本篇文章聊聊 OpenAI Code Interpreter 的一众开源实现方案中,获得较多支持者,但暂时还比较早期的项目:GPT Code UI。
写在前面
这篇文章本该更早的时候发布,但是 LLaMA2 发布后实在心痒难忍,于是就拖了一阵。结合 LLaMA2 的本地私有化部署和运行的能力,接下来这类应用或许都有会一些不同于以往的有趣的玩法,还是非常期待的。
Code Interpreter是一个潜力巨大的功能,或者说方向,不过目前的体验一言难尽,不论是 OpenAI 还是开源软件。
本文中介绍的项目,目前依旧还在早期,不论是实现细节还是架构上都有比较多的这样或那样的问题,但开源世界里,软件的进化,可能会比想象中的要快的多,可以适当保持期待。
演示所使用的容器方案,代码和镜像已经上传至 GitHub 和 DockerHub,有需要的同学可以自取,别忘记“一键三连”:
soulteary/docker-code-interpreter
后续,我会将看到的类似的 Code Interpreter 类型的开源项目都收集到这个项目中,并附加干净 & 稳定的容器镜像。
本篇文章中,我们先来使用社区原版的软件,配合 OpenAI API 或 Azure OpenAI Service,来完成基础的本地 Code Interpreter 的搭建和运行。
GPT Code UI 的镜像使用
想要使用 GPT Code UI,只需要两步:下载镜像,写配置文件后用 Docker 把服务“拉起来”。
下载 GPT Code UI 容器镜像
使用 Docker 下载我们所需要的镜像文件,由于软件处于早期,变动概率较高,这里我推荐使用带有版本号的下载方式,进行 Docker 镜像的下载:
docker pull soulteary/gpt-code-ui:0.42.35
镜像不大,200MB 左右,包含了基础软件和 GPT API 输出代码中常见的 Python PyPI 依赖库。
编写使用 OpenAI API 容器配置
如果你使用的是 OpenAI API 的话,我们可以这样写一个配置文件:
version: "3.8"
services:
gpt-code-ui:
image: soulteary/gpt-code-ui:0.42.35
environment:
OPENAI_API_KEY: "YOUR_TOKEN"
API_PORT: 5010
WEB_PORT: 8080
SNAKEMQ_PORT: 8765
APP_HOST: "0.0.0.0"
# optional: if you want to use proxy
# HTTPS_PROXY: "http://host.docker.internal:1234"
ports:
- "8080:8080"
将上面的内容保存为 docker-compose.yml,然后使用 docker compose up 启动服务。
接着,在浏览器中访问 http://localhost:8080 或者 http://你的IP:8080 就能够看到默认的服务页面了。
界面中的 Kernel is ready. 代表着服务运行就绪,我们可以开始玩了。
额外注意的是,如果你的服务部署在国内,应该需要配置 HTTPS_PROXY 来确保访问 OpenAI API 正常。
编写使用 Azure OpenAI API 容器配置
如果你使用的是 Azure 的 OpenAI API 服务,那么配置需要稍稍调整下:
version: "3.8"
services:
gpt-code-ui:
image: soulteary/gpt-code-ui:0.42.35
environment:
OPENAI_API_KEY: "YOUR_TOKEN"
OPENAI_API_TYPE: "azure"
OPENAI_BASE_URL: "https://YOUR_DOMAIN.openai.azure.com/"
OPENAI_API_VERSION: 2023-03-15-preview
AZURE_OPENAI_DEPLOYMENT: "gpt-35-turbo"
API_PORT: 5010
WEB_PORT: 8080
SNAKEMQ_PORT: 8765
APP_HOST: "0.0.0.0"
# optional: if you want to use proxy
# HTTPS_PROXY: "http://host.docker.internal:1234"
ports:
- "8080:8080"
还是将配置保存为 docker-compose.yml,然后使用 docker compose up 启动起来,就可以通过浏览器访问你的服务了。
GPT Code UI 的使用
我估计没有使用过 ChatGPT Code Interpreter 功能的同学,在启动起来服务之后,会有一些懵圈。接下来,我们来一起试试这个服务的基础使用。
想要比较舒服的使用这类软件,我们首先需要一个合适的“数据集”,我从网上随手搜了一个“电视主机游戏销售数据”,你可以在浏览器里打开这个数据集文件,并将数据集保存为 vgsales.csv。
我们在 GPT Code UI 中上传这个数据集后。能够看的程序会自动解析 CSV 数据集中的表头,告诉我们可以用哪些字段来玩。

File vgsales.csv uploaded successfully.
The file contains the following columns: Rank, Name, Platform, Year, Genre, Publisher, NA_Sales, EU_Sales, JP_Sales, Other_Sales, Global_Sales
接着,我们可以随便输入点啥,比如问问它销量前十的游戏是啥:“show top 10 games”。
然后,我们就能够看到它去结合这个数据集,生成的获取销量前十的游戏的代码了:
import pandas as pd
import os
# get the most recently uploaded file
files = os.listdir()
files.sort(key=os.path.getmtime)
latest_file = files[-1]
# read in the csv file as a pandas dataframe
df = pd.read_csv(latest_file)
# show top 10 games by global sales
top_10 = df[['Name', 'Global_Sales']].sort_values(by='Global_Sales', ascending=False).head(10)
print(top_10)
# if code modifies or produces a file, print link to download it
print("<a href='/download?file=" + latest_file + "'>Download file</a>")
为了节约我们的时间,程序会尝试自动执行生成的代码。

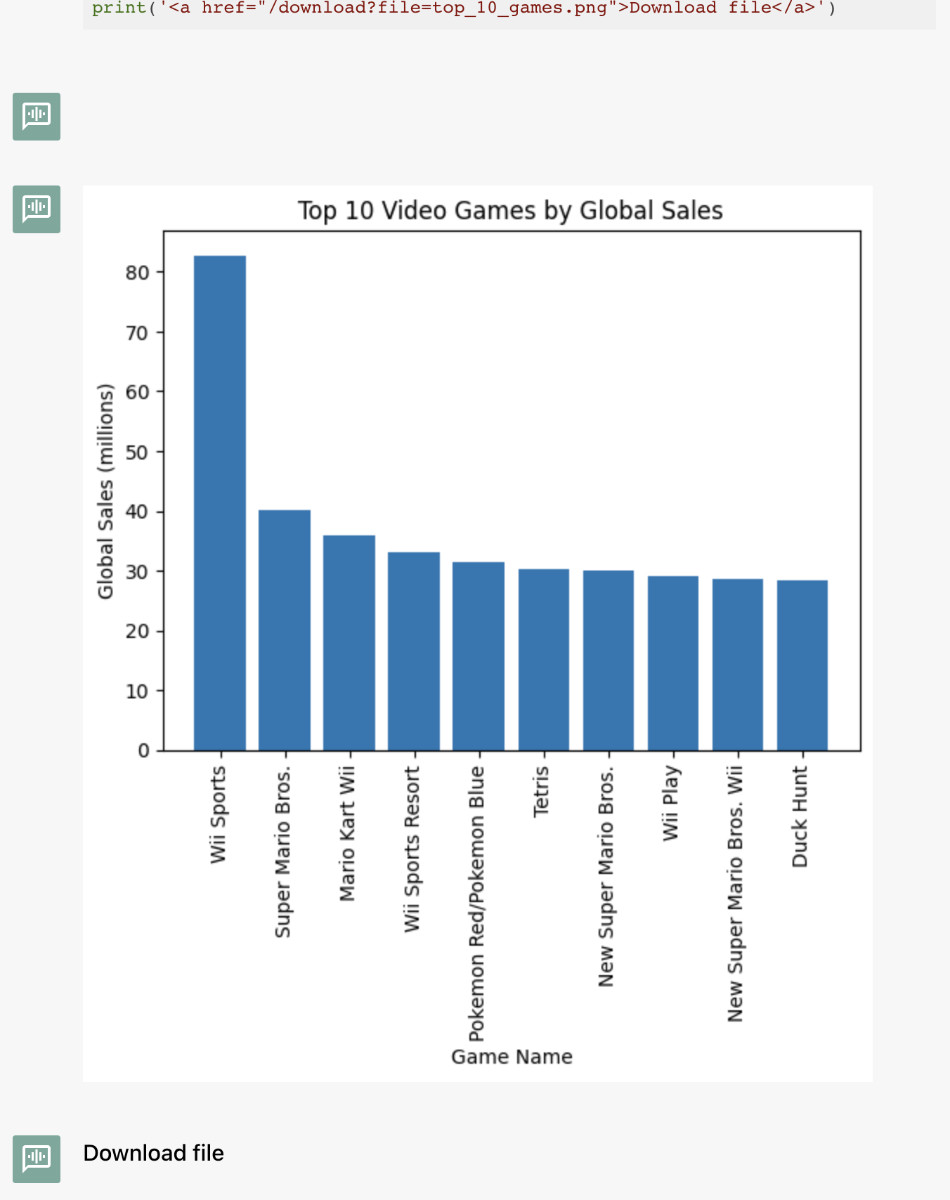
只要上一步生成的代码可以被正确执行,我们就都能够看的代码执行后的结果,得到我们想要的数据列表:
Name Global_Sales
6112 Wii Sports 82.74
122 Super Mario Bros. 40.24
8322 Mario Kart Wii 35.82
9750 Wii Sports Resort 33.00
705 Pokemon Red/Pokemon Blue 31.37
188 Tetris 30.26
6113 New Super Mario Bros. 30.01
6114 Wii Play 29.02
9751 New Super Mario Bros. Wii 28.62
108 Duck Hunt 28.31
Download file
假设我们不需要复制粘贴文本,想要更直观的看到数据之间的差异,可以试试将结果转换为图表。
方法很简单,给他提一个“draw top 10 games”的需求就好,它会自动分析需求,然后生成一个可以绘图的代码片段:
import pandas as pd
import matplotlib.pyplot as plt
# Read the CSV file into a pandas dataframe
df = pd.read_csv("vgsales.csv")
# Sort the dataframe by global sales in descending order
df = df.sort_values("Global_Sales", ascending=False)
# Get the top 10 games by global sales
top_10 = df.head(10)
# Create a bar chart of the top 10 games
plt.bar(top_10["Name"], top_10["Global_Sales"])
plt.xticks(rotation=90)
plt.xlabel("Game Name")
plt.ylabel("Global Sales (millions)")
plt.title("Top 10 Video Games by Global Sales")
plt.show()
# Print link to file if generated
print('<a href="/download?file=top_10_games.png">Download file</a>')
尝试执行之后,我们就能够得到更直观的结果啦。
上面的例子,都太过简单了,只是针对单一条件的分析。接下来,我们来试着用组合条件来进行数据分析和图表绘制。
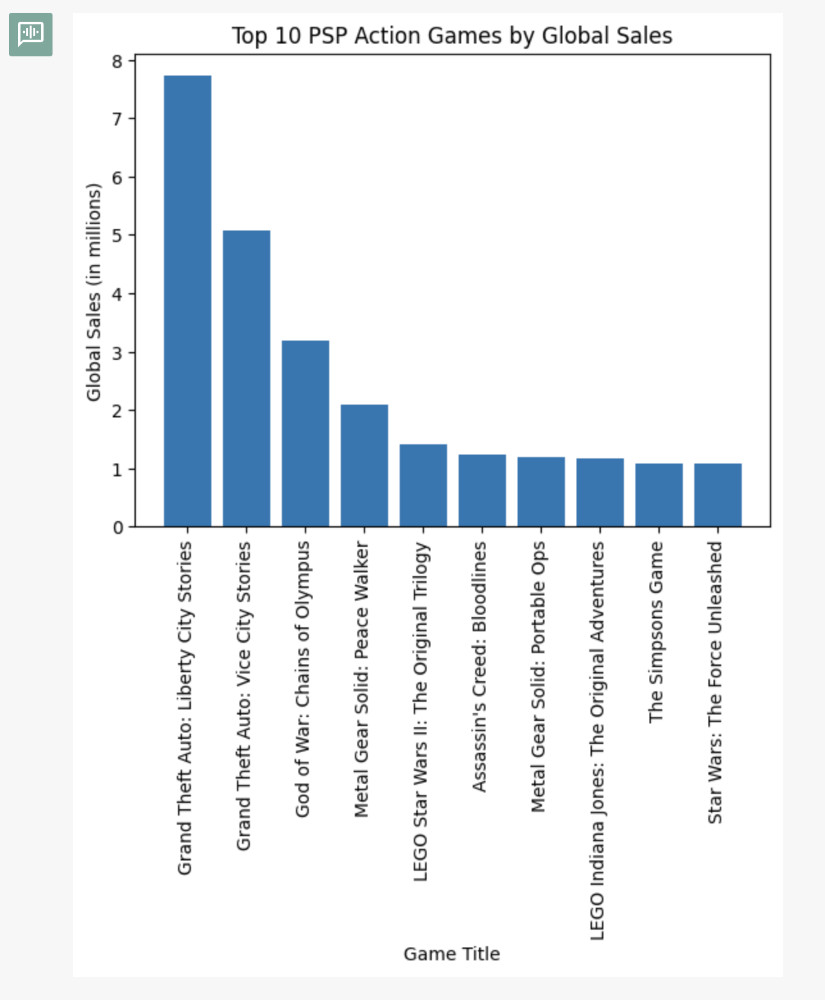
比如我们想要获取销量最高的 PSP 动作类游戏,以往如果写代码的话,我们需要告诉他游戏平台是 PSP,游戏类型是动作游戏,排序方法是按照销量数据量,数据条数选择 10 条。
但是,有了 Code Interpreter 和语言模型之后,我们可以提个简单(含糊)的要求 “draw top 10 PSP action games”,模型就会自己分析数据然后生成可以玩的代码了:
import pandas as pd
import matplotlib.pyplot as plt
# read the csv file
df = pd.read_csv('vgsales.csv')
# filter for PSP games and action genre
psp_action = df[(df['Platform'] == 'PSP') & (df['Genre'] == 'Action')]
# sort by global sales and get top 10
top_10 = psp_action.sort_values(by='Global_Sales', ascending=False).head(10)
# create bar chart of top 10 games
plt.bar(top_10['Name'], top_10['Global_Sales'])
plt.xticks(rotation=90)
plt.xlabel('Game Title')
plt.ylabel('Global Sales (in millions)')
plt.title('Top 10 PSP Action Games by Global Sales')
plt.show()
print("<a href='/download?file=top_10_psp_action_games.png'>Download file</a>")
只要“动动嘴”,说出你想要的,结果“秒秒钟”就出现在你的眼前了,是不是很方便?
其他
目前这个项目还处于比较早期的阶段,从架构设计上、安全性、性能指标和可扩展性等等方面都有比较多的可完善之处。
你在运行的过程中,可能会出现类似这样或者那样的各种问题,比如:
ModuleNotFoundError Traceback (most recent call last)
Cell In[2], line 4
2 import pandas as pd
3 import numpy as np
----> 4 import dateparser
5 import matplotlib.pyplot as plt
6 import geopandas as gpd
ModuleNotFoundError: No module named 'dateparser'
或者一些变量、目录相关的报错,遇到这类问题可以考虑重试下问题,让它再次生成代码,避开之前的坑。
最后
好了,这篇关于开源社区的 Code Interpreter 的介绍就写到这里了。目前,我在同时在积极的为社区的这类项目提供 PR 和建议,希望这类项目能够走的更远。
说起来,自 Code Interpreter 上线后,身边的一众工程师狂喜。然而普通用户似乎并不那么感冒,一如当今已经炙手可热的 ChatGPT,在去年十一月时也只是少数人的狂欢。
个人观点,目前为止它是一个目前依旧被低估的产品,而非一个简单的 Chat 内的工具。多数使用场景,目前还停留在数据分析师和“代码生成和微操优化”上,然而它能带来的远不止如此。
如果你只关注代码,那么你可以当它是一个既能生成代码,又能执行验证,甚至从结果中继续展开的,具备智能的高级程序运行环境。
如果你不在乎代码是如何被生成和执行的,那么你可以当它是官方出品的,一个比 AutoGPT 完成度更高,未来生态和能力更强的高级自动化工具。
如果你不局限于当前的能力,帮助它联上网,让它能够从具体的数据库、知识库中获取信息,以及给予它更强力的代码容器环境,以及更多的 API 访问权限,它会是一个真正的懒人工具:更少的幻觉、更多的准确性和严格的逻辑性,具备执行能力和打通多种软件系统的能力。
–EOF