本篇内容,分享一个和 Redis 相关的比较基础的技术实践内容。使用本体价值不到 3000 块钱的二手笔记本设备,和经典的 Redis 技术栈来加速上亿规模数据的查询效率。
写在前面
最近有一个项目的子需求,需要处理 5~10 亿规模的多种宽表数据,使得数据能够进行毫秒级别的大量关联查询。
项目原本使用的是云服务器(虚拟机),但总是数据跑着跑着就因为服务器的 iowait 过高,然后造成 CPU 任务挤压,最终发生导致死机。为了“缓解”这个问题,我在程序中加了非常多“等待”策略,但是只要云服务器性能出现抖动,数据处理任务堆积,写入速度稍微超过 200 MB/s,云服务器的死机几乎 100% 发生。
通常这个问题出现在已经持续写入几十 GB 之后,重试几次之后,我决定使用本地的小机器来解决这个问题,要知道需要处理原始数据的其中一部分就有 600 多GB,总是死机不是个办法。2023 年的时候,我分享过《低成本搭建一台家庭存储服务器:全闪存篇》,但其实在此之前,我的各种计算类设备已经都是全闪存了。简单来说,本地的计算资源和存储资源还是比较丰富的,既然云端无法使用,那么就用老老实实本地的资源吧。

这个项目中,我一共使用了两台笔记本,本文中提到的笔记本,是在 2021 年的时候的文章《AMD 4750u 及 5800u 笔记本安装 Ubuntu 20.04》中提到过的 ThinkPad L14(我一共买了两台,故事在《在笔记本上搭建高性价比的 Linux 学习环境:基础篇》“使用裸金属的方式运行 Linux 的好处”中有提到)。
这台设备搭载了一颗 2020 年出品的 AMD Zen 系列第二代处理器:AMD Ryzen 7 PRO 4750U,支持用户手动添加两片 32GB 的 DDR 4 内存条。关于这类使用笔记本作为廉价工作站的思路,在更早时候的文章《廉价的家用工作站方案:前篇》中有提到过,这里就不再展开。
考虑到后续还是要将项目上云,项目需要交给其他人来维护,需要尽可能降低运维成本,所以选择了 Redis 官方版本,而没有使用各种 Redis 协议兼容、可以做数据持久化的弹性 KV 系统,其中包括经典的 Pika、KeyDB、Tendis 等等。
既然我们选择了容易上云的云原生组件,省了运维的成本,那么自然的,许多优化的工作就需要放在开发侧,自己来做啦。
关于 Redis 你需要知道的事情
相信熟悉我文章的朋友,或从业时间比较久的同学应该都知道或用过 Redis。
Redis 这个开源项目发展至今,功能和性能都变的异常强大,我们甚至能够将它作为向量数据库使用。在之前的文章《使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(一)》、《使用 Redis 构建轻量的向量数据库应用:图片搜索引擎(二)》有提到过,感兴趣的同学可以自行翻阅。
如果你还不了解 Redis,那么这里我就多聊几句。简单来说它是一个高性能的开源内存数据存储系统,它将数据存储在内存中,借助内存介质性能非常高的特性,以实现快速的数据读写操作。作为一个键值对数据库,Redis 支持多种数据结构,包括字符串、哈希表、列表、集合和有序集合等。Redis 采用单线程模型处理请求,避免了多线程带来的上下文切换开销和竞争问题。虽然数据主要存储在内存中,但 Redis 也提供了数据持久化机制,可以将数据保存到硬盘上以防数据丢失。
在实际业务应用中,Redis 常被用作缓存层来提升应用性能,也可用于实现计数器、消息队列、会话管理等功能。它支持主从复制、事务操作和发布订阅等特性,这些特性使其成为构建高可用、可扩展系统的重要工具。各种云厂商的系统和平台中,都能够看到这个云服务基础组件。
虽然 Redis 也支持将内存中的数据持久化到硬盘中,但是仅支持 RDB(Redis Database)和 AOF(Append Only File) 两种模式。前者是一种压缩的二进制文件,因为体积小,所以加载速度快,但是可能会丢失最近一次的最新快照数据。后者是将 Redis 所有的写入操作都以账本的方式存储下来,可读性高,但是整个文件很大,数据恢复需要将命令重新执行一次,所以恢复时间也长。
在互联网公司的业务场景中,我们会使用一些 Redis 协议兼容的软件,在保持提供高性能数据存/访的情况下,能够将数据存储到硬盘中,通过算法进行动态的策略调用,尽可能降低内存的使用量。或者使用能够扩展内存用量的傲腾磁盘,在确保程序复杂度不提升的情况下,极大的扩展系统的整体容量。毕竟,服务器环境中,常规的内存的容量总是有限的,而在相同一套硬件环境中,硬盘的存储单位可以做到 PB 或者更高。
本文中,我们使用的策略是用 Redis 作为缓存服务,并使用 RDB 模式进行数据存储(默认),确保服务重载恢复速度更快。
准备工作
上文提到了,我们需要处理的一部分原始数据有 600GB,其中一部分数据的简单索引后的数据量在 225GB 左右。
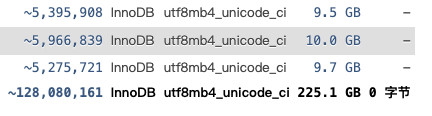
在云服务器环境中,我们可以动辄启动几百 GB 的内存云服务器实例。但通常家用设备或者微塔等小型服务器等设备等内存是没有这么大的,可以选择的设备型号其实真的不多。
而且,由于我不喜欢暴力风扇带来的噪音,更倾向于在家里使用能够安静模式运行的设备,所以能够使用超过 64GB 内存的家用设备选型就更少了。通常在处理大量数据的时候,我们还需要考虑冷不丁的数据出错的问题,还需要使用 ECC 内存,以及再加上一些价格的限定条件,这样几乎就没什么可选的设备了。
目前我的家里的相对大内存的设备只有《廉价的家庭工作站设备改造记录:苹果垃圾桶(Mac Pro 2013)》一文中,提到的“垃圾桶”(128GB ECC 内存),其他的若干设备基本都只有 64GB。
所以,不论如何我手头的单一设备都是无法存储下所有的原始数据的,也更别提数据结构化后、或稍微加一点点索引数据的新数据了。哪怕我们不考虑原始数据,单就是挑出来的 225GB 的数据文件也是存不下的。
当然,除了存储数据,我们还需要考虑到设备的运行稳定性,还需要留一些内存给系统和其他程序运行使用。
所以,我们需要想办法,尽量高效的选择数据,并存放在我们资源有限的设备里。让我们先从快速运行一个 Redis 服务开始聊吧。
使用容器快速启动 Redis 服务
上文中提到,我使用的这台笔记本设备有 64GB 内存,它运行的操作系统是 Ubuntu Server 24.04。考虑到本地维护的简单,我们使用 Docker 来启动接下来存储数据的 Redis 服务。
让我们先编写一个适合 Docker 运行的 Redis 配置文件:
name: redis
services:
redis:
image: redis:7.4.1
container_name: redis
command: redis-server
ports:
- "6379:6379"
volumes:
- ./redis-data:/data # 数据持久化到当前目录中的 `redis-data`
restart: always
environment:
- TZ=Asia/Shanghai # 设置时区
deploy:
resources:
limits:
memory: 50G # 限制最大内存使用
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 3s
timeout: 5s
retries: 3
将上面的配置文件保存为 docker-compose.yml,然后执行命令 docker-compose up -d ,我们就能够通过访问 6379 端口和 Redis 服务进行数据交互了。
了解你的设备内存读写能力
我们可以写一段简单的程序,来模拟 Redis 工作时的场景,用 4KB 大小的数据模拟 Redis 写入,或读取累计 1GB 的数据量,通过执行时间来直观的了解设备的性能。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <sys/time.h>
#define SIZE (1024 * 1024 * 1024) // 1GB
#define BLOCK_SIZE (4096) // 4KB blocks
double get_time()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec + tv.tv_usec / 1000000.0;
}
int main()
{
char *buffer = (char *)malloc(SIZE);
if (!buffer)
{
printf("Failed to allocate memory\n");
return 1;
}
// 写入能力测试
double start = get_time();
for (size_t i = 0; i < SIZE; i += BLOCK_SIZE)
{
memset(buffer + i, 'a', BLOCK_SIZE);
}
double write_time = get_time() - start;
double write_speed = SIZE / (1024.0 * 1024.0 * 1024.0) / write_time;
// 读取能力测试
char temp[BLOCK_SIZE];
start = get_time();
// 在读循环中添加一个简单的校验,防止优化
volatile int sum = 0;
for (size_t i = 0; i < SIZE; i += BLOCK_SIZE)
{
memcpy(temp, buffer + i, BLOCK_SIZE);
sum += temp[0]; // 强制实际读取数据
}
printf("校验结果: %d\n", sum); // 使用sum防止编译器优化
double read_time = get_time() - start;
double read_speed = SIZE / (1024.0 * 1024.0 * 1024.0) / read_time;
printf("写入能力: %.2f GB/s\n", write_speed);
printf("读取能力: %.2f GB/s\n", read_speed);
free(buffer);
return 0;
}
将上面的内容保存为 memtest.c,使用下面的命令编译成可执行程序(编译优化级别选择 GCC 默认的 O2 即可):
gcc -O2 memtest.c -o memtest
程序执行后,就能够得到基础的内存读写性能了:
# ThinkPad-L14-Gen-1:~$ ./memtest
校验结果: 25427968
写入能力: 2.14 GB/s
读取能力: 526.06 GB/s
# ThinkPad-L14-Gen-1:~$ ./memtest
校验结果: 25427968
写入能力: 2.13 GB/s
读取能力: 526.06 GB/s
# ThinkPad-L14-Gen-1:~$ ./memtest
校验结果: 25427968
写入能力: 2.16 GB/s
读取能力: 426.47 GB/s
上面打印的日志中,我们能够看到,这台设备的内存写入性能在 2GB/s 出头,读取速度在 400~500GB/s 左右。
除了使用上面的程序来验证内存读写性能之外,我们可以还可以使用 Redis 自带的性能测试工具来了解读写性能。当我们安装好 Redis 后,通常情况下能够在系统软件目录或者 Docker 镜像中,找到 Redis-Benchmark 这个性能测试工具。
一般可以这样使用它:
# 50 并发请求,测试 10 万次 SET 和 GET 操作的性能
redis-benchmark -h localhost -p 6379 -t set,get -n 100000 -c 50
# 50 并发请求,测试 1kb 数据的写入性能,-d: 测试数据大小(bytes)
redis-benchmark -h localhost -p 6379 -t set -d 1000 -n 100000 -c 50
# 50 并发请求,测试 4kb 数据的写入性能,-d: 测试数据大小(bytes)
redis-benchmark -h localhost -p 6379 -t set -d 4000 -n 100000 -c 50
执行上面三个命令,我们将得到下面的结果:
====== SET ======
100000 requests completed in 1.11 seconds
50 parallel clients
3 bytes payload
keep alive: 1
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
multi-thread: no
Summary:
throughput summary: 89847.26 requests per second
latency summary (msec):
avg min p50 p95 p99 max
0.292 0.088 0.279 0.415 0.751 1.671
====== GET ======
100000 requests completed in 1.11 seconds
50 parallel clients
3 bytes payload
keep alive: 1
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
multi-thread: no
Summary:
throughput summary: 89766.61 requests per second
latency summary (msec):
avg min p50 p95 p99 max
0.287 0.104 0.279 0.407 0.455 1.151
====== SET ======
100000 requests completed in 1.27 seconds
50 parallel clients
1000 bytes payload
keep alive: 1
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
multi-thread: no
Summary:
throughput summary: 78678.20 requests per second
latency summary (msec):
avg min p50 p95 p99 max
0.339 0.104 0.319 0.455 0.775 1.935
====== SET ======
100000 requests completed in 1.23 seconds
50 parallel clients
4000 bytes payload
keep alive: 1
host configuration "save": 3600 1 300 100 60 10000
host configuration "appendonly": no
multi-thread: no
Summary:
throughput summary: 81037.28 requests per second
latency summary (msec):
avg min p50 p95 p99 max
0.328 0.096 0.311 0.455 0.799 2.039
我们可以将上面的 Redis 测试结果转换为和上面一样的内存吞吐数据,以最后测试的 4KB 数据场景下的 SET 操作数据为例:
81037.28 ops/s x 4KB = 324149120 bytes/s = 0.302 GB/s
这里的性能数据没有非常“亮眼”和许多因素有关,除了系统参数定向调优之外,还和我们使用的是藏在 Docker 后的 Redis 服务,Redis 的配置也没有定向优化,来适配大量数据写入的场景等等相关。
但即使如此,通过这个跑在老笔记本上的,性能弱化版的 Redis,我们一分钟也能写入 18GB 的数据。相信看到这里,你一定对 Redis 的性能有了一个量化的了解。
接下来,让我们逐步来进行优化。
从数据库表结构估算 Redis 数据量消耗
上文中提到,我们的设备的内存资源是受限的,远远小于整个数据量。所以,我们首先要考虑的是减少放在内存中的数据字段数量,最好只存我们刚需的字段。
通过使用 SQL 命令,可以得到我们要通过 Redis 优化,加速的数据库的完整表结构:
DESC data_table;
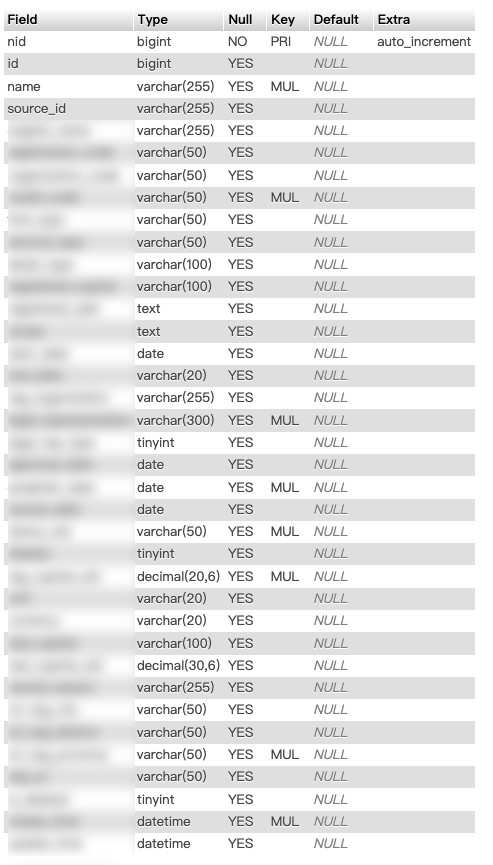
本文中提到的实际业务场景中,最常见的除了模糊匹配之外,更多的是基于几种 ID 进行的精准点查询,或者基于字符串名称进行的精准 ID 反查。所以,我们可以只存 ID 和 Name 、Source ID 相关的字段,其他的都让它们留在数据库中。
假设我们要实现可以通过 ID 查询 Name,通过 Source ID 查询 Name,通过 Name 反查 ID 的 Redis 缓存数据表。目前 ID 大概 8 字节,Source ID 平均假设 20 字节,Name 平均 50 字节,Redis Key 和一些序列化操作的开销算 10 字节,那么我们想存储 1 亿数据大概需要的内存资源量是:
100000000 * ((8+50)+(20+50)+(50+8)+10) = 100000000 * 196 Bytes = 18.25 GB
但如果我们按照最极端场景估算,假设 Source ID 占 255 字节,Name 占用 255 字节,想存储 1 亿数据大概需要内存资源是:
100000000 * ((8+255)+(255+255)+(255+8)+10) = 100000000 * 791 Bytes = 73.67 GB
幸运的是,数据大概率不需要都花费最大上限进行存储,它应该不会到 73.67 GB 这么大。但是通常情况下,考虑到服务器的正常运行,我们需要预留 30 ~ 40% 的冗余,哪怕是按照 18GB 使用量计算,我们也需要准备 25GB 的内存资源兜底。
实战开始
当然,Redis 程序本身也会占用一些内存资源,具体要花费多少内存来进行存储我们必须还是得跑几圈才知道。
编写数据导出程序
相比较我们直接从数据库中小批量的捞数据,相对效率更高的方式是将数据库中的数据先导出来,剥离掉和目标任务不相干的数据,减少后续操作过程中,总的硬盘读写的数据量和我们处理数据的程序所需要接触(序列化)的数据量。
目标数据源是 MySQL,我们可以先写一个简单的程序,通过 MySQL 命令行程序执行命令,依次将十个数据表中的数据导出为文本文件:
#!/bin/bash
# MySQL连接信息
HOST="10.11.12.233"
USER="root"
PASS="soulteary"
DB="base"
# 循环处理表 1-10
for i in {1..10}; do
mysql -h $HOST -u$USER -p$PASS $DB \
-e "SELECT id,name,source_id FROM base_$i" \
> base_${i}_source_ids.txt
done
将上面的程序保存为 export.sh,然后执行 bash export.sh,程序执行完毕,我们将得到包含类似下面内容的 10 个文本文件:
id name source_id
122466448 名称1 ea50ecfc63ff9fceaf62da300487ed22
122466452 名称2 eb88ecf3b53bb144709ea31bca1cd8fe
122466459 名称3 6bdab43c56f98b1c29d6f305052cb32d
导出的仅包含 ID 的文件尺寸不到 9GB:
# du -hs .
8.7G
好啦,有了更小规模的数据之后,我们就可以来折腾 Redis 的数据导入了。
编写输入导入程序
让我们简单的使用 Go 写一段处理程序,实现上面文章提到的需求,然后把数据送入 Redis 吧。
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"path/filepath"
"strings"
"sync"
"time"
"github.com/redis/go-redis/v9"
"golang.org/x/net/context"
)
var (
redisAddr = flag.String("redis", "localhost:6379", "Redis address")
redisDB = flag.Int("db", 0, "Redis database number")
redisPassword = flag.String("password", "", "Redis password")
batchSize = flag.Int("batch", 1000, "Batch size for Redis pipeline")
pattern = flag.String("pattern", "companies_*_source_ids.txt", "File pattern to process")
concurrent = flag.Int("concurrent", 3, "Number of concurrent file processors")
)
type FileProcessor struct {
client *redis.Client
wg sync.WaitGroup
}
func NewFileProcessor(addr string, db int, password string) *FileProcessor {
if password == "" {
return &FileProcessor{
client: redis.NewClient(&redis.Options{
Addr: addr,
DB: db,
}),
}
}
return &FileProcessor{
client: redis.NewClient(&redis.Options{
Addr: addr,
DB: db,
Password: password,
}),
}
}
func (fp *FileProcessor) processFile(ctx context.Context, filename string) error {
file, err := os.Open(filename)
if err != nil {
return fmt.Errorf("failed to open file %s: %v", filename, err)
}
defer file.Close()
scanner := bufio.NewScanner(file)
pipeline := fp.client.Pipeline()
count := 0
start := time.Now()
log.Printf("Started processing %s", filename)
for scanner.Scan() {
line := strings.TrimSpace(scanner.Text())
if line == "" {
continue
}
lines := strings.Split(line, "\t")
if len(lines) != 3 {
continue
}
id := lines[0]
name := lines[1]
source := lines[2]
// ID => Name
key := fmt.Sprintf("i:%s", id)
pipeline.Set(ctx, key, name, 0)
// Source => Name
key2 := fmt.Sprintf("s:%s", source)
pipeline.Set(ctx, key2, name, 0)
// name => ID
key3 := fmt.Sprintf("n:%s", name)
pipeline.Set(ctx, key3, id, 0)
count++
if count%*batchSize == 0 {
_, err := pipeline.Exec(ctx)
if err != nil {
return fmt.Errorf("failed to execute pipeline at count %d: %v", count, err)
}
pipeline = fp.client.Pipeline()
}
}
// 处理剩余的数据
if count%*batchSize != 0 {
_, err := pipeline.Exec(ctx)
if err != nil {
return fmt.Errorf("failed to execute final pipeline: %v", err)
}
}
duration := time.Since(start)
log.Printf("Finished processing %s: %d records in %v", filename, count, duration)
return scanner.Err()
}
func (fp *FileProcessor) ProcessFiles(ctx context.Context, pattern string) error {
files, err := filepath.Glob(pattern)
if err != nil {
return fmt.Errorf("failed to glob pattern %s: %v", pattern, err)
}
sem := make(chan struct{}, *concurrent)
errChan := make(chan error, len(files))
for _, file := range files {
fp.wg.Add(1)
go func(filename string) {
defer fp.wg.Done()
sem <- struct{}{} // get
defer func() { <-sem }() // release
if err := fp.processFile(ctx, filename); err != nil {
errChan <- fmt.Errorf("error processing %s: %v", filename, err)
}
}(file)
}
// wait everything is done
fp.wg.Wait()
close(errChan)
// check if any error
for err := range errChan {
if err != nil {
return err
}
}
return nil
}
func main() {
flag.Parse()
ctx := context.Background()
processor := NewFileProcessor(*redisAddr, *redisDB, *redisPassword)
start := time.Now()
log.Printf("Starting import with pattern: %s", *pattern)
if err := processor.ProcessFiles(ctx, *pattern); err != nil {
log.Fatalf("Failed to process files: %v", err)
}
duration := time.Since(start)
log.Printf("Import completed in %v", duration)
}
我们将上面的内容保存为 main.go,稍后使用。
接着,编写一个简单的程序,来将不同的文件导入不同的 Redis 的子 DB 中:
#!/bin/bash
# 基础配置
REDIS_HOST="10.11.12.233:6379"
CONCURRENT=24
DATA_PATH="/app/data-keyvalue"
# 遍历处理 DB 1-10
for i in {1..10}; do
# DB1 使用不同的 batch size,方便对比观察
if [ $i -eq 1 ]; then
BATCH=100
else
BATCH=1000
fi
echo "Processing DB $i..."
go run main.go \
-redis=$REDIS_HOST \
-db=$i \
-batch=$BATCH \
-concurrent=$CONCURRENT \
-pattern="$DATA_PATH/base_${i}_source_ids.txt"
done
上面的程序里,我们将不同的数据,使用串行逻辑,分别写入了不同的 Redis DB,如果有任何一个原始数据表发生更新,我们只需要维护和更新对应的 DB 即可,甚至也可以根据硬件的资源情况,将我们的 DB 切分到更小资源的机器上,从而降低业务执行成本。
将上面的程序保存为 importer.sh,然后执行 bash importer.sh,数据转化和导入 Redis 的工作就开始了:
Processing DB 1...
2024/11/20 07:55:44 Starting import with pattern: /app/source-ids/base_1_source_ids.txt
2024/11/20 07:55:44 Started processing /app/source-ids/base_1_source_ids.txt
2024/11/20 08:02:07 Finished processing /app/source-ids/base_1_source_ids.txt: 11823464 records in 6m22.783322336s
...
等待程序执行完毕后,所有的数据就都在 Redis 里啦。这个时候,别忘记执行一条命令,让 Docker 中的 Redis 将我们的数据持久化到磁盘上,方便之后服务哪怕重启也能够快速恢复内存中的数据:
docker exec -it redis redis-cli save
OK
分析 Redis 内存使用情况
所有数据都进入 Redis 之后,让我们来通过命令检查下 Redis 的数据状况:
docker exec -it redis redis-cli MEMORY STATS
命令执行完毕,能够得到 Redis 的细节数据:
1) "peak.allocated"
2) (integer) 42765795264
3) "total.allocated"
4) (integer) 40216662584
5) "startup.allocated"
6) (integer) 946288
...
47) "overhead.total"
48) (integer) 18354277320
49) "db.dict.rehashing.count"
50) (integer) 0
51) "keys.count"
52) (integer) 331326244
53) "keys.bytes-per-key"
54) (integer) 65
55) "dataset.bytes"
56) (integer) 21862385264
57) "dataset.percentage"
58) "54.36279296875"
59) "peak.percentage"
60) "94.03931427001953"
61) "allocator.allocated"
62) (integer) 40217409168
63) "allocator.active"
64) (integer) 40217747456
65) "allocator.resident"
66) (integer) 40811601920
67) "allocator.muzzy"
68) (integer) 0
69) "allocator-fragmentation.ratio"
70) "1.0000065565109253"
71) "allocator-fragmentation.bytes"
72) (integer) 262256
73) "allocator-rss.ratio"
74) "1.014765977859497"
75) "allocator-rss.bytes"
76) (integer) 593854464
77) "rss-overhead.ratio"
78) "0.9995198845863342"
79) "rss-overhead.bytes"
80) (integer) -19595264
81) "fragmentation"
82) "1.0143070220947266"
83) "fragmentation.bytes"
84) (integer) 575382392
仔细阅读上面的数据,可以了解到一些有趣的事实信息。
首先,是“内存使用情况”:
- 总分配内存 (total.allocated): 约 40.22GB (40,216,662,584 bytes)
- 峰值内存 (peak.allocated): 约 42.77GB (42,765,795,264 bytes)
- 实际驻留内存(allocator.resident): 约 40.81GB (40,811,601,920 bytes)
接着,是“数据集信息”:
- 数据集大小 (dataset.bytes): 约 21.86GB (21,862,385,264 bytes)
- 数据集占总内存百分比 (dataset.percentage): 54.36%
- 总键数量 (keys.count): 331,326,244 个
- 每个键平均字节数 (keys.bytes-per-key): 65 bytes
最后,是“内存碎片情况”等:
- 碎片率 (fragmentation): 1.0143 (约 1.43% 的碎片)
- 碎片大小 (fragmentation.bytes): 约 575.38MB (575,382,392 bytes)
- 内存使用率 (peak.percentage): 94.04%
- 开销总量 (overhead.total): 约 18.35GB (18,354,277,320 bytes)
从上面的数据来看,可以得到一些简单的结论:
- 实际数据集和我们估算的差不多,21.86G
- Redis 使用了接近峰值上限的内存量(94.04%)
- 内存使用率非常高,碎片率很低(1.43%)
- 实际数据占用了一半多一点,其他的都是系统开销
- 系统中存储了 3 亿多对键值对
在了解了内存使用情况后,让我们来思考下如何改进 Redis 的内存存储和查询效率。
改进写入算法提升数据存储效率
改善性能最简单的方法依旧还是从数据量入手,哪些参数是可以删减的:哪些数据只需要被查询,而不需要作为查询参数。其实在上面的场景中,只实现 Source ID 和 Name 查询 ID 数据即可,而不需要查询出所有数据,数据的 ID 也是不需要被直接作为查询参数使用的。通过这个改动,我们可以直接降低 1 亿条数据的存储。
其次,原始程序将数据根据文件拆分打散到不同的 Redis DB 中存储,虽然好处很多,尤其是实现了逻辑隔离,可以通过 FLUSH 来将指定 DB 清空,来快速的重建某个文件的数据。但是这些 DB 都是共享一个实例的 CPU 和内存资源的,无益于性能提升,并且出现热点问题的时候,也会因为负载过高,影响其他的 DB 数据获取,最后,如果我们想迁移云服务器,Cluster 模式不支持多 DB 模式。这次我们可以不打散数据到不同的 DB。
改进版本的程序并不难写:
package main
import (
"bufio"
"flag"
"fmt"
"log"
"os"
"path/filepath"
"strings"
"sync"
"time"
"github.com/redis/go-redis/v9"
"golang.org/x/net/context"
)
var (
redisAddr = flag.String("redis", "localhost:6379", "Redis address")
redisDB = flag.Int("db", 0, "Redis database number")
redisPassword = flag.String("password", "", "Redis password")
batchSize = flag.Int("batch", 1000, "Batch size for Redis pipeline")
pattern = flag.String("pattern", "companies_*_source_ids.txt", "File pattern to process")
concurrent = flag.Int("concurrent", 3, "Number of concurrent file processors")
bufferSize = flag.Int("buffer", 4096*1024, "File buffer size in bytes")
)
type FileProcessor struct {
client *redis.Client
wg sync.WaitGroup
errChan chan error
}
func NewFileProcessor(addr string, db int, password string) *FileProcessor {
opts := &redis.Options{
Addr: addr,
DB: db,
Password: password,
PoolSize: *concurrent * 2,
MinIdleConns: *concurrent,
MaxRetries: 3,
}
return &FileProcessor{
client: redis.NewClient(opts),
errChan: make(chan error, 100),
}
}
func (fp *FileProcessor) processFile(ctx context.Context, filename string) error {
file, err := os.Open(filename)
if err != nil {
return fmt.Errorf("failed to open file %s: %v", filename, err)
}
defer file.Close()
scanner := bufio.NewScanner(file)
scanner.Buffer(make([]byte, *bufferSize), *bufferSize)
pipeline := fp.client.Pipeline()
count := 0
batch := make([]string, 0, *batchSize*3) // Pre-allocate slice for batch
start := time.Now()
log.Printf("Started processing %s", filename)
for scanner.Scan() {
line := strings.TrimSpace(scanner.Text())
if line == "" {
continue
}
lines := strings.Split(line, "\t")
if len(lines) != 3 {
log.Printf("Skipping invalid line in %s: %s", filename, line)
continue
}
batch = append(batch, lines[0], lines[1], lines[2])
count++
if count%*batchSize == 0 {
if err := fp.processBatch(ctx, pipeline, batch); err != nil {
return err
}
batch = batch[:0] // Reset batch slice
}
}
// Process remaining records
if len(batch) > 0 {
if err := fp.processBatch(ctx, pipeline, batch); err != nil {
return err
}
}
if err := scanner.Err(); err != nil {
return fmt.Errorf("scanner error in %s: %v", filename, err)
}
duration := time.Since(start)
log.Printf("Finished processing %s: %d records in %v (%.2f records/sec)",
filename, count, duration, float64(count)/duration.Seconds())
return nil
}
func (fp *FileProcessor) processBatch(ctx context.Context, pipeline redis.Pipeliner, batch []string) error {
for i := 0; i < len(batch); i += 3 {
id, name, source := batch[i], batch[i+1], batch[i+2]
pipeline.Set(ctx, fmt.Sprintf("s:%s", source), id, 0)
pipeline.Set(ctx, fmt.Sprintf("n:%s", name), id, 0)
}
_, err := pipeline.Exec(ctx)
if err != nil {
return fmt.Errorf("failed to execute pipeline: %v", err)
}
return nil
}
func (fp *FileProcessor) ProcessFiles(ctx context.Context) error {
files, err := filepath.Glob(*pattern)
if err != nil {
return fmt.Errorf("failed to glob pattern %s: %v", *pattern, err)
}
// Create buffered channel for work distribution
filesChan := make(chan string, len(files))
for _, file := range files {
filesChan <- file
}
close(filesChan)
// Start workers
for i := 0; i < *concurrent; i++ {
fp.wg.Add(1)
go func() {
defer fp.wg.Done()
for filename := range filesChan {
if err := fp.processFile(ctx, filename); err != nil {
select {
case fp.errChan <- err:
default:
log.Printf("Error channel full, logging error: %v", err)
}
}
}
}()
}
// Wait for completion and collect errors
go func() {
fp.wg.Wait()
close(fp.errChan)
}()
var errors []error
for err := range fp.errChan {
errors = append(errors, err)
}
if len(errors) > 0 {
return fmt.Errorf("encountered %d errors: %v", len(errors), errors)
}
return nil
}
func main() {
flag.Parse()
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
processor := NewFileProcessor(*redisAddr, *redisDB, *redisPassword)
start := time.Now()
log.Printf("Starting import with pattern: %s", *pattern)
if err := processor.ProcessFiles(ctx); err != nil {
log.Fatalf("Failed to process files: %v", err)
}
duration := time.Since(start)
log.Printf("Import completed in %v", duration)
}
将上面的代码保存为 main.go 后,这次换一种执行程序的方式,使用下面的命令,调用 Go 来并行处理和写入数据:
go run main.go -redis=10.11.12.233:6379 -batch=1000 -concurrent=24 -pattern="/app/data-keyvalue/base_*.txt"
能够发现程序执行性能有了大幅的提升:
2024/11/20 13:56:34 Starting import with pattern: /app/data-keyvalue/base_*.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_6_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_10_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_4_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_3_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_1_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_8_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_9_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_7_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_2_source_ids.txt
2024/11/20 13:56:34 Started processing /app/data-keyvalue/base_5_source_ids.txt
2024/11/20 13:56:38 Skipping invalid line in /app/data-keyvalue/base_3_source_ids.txt: 6439393 xxxxx
2024/11/20 13:56:58 Skipping invalid line in /app/data-keyvalue/base_8_source_ids.txt: 10000000000999 xxxxx
2024/11/20 13:57:40 Skipping invalid line in /app/data-keyvalue/base_3_source_ids.txt: 537959 xxxxx
2024/11/20 13:59:50 Finished processing /app/data-keyvalue/base_10_source_ids.txt: 5900001 records in 3m16.351320703s (30048.19 records/sec)
2024/11/20 14:01:49 Skipping invalid line in /app/data-keyvalue/base_6_source_ids.txt: 6439393 xxxxx
2024/11/20 14:02:43 Finished processing /app/data-keyvalue/base_7_source_ids.txt: 11600002 records in 6m9.029283128s (31433.83 records/sec)
2024/11/20 14:02:43 Finished processing /app/data-keyvalue/base_6_source_ids.txt: 11600000 records in 6m9.099384636s (31427.85 records/sec)
2024/11/20 14:02:43 Finished processing /app/data-keyvalue/base_9_source_ids.txt: 11600001 records in 6m9.15178088s (31423.39 records/sec)
2024/11/20 14:02:44 Finished processing /app/data-keyvalue/base_4_source_ids.txt: 11700001 records in 6m10.441999587s (31583.89 records/sec)
2024/11/20 14:02:45 Finished processing /app/data-keyvalue/base_8_source_ids.txt: 11700000 records in 6m10.571234078s (31572.88 records/sec)
2024/11/20 14:02:46 Finished processing /app/data-keyvalue/base_2_source_ids.txt: 11800001 records in 6m11.645137088s (31750.72 records/sec)
2024/11/20 14:02:46 Finished processing /app/data-keyvalue/base_1_source_ids.txt: 11823464 records in 6m11.814580422s (31799.36 records/sec)
2024/11/20 14:02:46 Finished processing /app/data-keyvalue/base_3_source_ids.txt: 11799999 records in 6m11.859257456s (31732.43 records/sec)
2024/11/20 14:02:46 Finished processing /app/data-keyvalue/base_5_source_ids.txt: 11800001 records in 6m11.882250682s (31730.48 records/sec)
2024/11/20 14:02:46 Import completed in 6m11.885403981s
在多次实验后,这里有两个以往的经验实践是不适用的,因为我们存储的数据平均长度并不长,所以如果使用 Snappy 压缩算法进行存放,压缩反而会放大数据存储量。以及虽然我们使用 Hash 结构来替代单独的 String Key 可以减少数据量的存储占用,但是额外的索引数据,反而可能让我们最终的内存占用变的更多,并且查询效率没有当前这样高。
当我们处理好数据之后,再次执行命令,将 Redis 数据落盘保存。
# docker exec -it redis redis-cli save
OK
接着,进入 Redis 的目录,执行下面命令重启容器,让 Redis 运行在干净的新环境中:
docker compose down && docker compose up -d
再次分析 Redis 内存使用情况
等待 Redis 启动完毕,数据都被 Redis 重新加载,内存使用量稳定后。让我们来再次通过命令再次检查下 Redis 的数据状况:
docker exec -it redis redis-cli MEMORY STATS
命令执行完毕,我们得到 Redis 的细节数据:
1) "peak.allocated"
2) (integer) 20671135744
3) "total.allocated"
4) (integer) 20671135792
5) "startup.allocated"
6) (integer) 946192
...
19) "functions.caches"
20) (integer) 192
21) "db.0"
22) 1) "overhead.hashtable.main"
2) (integer) 11490356056
3) "overhead.hashtable.expires"
4) (integer) 216
23) "overhead.db.hashtable.lut"
24) (integer) 3221225472
25) "overhead.db.hashtable.rehashing"
26) (integer) 1073741824
27) "overhead.total"
28) (integer) 11491302656
29) "db.dict.rehashing.count"
30) (integer) 1
31) "keys.count"
32) (integer) 206728257
33) "keys.bytes-per-key"
34) (integer) 44
35) "dataset.bytes"
36) (integer) 9179833136
37) "dataset.percentage"
38) "44.41097640991211"
39) "peak.percentage"
40) "100"
41) "allocator.allocated"
42) (integer) 20671675320
43) "allocator.active"
44) (integer) 20671934464
45) "allocator.resident"
46) (integer) 20958089216
47) "allocator.muzzy"
48) (integer) 0
49) "allocator-fragmentation.ratio"
50) "1.0000088214874268"
51) "allocator-fragmentation.bytes"
52) (integer) 183112
53) "allocator-rss.ratio"
54) "1.0138427019119263"
55) "allocator-rss.bytes"
56) (integer) 286154752
57) "rss-overhead.ratio"
58) "0.999789297580719"
59) "rss-overhead.bytes"
60) (integer) -4415488
61) "fragmentation"
62) "1.0136700868606567"
63) "fragmentation.bytes"
64) (integer) 282576200
在进一步调整数据查询方法,精简数据量之后,新的程序只需要 20.67GB (total.allocated) 的内存总量,相比旧程序使用 40.22GB 的内存量,使用上降低了48.6%,相比旧程序减少了 1 亿 3 千万的键值,并且每个键的平均长度从 65 bytes 降低到了 44 bytes,数据集的实际空间占用,也从 21.86GB 降低到了 9.18GB (dataset.bytes)。
TLDR,文章写到这里,我们可以只用一根 32GB 的内存(价格 300 元左右),提供所有数据的查询使用服务啦。
数据的查询和使用
至于数据的查询使用,也非常简单,一段不到 100 行的模块就行:
package Enterprise
import (
"fmt"
"github.com/redis/go-redis/v9"
"golang.org/x/net/context"
)
type FileProcessor struct {
client *redis.Client
}
func NewFileProcessor(addr string, db int, password string) *FileProcessor {
opts := &redis.Options{
Addr: addr,
DB: db,
}
if password != "" {
opts.Password = password
}
return &FileProcessor{
client: redis.NewClient(opts),
}
}
func (fp *FileProcessor) QueryBySource(ctx context.Context, source string) (string, error) {
key := fmt.Sprintf("s:%s", source)
id, err := fp.client.Get(ctx, key).Result()
if err == redis.Nil {
return "", fmt.Errorf("source not found: %s", source)
}
if err != nil {
return "", fmt.Errorf("redis error: %v", err)
}
return id, nil
}
func (fp *FileProcessor) QueryByName(ctx context.Context, name string) (string, error) {
key := fmt.Sprintf("n:%s", name)
id, err := fp.client.Get(ctx, key).Result()
if err == redis.Nil {
return "", fmt.Errorf("name not found: %s", name)
}
if err != nil {
return "", fmt.Errorf("redis error: %v", err)
}
return id, nil
}
// BatchQueryBySource queries multiple sources in a single pipeline
func (fp *FileProcessor) BatchQueryBySource(ctx context.Context, sources []string) (map[string]string, error) {
pipe := fp.client.Pipeline()
cmds := make(map[string]*redis.StringCmd, len(sources))
for _, source := range sources {
key := fmt.Sprintf("s:%s", source)
cmds[source] = pipe.Get(ctx, key)
}
_, err := pipe.Exec(ctx)
if err != nil && err != redis.Nil {
return nil, fmt.Errorf("pipeline error: %v", err)
}
results := make(map[string]string, len(sources))
for source, cmd := range cmds {
id, err := cmd.Result()
if err != redis.Nil {
results[source] = id
}
}
return results, nil
}
上面的模块简单,具体调用也就更简单了:
ctx := context.Background()
processor := Enterprise.NewFileProcessor(redisAddr, numOfDB, redisPassword)
// 使用 Source ID 进行查询
queryBySource, _ := processor.QueryBySource(ctx, "ea50ecfc63ff9fceaf62da300487ed22")
// 使用 公司名称 进行查询
queryByName, _ := processor.QueryByName(ctx, "公司的工商名称")
// 使用 多个 Sources 进行数据查询
queryBySources, _ := processor.BatchQueryBySource(ctx, []string{"ea50ecfc63ff9fceaf62da300487ed22", "eb88ecf3b53bb144709ea31bca1cd8fe"})
最后
好了,这篇文章就先写到这里吧。
–EOF