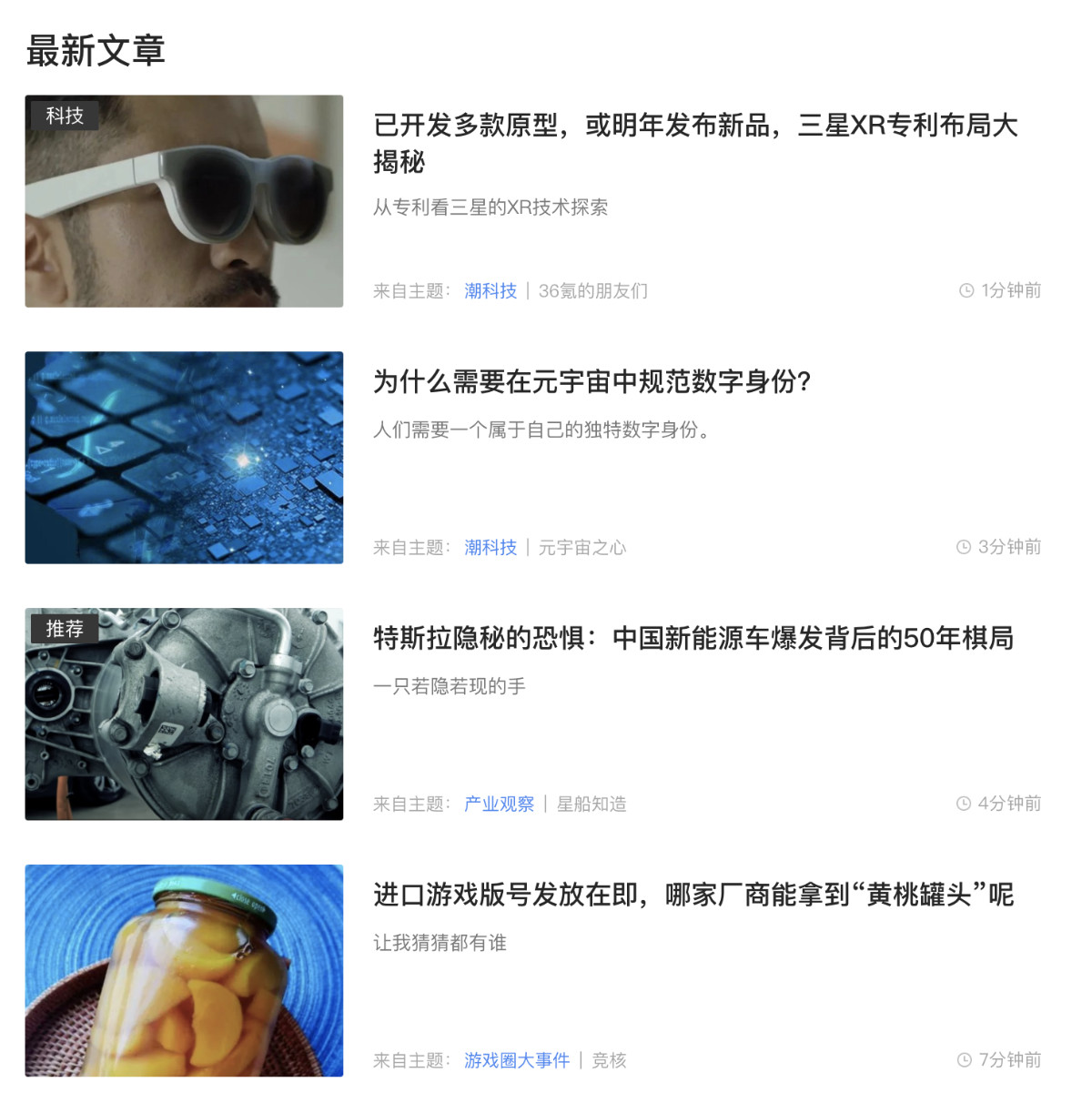
第二,我常使用的 RSS 工具 无法直接解析它官方的 RSS 源 ,并且官方的 RSS 源里,也没有很好的进行子版块的消息分类。如果,用户想使用 RSS 的方式来获得子版块消息,那么只能靠 DIY 了。
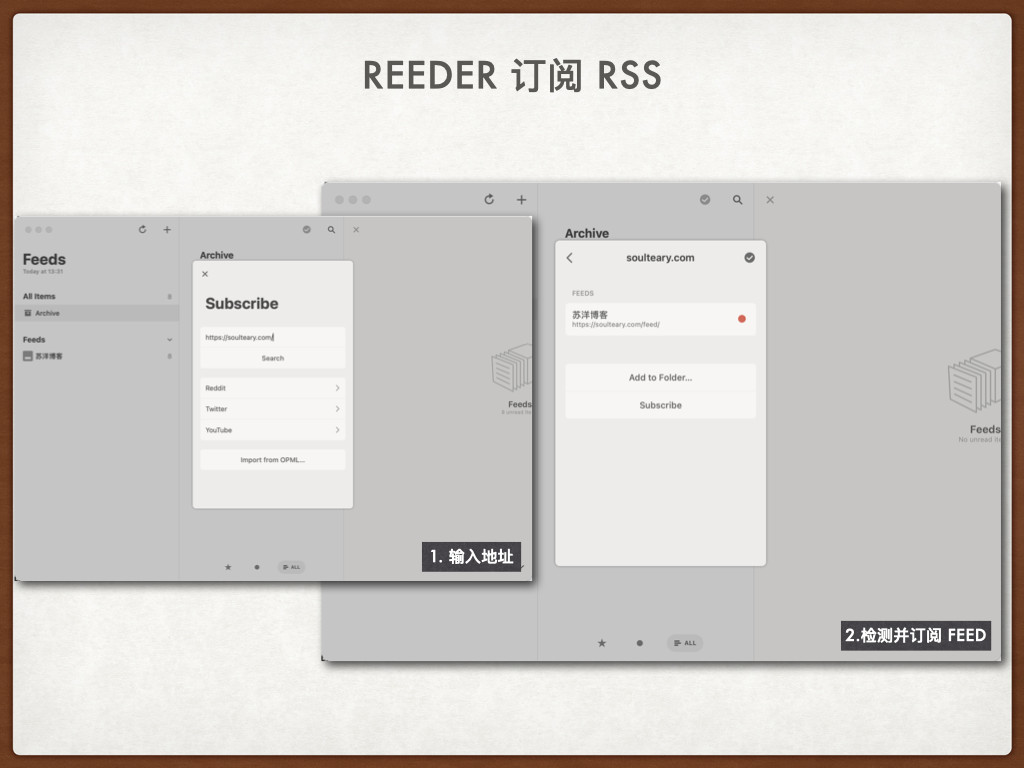
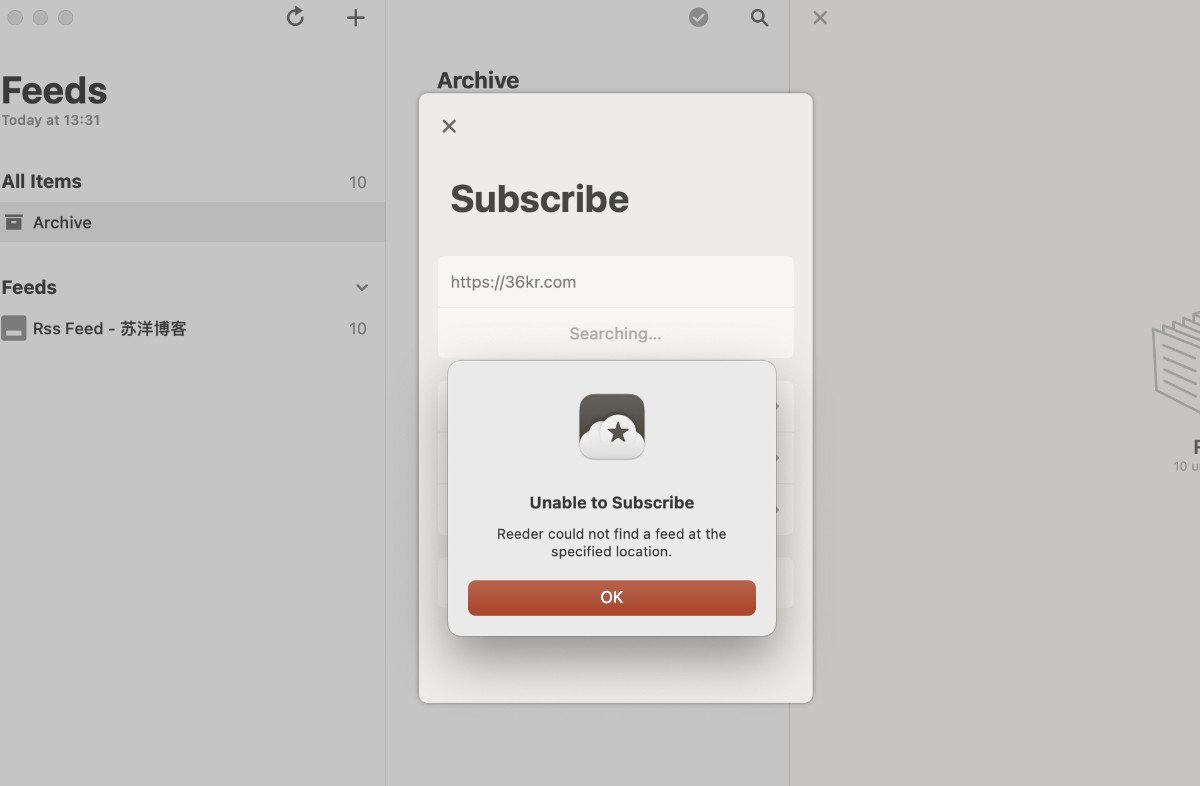
最后,有一些各种平台都发的“通稿”的内容,我希望他们能合并起来。内容平台生存不易,即使是头部的科技媒体,也一定需要接商单。作为用户可以帮助平台消化内容分发,但是 老看到各种信息来源都会重复出现的内容,慢慢就不想看了。
上面的问题,不单是 36Kr 存在,甚至第三条都不是 36Kr 的问题,其他的平台也存在。但是,作为一个关注各种渠道信息动态的人来说,如果官方没有提供用户信息合并能力,不能提供全网的信息(还不是一个权威信息 Hub),想提升阅读体验,也就只能靠 DIY 啦。
使用 Go Query 实现基于页面的信息抽取
因为我们关注的信息来源于网页的列表内容,所以我们可以使用程序来解析列表内容,并进行筛选,得到我们想要的信息。
比如,我们可以通过在网页上右键,打开调试工具的窗口,然后在“元素”选项卡里,先找到包含信息的列表元素。

接着,在元素上右键选择复制“Selector”,得到程序快速解析必要列表信息的“路径规则”。
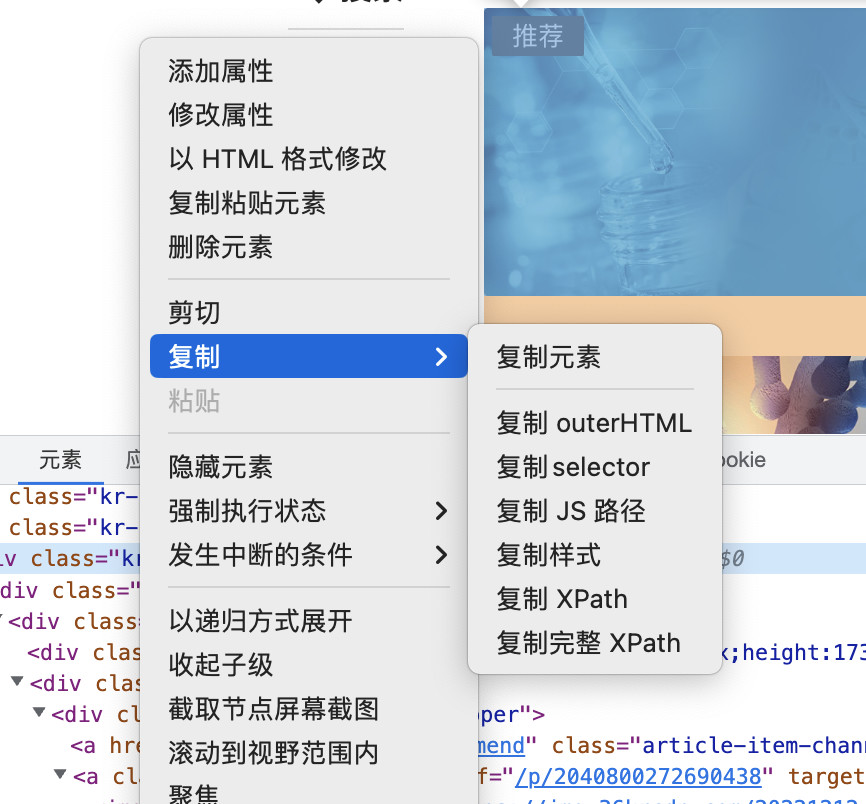
如果我们将内容粘贴出来,大概是这样的:
#app > div > div.kr-layout-main.clearfloat > div.main-right > div > div > div.kr-home-main > div.clearfloat > div.kr-home-flow > div.kr-home-flow-list > div:nth-child(1) > div
其实,有一些开源工具关于元素的可视化选择、以及路径生成已经做的很好了,比如 uBlock 里的元素选择等等。因为这个话题比较大,我们后面的文章再展开。
在得到元素路径之后,我们可以考虑进行一些调整优化,并写一段简单的 JavaScript 代码,来验证程序是否能稳定获取到信息:
document.querySelectorAll("#app .main-right .kr-home-main .kr-home-flow .kr-home-flow-list .kr-flow-article-item")
我们将上面这段程序扔到网页的“控制台”中执行,验证是否能够“圈选”出我们想要的信息列表。
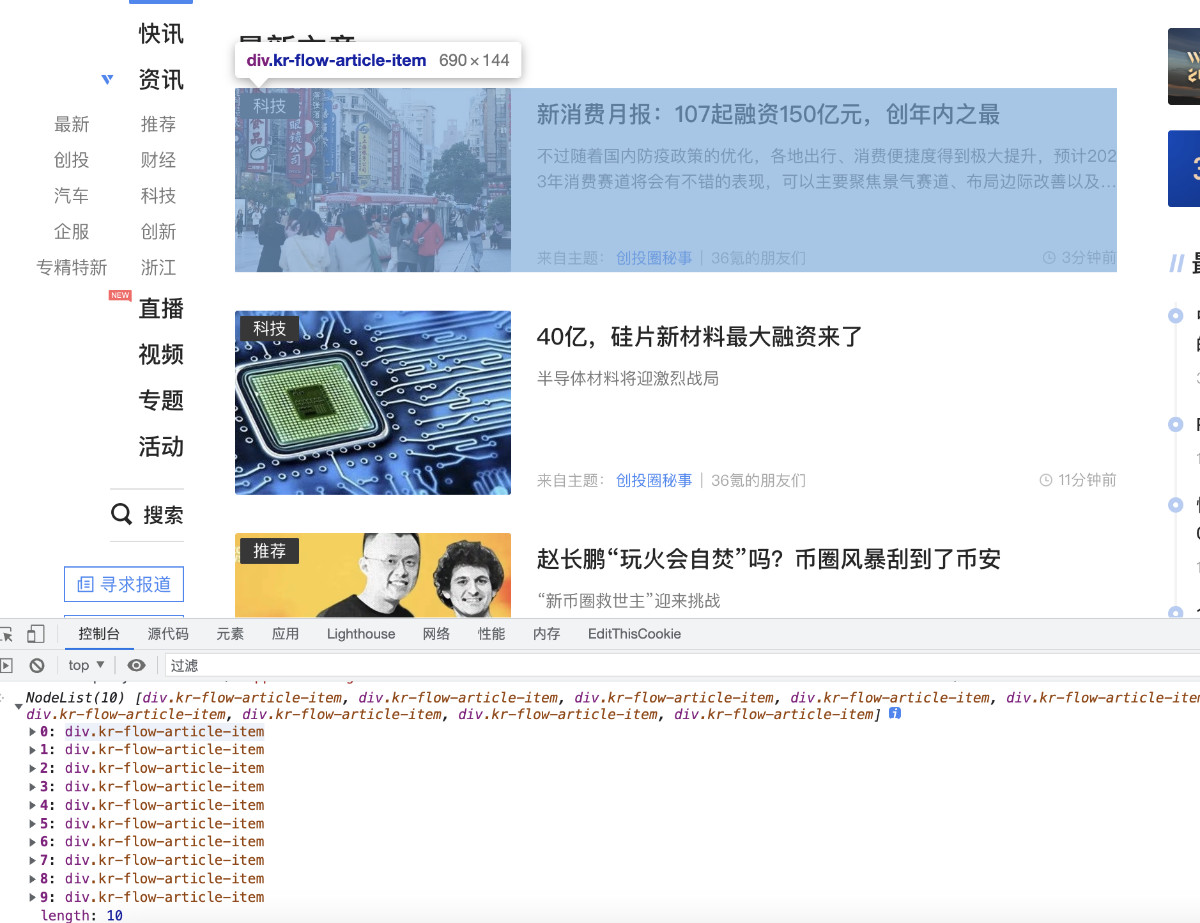
因为类似 36 Kr 这类传统一些的内容网站,使用的都是基于服务端渲染的方式提供内容,用大白话说就是 HTML 页面内容中包含了我们想要的信息。所以,我们可以实现程序通过解析网页 DOM 结构,来快速抽取页面中的关键信息,然后整理成 RSS 信息源或者 API,搭配 RSS 阅读器或者其他的工具进行进一步的数据分析,最后进行最终内容呈现或者进行消息推送。
选择 Go 作为基础技术栈之后,我们可以使用生态中的开源项目PuerkitoBio/goquery,来针对页面内容进行解析,为自己整理有价值的信息。
参考项目的例子,我们不难写出下面的程序:
package main
import (
"fmt"
"log"
"net/http"
"strings"
"github.com/PuerkitoBio/goquery"
)
func getFeeds() {
// Request the HTML page.
res, err := http.Get("https://36kr.com/")
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
if res.StatusCode != 200 {
log.Fatalf("status code error: %d %s", res.StatusCode, res.Status)
}
// Load the HTML document
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
log.Fatal(err)
}
// Find the article items
doc.Find("#app .main-right .kr-home-main .kr-home-flow .kr-home-flow-list .kr-flow-article-item").Each(func(i int, s *goquery.Selection) {
title := strings.TrimSpace(s.Find(".article-item-title").Text())
time := strings.TrimSpace(s.Find(".kr-flow-bar-time").Text())
fmt.Printf("Aritcle %d: %s (%s)\n", i+1, title, time)
})
}
func main() {
getFeeds()
}
将上面的程序保存为 main.go,然后执行 go run main.go 将会得到下面的异常退出的结果:
2022/12/12 13:50:56 unexpected EOF
exit status 1
程序看起来正常,但是执行后却没有返回预期内的结果。我们可以简单思考下为什么会出现这个问题,“变量在哪里”。
因为我们无法得到目标网站的代码,所以只能进行推测:我们使用浏览器能够访问信息,但是使用程序却不能访问信息,这个场景下主要的差异点之一在于网络请求中的 User Agent (客户端标识)不同,网站前端服务器过滤掉了非“浏览器”的请求。
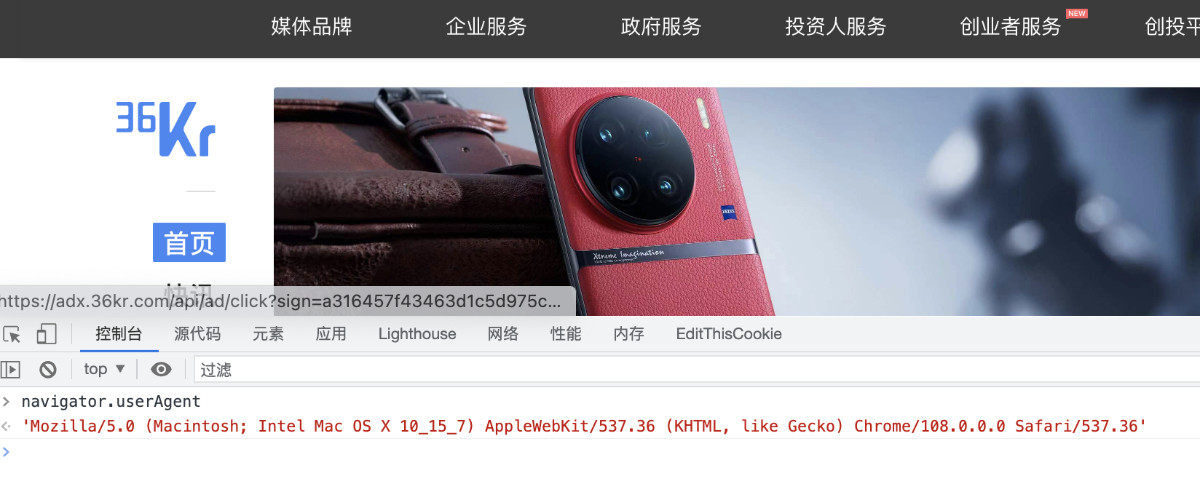
还是打开浏览器,在控制台里执行 JavaScript 代码 navigator.userAgent,得到我们自己的浏览器的信息:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36
接着,调整下上文中面发起网络请求的部分,让程序在发起请求的时候,让程序能够携带上我们的浏览器 UA 信息:
package main
import (
"fmt"
"log"
"net/http"
"strings"
"github.com/PuerkitoBio/goquery"
)
const DEFAULT_UA = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
func getRemoteDocument(url string) (*goquery.Document, error) {
req, err := http.NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
req.Header.Set("User-Agent", DEFAULT_UA)
res, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
if res.StatusCode != 200 {
return nil, fmt.Errorf("status code error: %d %s", res.StatusCode, res.Status)
}
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
return nil, err
}
return doc, nil
}
func getFeeds() {
// Request the HTML page.
doc, err := getRemoteDocument("https://36kr.com/")
if err != nil {
log.Fatal(err)
}
// Find the article items
doc.Find("#app .main-right .kr-home-main .kr-home-flow .kr-home-flow-list .kr-flow-article-item").Each(func(i int, s *goquery.Selection) {
title := strings.TrimSpace(s.Find(".article-item-title").Text())
time := strings.TrimSpace(s.Find(".kr-flow-bar-time").Text())
fmt.Printf("Aritcle %d: %s (%s)\n", i+1, title, time)
})
}
func main() {
getFeeds()
}
再次执行 go run main.go,会发现已经能够得到信息列表啦。
Aritcle 1: 为什么 Google 总是在不断地关闭产品呢? (1分钟前)
Aritcle 2: 放弃L5全自动驾驶,苹果造车能走多远? (11分钟前)
Aritcle 3: 圆桌论坛:Web3.0与元宇宙的融合趋势 | WISE2022 新经济之王大会 (23分钟前)
...
最后
接下来的内容里,我们来聊聊,如何将这些信息源转换为 RSS 阅读器可以使用的信息源,以及如何针对不同类型的网站进行信息整理。当然,还有文章中开头提到的有趣的几个技术点。
–EOF