日常工作中,总会遇到一些需要和一些和“批量生成图片”相关的事情,尤其是在需要做内容传播的场景下:毕竟图片更直观、更有冲击力。
- 手头有一堆招聘需求,但是平台允许发布的字数有限,没关系,可以使用九宫格图片大法,把内容当长图发出来,但是制作长图还需要考虑排版,纯代码实现太过繁琐。
- 举办完一场活动,需要讲师分享内容给更多人,让更多的人知道这个活动,传播一张稍微有设计感的图片到朋友圈,这个时候我们需要制作和讲师相关的传播图片。
- 写了一篇博客,但是微博等平台排版全乱,换成长图传播才能保留格式等等。
网上常常会推崇使用 node canvas / webgl / web canvas 来解决问题。在我看来,大可不必,其实使用 Node.js 写几十行脚本搭配无头浏览器就能搞定问题。那么下面就来聊聊,如何编写简单可依赖的 Node 脚本。
写在前面
很多时候,我们会沉迷于使用某一门语言、某一种技术解决所有问题,虽然对于程序维护来说成本很低,但是在执行效率上来看,就得不偿失了。
当然,如果是简单纯粹的内容,比如访客签名、二维码生成,就另当别论了,不需要考虑复杂排版、几乎不需要对内容风格进行定制,比如我之前提过的:
让我们先从最简单的开始讲起,批量生成招聘需求图片(重视排版)。
批量生成招聘需求图片
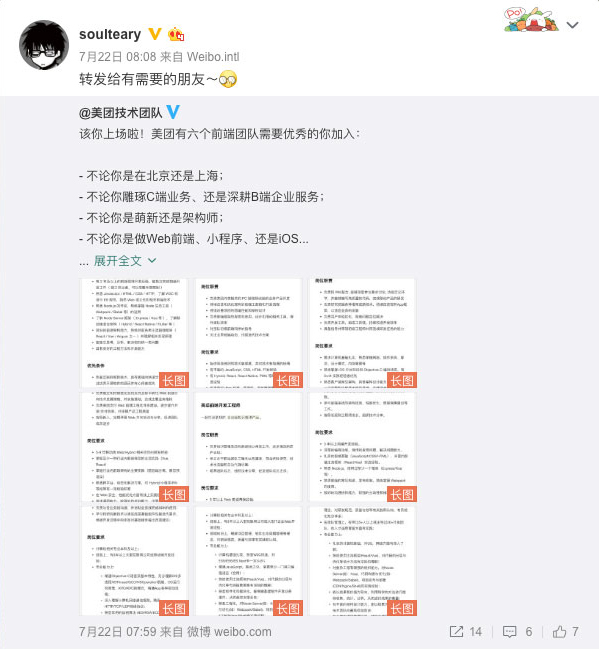
招聘需求类的图片重在内容排版,特别适合使用 Markdown 书写,配合 Hugo / Hexo 之类的静态网站生成工具生成简洁漂亮的页面,然后再通过截图等方式得到我们要的结果。
以 Hugo 为例,将简历文案准备好之后,放置在 content/posts 下,目录结构如下:
.
├── archetypes
│ └── default.md
├── config.toml
├── content
│ └── posts
│ ├── 招聘岗位A.md
│ ├── 招聘岗位B.md
│ ├── 招聘岗位C.md
│ ├── 招聘岗位D.md
│ └── 招聘岗位E.md
├── layouts
├── static
└── themes
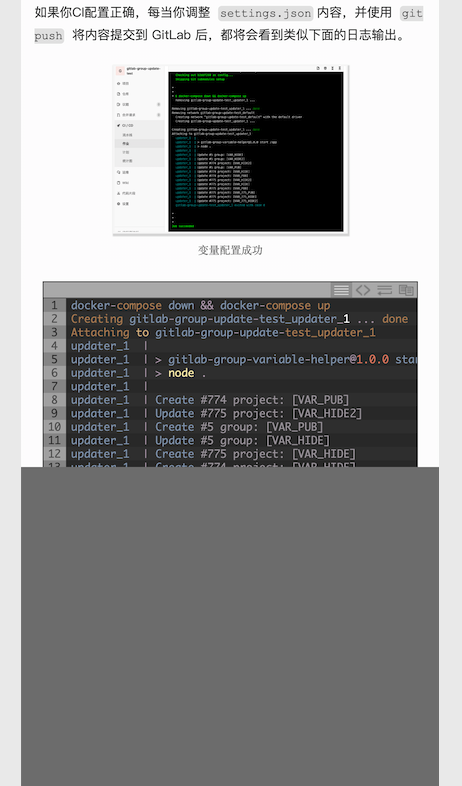
接着执行 hugo server,你将看到类似下面的日志输出:
hugo server
| ZH-CN
+------------------+-------+
Pages | 18
Paginator pages | 0
Non-page files | 0
Static files | 12
Processed images | 0
Aliases | 1
Sitemaps | 1
Cleaned | 0
Total in 24 ms
Watching for changes in /Users/soulteary/work/hugo-jd/jd/{content,data,layouts,static,themes}
Watching for config changes in /Users/soulteary/work/hugo-jd/jd/config.toml
Environment: "development"
Serving pages from memory
Running in Fast Render Mode. For full rebuilds on change: hugo server --disableFastRender
Web Server is available at http://localhost:1313/ (bind address 127.0.0.1)
Press Ctrl+C to stop
使用浏览器打开 localhost:1313,便能看到排版还算过得去的页面了。

接着稍微写几行 CSS 代码,做下移动端适配,然后输出成图片就大功告成了,但如果你想获得移动设备(尤其是高分屏)上阅读体验还不错的图片,光是用系统截图快捷键或是普通截图软件“喀嚓”截屏怕是达不到需求,感兴趣的同学可以了解下 DPR 。
所以截图的时候需要模拟高分屏设备进行图片截取,比如下面这段不到 20 行的 Node.js 脚本所做的一样:
'use strict';
const puppeteer = require('puppeteer');
const { 'iPhone X': deviceModel } = require('puppeteer/DeviceDescriptors');
const { readFileSync } = require('fs');
const links = readFileSync('./target.txt', 'utf-8').split('\n').filter(n => n);
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.emulate(deviceModel);
for (let i = 0, j = links.length; i < j; i++) {
await page.goto(links[i]);
await page.screenshot({ path: `./jd-${i}.png`, fullPage: true });
}
await browser.close();
})();
这段脚本模拟了高分屏设备 iPhone X 访问页面时的状况,然后通过 puppeteer 所提供的截图能力,生成我们所需要的图片。
想使用这段图片生成脚本,还需要准备一个 target.txt 文件,把需要生成图片的页面地址一行一行的写在文件中:
http://localhost/page/1.html
http://localhost/page/2.html
http://localhost/page/3.html
...
如果你顺利的话,执行 node 你的图片脚本.js 就能得到类似下面的结果啦。

批量生成朋友圈传播图

刷朋友圈的时候,常常能看到有一些朋友发来稍微有些设计感的活动宣传图片。这类图片其实也可以批量生成,但和上面的例子有些不同,所以要采取不同的策略。
这类传播图片首先文案不多,不需要相对复杂又统一的风格排版;图片和图片之间文案差异相对较小,几乎只有“名字”、“头像”、“传播短文案”、“配色”有些许不同;需要生成的图片数量很多,如果还是采取预先编写一堆 md 文档,怕不是会敲键盘敲到手麻。
图片中涉及到的人,我们可以使用某些结构语法进行描述,会省事的多,比如下面这样:(当然你也可以一行一位,找个和内容不撞车的分隔符进行内容分割)
[
{ name: '小明', title: '讲师' },
{ name: '小刚', title: '嘉宾' }
]
有了可以让程序操作的结构化的人员数据,我们接着将图片使用前端技术“画出来”(传说中的切图)。上文提过,这类图片只有少量信息不同,比如这里只有名字和身份有区别,所以我们可以像下面这样描述“图片”结构。(这里偷个懒,用伪代码代替,不实现样式啦。)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<h1>我是040期沙龙$TITLE $NAME</h1>
<p>我来自美团技术团队,2018美团技术沙龙资源合辑奉上。</p>
</body>
</html>
结构中的 $TITLE, $NAME 就是我们想动态替换的内容,如果我们直接使用浏览器打开模版,会看到下面的结果。

如何能让模版内容如我们所愿“动态变化”起来呢?这里需要借助 http 这个模块,在用户获取模版的时候进行动态内容替换。为了简单,我这里以 express 为例,只需要 20~30 行就能搞定问题。
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => res.redirect('/0'));
const template = `<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
</head>
<body>
<h1>我是040期沙龙$TITLE $NAME</h1>
<p>我来自美团技术团队,2018美团技术沙龙资源合辑奉上。</p>
</body>
</html>`;
const personsData = [
{ name: '小明', title: '讲师' },
{ name: '小刚', title: '嘉宾' }
];
app.get('/:id', (req, res) => {
const { id } = req.params;
const { name, title } = personsData[id];
return res.send(template.replace('$NAME', name).replace('$TITLE', title));
})
app.listen(port, () => console.log(`App listening on port ${port}!`));
将代码保存为 web.js,然后执行 node web.js ,打开浏览器,访问 localhost:3000,或者 localhost:3000/0/localhost:3000/1模版的信息就动态化起来啦。
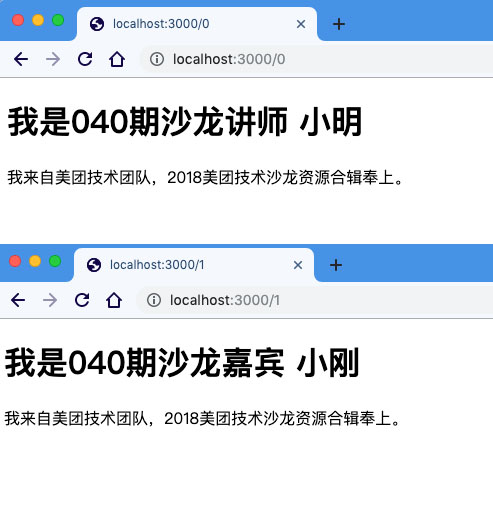
最后适当调整 CSS ,以及参考上文中批量生成图片的脚本,就能得到本小节开头的那种图片啦。
生成博客文章图片

你或许会好奇,生成博客图片和文章第一节中的图片有什么不同么?
不同主要有两点:
- 实际截取内容的时候,有一些元素需要被隐藏或者“跳过”,避免最终成图效果不佳。
- 博客文章一般长度都很长,所以生成的图片尺寸普遍比较大,某些平台限制图片单张尺寸、并且
puppeteer在生成超长图片时,会“花屏”。
如何避免截取到不必要的元素

像上图中用红色线框圈出的部分,不太希望在图片生成的过程中也被“记录”下来。如果是在浏览器中,可以在页面中执行 JavaScript 代码来删除这些元素,解决问题,比如:
const selector = "#J_footer-container,.page-navigation-container,.page-comments-container";
const elements = document.querySelectorAll(selector);
for (let i = 0; i < elements.length; i++) {
elements[i].parentNode.removeChild(elements[i]);
}
当然,结合 puppeteer 需要一些小小的改造:
'use strict';
const puppeteer = require('puppeteer');
const { 'iPhone X': deviceModel } = require('puppeteer/DeviceDescriptors');
const { readFileSync } = require('fs');
const targetLinks = readFileSync('./target.txt', 'utf-8').split('\n').filter(n => n);
const elementsRemoved = "#J_footer-container,.page-navigation-container,.page-comments-container";
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.emulate(deviceModel);
for (let i = 0, j = targetLinks.length; i < j; i++) {
await page.goto(targetLinks[i]);
await page.evaluate((selector) => {
const elements = document.querySelectorAll(selector);
for (let i = 0; i < elements.length; i++) {
elements[i].parentNode.removeChild(elements[i]);
}
}, elementsRemoved)
await page.screenshot({ path: `./blog-${i}.png`, fullPage: true });
}
await browser.close();
})();
将代码保存为 blog.js,然后执行 node blog.js,如果文章不是特别长的话,你就能成功得到本小节开头的博客文章长图了。
将长图分割避免图片生成错误
但是如果你想生成图片的文章特别长,会得到下面的结果:一张没有生成完毕的图片。
4月份的时候和 @貘大 有请教过,这个截图的 Bug 其实来自Google 官方的一次提交。
DevTools: capture full page screenshot renders blank page for pages higher than 0x4000px.
Bug: 831773
Change-Id: Ia5dfad17af526b495c38d6827292364a1d505dba
TBR: dgozman
Reviewed-on: https://chromium-review.googlesource.com/1010476
Commit-Queue: Pavel Feldman <pfeldman@chromium.org>
Reviewed-by: Pavel Feldman <pfeldman@chromium.org>
Reviewed-by: Dmitry Gozman <dgozman@chromium.org>
Cr-Commit-Position: refs/heads/master@{#550264}
如下图所示,官方出于性能考虑,限制了页面全屏模式下获取的图片高度,感兴趣的同学可以围观代码提交地址。
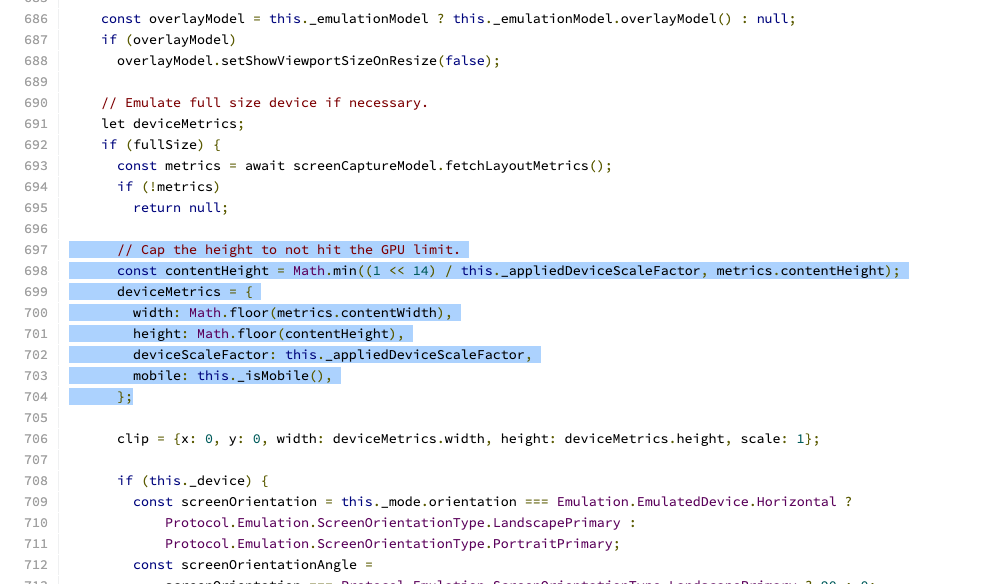
解决方案也很简单:自己编译一个 puppeteer 并去掉限制,或者更简单一些,将图片切割为若干块。
代码实现并不难,只需要在之前的代码基础上再多写十行,就能解决问题了。
'use strict';
const puppeteer = require('puppeteer');
const { 'iPhone X': deviceModel } = require('puppeteer/DeviceDescriptors');
const { readFileSync } = require('fs');
const links = readFileSync('./target.txt', 'utf-8').split('\n').filter(n => n);
const elementsRemoved = "#J_footer-container,.page-navigation-container,.page-comments-container";
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.emulate(deviceModel);
for (let i = 0, j = links.length; i < j; i++) {
await page.goto(links[i]);
await page.evaluate((selector) => {
const elements = document.querySelectorAll(selector);
for (let i = 0; i < elements.length; i++) {
elements[i].parentNode.removeChild(elements[i]);
}
}, elementsRemoved);
const { width: viewWidth, height: viewHeight } = page.viewport();
const pageHeight = await page.evaluate(_ => document.body.scrollHeight);
const dpr = await page.evaluate('window.devicePixelRatio');
const maxHeight = viewHeight * 8;
const splitCount = Math.ceil(pageHeight / maxHeight);
const lastViewHeight = pageHeight - ((splitCount - 1) * maxHeight)
for (let i = 1; i <= splitCount; i++) {
await page.screenshot({
clip: {
x: 0, y: maxHeight * (i - 1), width: viewWidth,
height: i !== splitCount ? maxHeight : lastViewHeight
},
path: `./out/split-${i}-@${dpr}x.png`
});
}
}
await browser.close();
})();
将上面的代码保存为 split.js ,然后执行 node split.js 就能获取一张正常的图片啦。

最后
如果你阅读过我的其他文章,会发现我一直在尝试使用简短代码和简单方案去解决我们日常中遇到的许多看似复杂的需求。
其实很多时候,这些需求并不复杂,只要你愿意静下心来把它进行合理拆分,用简单可依赖的方案逐步击破就完事了。
但是做事的人往往陷入自己的固有知识陷阱中,把事情想的太过复杂、实施的太过复杂,以至于后续项目加入成本过高、难以维护。
如果你看到了这里,希望你在做事的过程中,可以多想想有没有什么更简单的方式解决你当前手头的问题,而不是一味追求“同构、高大上的方案”。
共勉。
–EOF