本篇文章聊聊 GitHub 开放数据集的获取和整理,分享一些数据整理的细节技巧,以及一些相对粗浅的数据背后的事情。
写在前面
分析 GitHub 上的项目和开发者获取是深入、真实的了解开源世界演进的方法之一。
在 GHArchive 项目中,我们能够看到目前全球有至少二十~三十个基于 GitHub 进行分析的开源项目,它们基于不同的维度、提供了不同的功能,甚至有一些项目因为年代久远,已经下线成为了“互联网活化石”的一部分。如果你感兴趣,可以翻阅文末“其他”小节,了解这部分的内容。
在去年 7 月份,我曾经发过一条微博,提到我想做一个有趣的小工具,来提供下面的能力:
相比较单纯的 “count”,我更希望能够折腾出一个最少资源依赖下的,能够快速输出“相似的人”、“有相似潜力的项目”、“快速判断这个项目刷 star 刷了多少” 这类报告。 当然,可能只用 CH ,目前还做不到,所以不排除要再引入一些其他的黑科技。

2TB 左右(2011~2022)的 GitHub 的开放数据集,对于我们来说,其实是一个非常不错的测试数据,基于真实数据,尺寸大小也合适用于一般规模的数据分析:可以用于生产环节测试和验证数据分析工具的可用性和架构设计是否靠谱,性能是否能够符合预期。
在写程序之前,我们先来了解下如何获取 GitHub 某一时刻的公开数据。
获取 GitHub 过去时刻的公开数据
GHArchive 项目提供了自 2011 年 2月 12 日到现在为止的 GitHub 开源相关事件信息,并以小时为粒度进行了归档。
想要获取某一天的某一时刻的数据,比如 “2020 年 2 月 2 日 晚上 20 点”,可以使用下面的命令:
wget https://data.gharchive.org/2020-02-02-20.json.gz
想要获取完整的一天的数据,需要枚举当天的 24 个小时,类似这样:
# wget https://data.gharchive.org/2020-02-02-{0..23}.json.gz
wget https://data.gharchive.org/2020-02-02-0.json.gz
wget https://data.gharchive.org/2020-02-02-1.json.gz
wget https://data.gharchive.org/2020-02-02-2.json.gz
...
wget https://data.gharchive.org/2020-02-02-23.json.gz
同理,想要获取一个月的数据,比如 “2020 年 1 月份”,需要枚举该月所有日期的 24 个小时:
# wget https://data.gharchive.org/2020-01-{01..31}-{0..23}.json.gz
wget https://data.gharchive.org/2020-01-01-0.json.gz
wget https://data.gharchive.org/2020-01-01-1.json.gz
wget https://data.gharchive.org/2020-01-01-2.json.gz
...
wget https://data.gharchive.org/2020-01-02-23.json.gz
wget https://data.gharchive.org/2020-01-02-0.json.gz
...
wget https://data.gharchive.org/2020-01-31-22.json.gz
wget https://data.gharchive.org/2020-01-31-23.json.gz
如果想要获取一年,或者几年的数据,也是类似的。
因为想要进行完整的数据分析,获取全量的数据自然会更好一些,所以我们需要枚举所有日期的数据:大概包含 10 万多条数据集的下载地址。
虽然这个数据量不大,但是上万个这类地址生成的工作,自然是用程序来做更为合适。
批量生成 GitHub 数据集的下载链接
这里,我们先来获取从 2011 年,自 GitHub 有数据记录以来到 2022 年的全部数据。很久不写 Node.js ,这次就用 Node 来实现程序吧:
process.env.TZ = "Etc/Universal"; // UTC +00:00
const { writeFileSync } = require("fs");
const config = {
timeStart: new Date("2011-02-12 00:00:00") - 0,
timeEnd: new Date("2022-12-31 23:00:00") - 0,
interval: 60 * 60 * 1000, // 1h
};
let time = config.timeStart;
let result = [];
let count = 0;
while (time <= config.timeEnd) {
timestamp = new Date(time)
.toISOString()
.replace(/(\d{4}-\d{2}-\d{2})T(\d{2}):.+/, "$1-$2")
.replace(/0(\d{1})$/, "$1");
result.push(`https://data.gharchive.org/${timestamp}.json.gz`);
time += config.interval;
count++;
}
writeFileSync("./urls.txt", result.join("\n"));
console.log(`${count} datasets.`);
在上面的程序中,我们使用一个 while 循环,来枚举自 2011 年 2月 12 日开始,到 2022 年 12 月 31 日结束的所有包含“小时”的时刻。
将上面的程序保存为:generate.js,执行 node generate.js ,当程序执行完毕,输出的日志中将告知我们,完成了 10 万多条数据的下载地址的生成。这些即将下载的数据集中包含了至少五十亿条 GitHub 平台上的各种公开活动信息。
# node generate.js
104184 datasets.
我们可以使用 head 命令,来预览生成的文件的内容:
# head urls.txt
https://data.gharchive.org/2011-02-12-0.json.gz
https://data.gharchive.org/2011-02-12-1.json.gz
https://data.gharchive.org/2011-02-12-2.json.gz
...
快速下载 GitHub 数据集
想要尽可能短时间完成托管在海外服务器的 10 万个文件的下载,有一些比较靠谱的方法,可以选择或组合使用:
- 准备一条大下行的宽带,不要让宽带或者内网的其他网络活动影响数据获取的效率。(我使用了一条 1G 的家用宽带)
- 下载的时候,开启多任务下载,而非顺序的串行下载。(考虑服务端压力,我只开了 10 个并发)
- 使用国内云服务器,搭配对象存储和 CDN 进行中转。(云服务器的网络带宽小,但是连通质量是好于家宽的,搭配 CDN 的大带宽,可以作为低成本取回数据的方案)
如果你没有上述条件也没有问题,无非数据准备时间稍微久一些罢了。
在下载数据的时候,我推荐使用 aria2 替代 wget 或者 curl 来完成数据下载。相比较 wget 或 curl ,aria2 天然支持多任务并行,能够更好的利用带宽和设备性能,缩短下载时间。 wget 在不同发行版的不同版本,对于并行下载的支持是不同的,搭配 xargs 或 parallel,以及 bash 来完成批量下载不是不行,但是毕竟还是麻烦不是么?
安装 aria2 很简单:
# macOS
brew install aria2
# ubuntu / debian
apt-get update && apt-get install -y aria2
使用 aria2 读取我们准备好的等待下载的数据集,开启 10 个任务的并行下载更简单:
aria2c -x 10 -i urls.txt
当 aria2 完成下载之后,我们还能够得到简单的下载报告:
2a7c02|OK | 9.2MiB/s|/data/2021/2021-12-31-21.json.gz
6dcf29|OK | 10MiB/s|/data/2021/2021-12-31-23.json.gz
6088b7|OK | 3.3MiB/s|/data/2021/2021-12-31-22.json.gz
463d0c|OK | 1.6MiB/s|/data/2021/2021-12-31-19.json.gz
deebcb|OK | 852KiB/s|/data/2021/2021-12-31-15.json.gz
39ced0|OK | 571KiB/s|/data/2021/2021-12-31-20.json.gz
Status Legend:
(OK):download completed.
不过,只是执行下载,并不能保障我们得到的数据是完整和正确的:文件数量上和文件完整性上。
所以,我们还需要做两个额外工作:确认数据是否下载全了,以及确认下载的文件都是完整的。
补全未下载完的 GitHub 数据集
当我们“完成” GitHub 数据集的下载之后,可以先来统计下已下载完毕的数据文件的总数:
# find . -type f -name '*.json.gz' | wc -l
103663
可以看到首次下载,得到了共计 10 万 3 千多个文件,和上文中我们生成的数据集下载地址的总数是不匹配的,相差 521 条。
// 103663 目前数据集数量
// 104184 理论数据集数量
造成数据集文件数量缺少的原因,可能是因为网络不稳定、目标服务器故障、下载程序 aria2 的程序问题,也可能是本身 GHArchive 就缺少这个数据(GitHub 当时挂了)。
不论原因如何,最好还是要进行一次数据补齐操作,首先,就需要获取已经完成下载的文件清单。
获取已下载的数据文件清单
使用 find 指定文件后缀,搜索保存下载文件的目录,能够得到包含完整地址的数据集文件列表。
# find . -type f -name '*.json.gz'
./2019/2019-01-14-3.json.gz
./2019/2019-02-05-12.json.gz
./2019/2019-01-01-9.json.gz
./2019/2019-08-05-0.json.gz
./2019/2019-09-19-15.json.gz
...
为了方便后续程序处理,我们可以使用 awk 来处理下列表内容,剔除掉目录信息,只留下文件名称。
# find . -type f -name '*.json.gz' | awk -F "/" '{print $NF}'
2019-03-15-11.json.gz
2019-04-23-1.json.gz
2019-12-02-5.json.gz
2019-11-17-17.json.gz
2019-11-16-1.json.gz
...
调整命令,将已下载的文件保存到 download.txt 文件中,以备后用。
find . -type f -name '*.json.gz' | awk -F "/" '{print $NF}' > download.txt
使用 Diff 检测“漏下”的 GitHub 数据集
这里,我们可以使用一个简单的方法,来快速从十万个文件中,找到因为网络请求出错,漏下的数据集。
首先,使用 cat | sort 将下载列表和已经下载完毕的文件列表,分别进行重新排序,然后保存为 a.txt 和 b.txt:
cat urls.txt | sort > a.txt
cat download.txt | sort > b.txt
直接使用 diff 对比两个文件,我们将得到类似下面的结果:
diff a.txt b.txt
8,10d7
< 2020-08-05-0.json.gz
< ...
所以,我们可以先使用 diff 命令来获得两个文件的差异,然后使用 grep 和 awk 过滤和得到需要下载的文件的名称:
diff a.txt b.txt | grep '<' | awk -F '< ' '{print $2}' > not-download.txt
当我们得到了需要补充下载的文件列表之后,继续使用 aria 进行下载就好了:
aria2c -x 10 -i not-download.txt
检测下载文件的完整性
虽然 GHArchive 没有提供每一个数据集压缩包的校验文件,但是,我们可以通过 gzip 命令来对每一个数据集文件进行完整性校验。比如这样:
gzip -t -v 2011-11-11-11.json.gz
2011-11-11-11.json.gz: OK
批量检测数据集的完整性
面对十万个文件,我们可以用一段简单的 bash 组合来进行批量文件检测,并把基础呢结果保存在文件中。
find . -type f -name '*.json.gz' | xargs -I {} gzip -v -t {} 2>&1 | tee verify.txt
这里可以考虑将文件拆分,然后并行执行命令,来提高检测效率。打开文件,我们能够看到类似下面的执行结果:
./2011-12-31-3.json.gz: OK
./2011-12-31-4.json.gz: OK
./2011-12-31-5.json.gz: OK
...
当然,考虑到执行效率,我们还可以在 xargs 后添加 -P 参数,来进行并行任务计算。比如将上面的命令改写为 xargs -I {} -P 4 gzip -t -v {} ...,程序就将自动负载到 4 颗不同的 CPU 上进行计算,而不需要我们进行手动拆分列表了。这里需要注意 -P 命令和 linux、macOS 版本中使用的 xargs 命令版本有关,不是每一个版本都支持这个参数,有一些“兼容性”问题。
下面是在一台 4c8t 设备中 xargs 不同参数的效率对比:
# 0.01s user 0.02s system 0% cpu 26.518 total
xargs -I {} gzip -t -v {} 43.90s user 7.40s system 98% cpu 52.068 total
# 0.01s user 0.02s system 0% cpu 6.968 total
xargs -P 4 -I {} gzip -t -v {} 45.58s user 7.88s system 393% cpu 13.598 total
# 0.01s user 0.02s system 0% cpu 4.874 total
xargs -P 8 -I {} gzip -t -v {} 62.47s user 10.79s system 770% cpu 9.506 total
# 0.01s user 0.02s system 0% cpu 9.239 total
xargs -P 4 -I {} gzip -d {} 50.38s user 18.09s system 374% cpu 18.281 total
# 0.01s user 0.02s system 0% cpu 8.636 total
xargs -P 8 -I {} gzip -d {} 61.34s user 21.36s system 466% cpu 17.742 total
在执行完所有文件的校验之后,我们可以使用 grep -v "OK" 来筛选出校验未通过,需要重新下载的文件。
# cat verify.txt | grep -v "OK"
./2011-02-16-18.json.gz:
gzip: ./2011-02-16-18.json.gz: invalid compressed data--crc error
./2013-05-16-1.json.gz:
gzip: ./2013-05-16-1.json.gz: invalid compressed data--crc error
gzip: ./2013-05-16-1.json.gz: invalid compressed data--length error
./2013-10-13-4.json.gz:
gzip: ./2013-10-13-4.json.gz: invalid compressed data--crc error
./2013-10-15-10.json.gz:
gzip: ./2013-10-15-10.json.gz: invalid compressed data--crc error
./2017-06-19-18.json.gz:
gzip: ./2017-06-19-18.json.gz: unexpected end of file
./2017-08-31-9.json.gz:
gzip: ./2017-08-31-9.json.gz: invalid compressed data--crc error
...
整理需要重新下载的文件
先使用 grep 将校验出错的文件结果保存至新的文件。
cat verify.txt | grep -v "OK" > error.txt
我们可以使用 awk 和 grep 以及 sed 抽取需要重新下载的数据集的文件名,然后使用 sed 组装待下载的数据集下载地址:
cat error.txt | awk -F " " '{print $NF}' | grep ".json.gz" | sed -e 's/:$//g' | awk -F "/" '{print $NF}' | sed -e 's#^#https://data.gharchive.org/#'
命令执行完毕,我们能够得到类似下面的下载地址列表:
https://data.gharchive.org/2011-02-16-18.json.gz
https://data.gharchive.org/2013-05-16-1.json.gz
https://data.gharchive.org/2013-10-13-4.json.gz
...
将下载出现错误的文件保存到新的下载列表中,然后使用 aria2 对这些文件进行重新下载,再次进行校验,就能够确保下载的数据都是完整的了:
cat error.txt | awk -F " " '{print $NF}' | grep ".json.gz" | sed -e 's/:$//g' | awk -F "/" '{print $NF}' | sed -e 's#^#https://data.gharchive.org/#' > download.txt
ariac -x 10 -i download.txt
关于 GitHub 完整数据集的获取,大概就这么多事情需要注意。
其他:聊聊 GitHub 和它的公开数据集
接下来,聊聊 GitHub 和它的数据集背后的一些故事。
GitHub 蓬勃的发展状况

GitHub 是这个星球上,迄今为止最庞大的开发者社区,在今年一月的时候,它完成了 100M 的开发者的用户量积累。当我们完成了所有数据的下载之后,即使我们不使用任何分析性数据库,单从每年的数据量的变化,也能够看到 GitHub 蓬勃的发展轨迹。
使用 du -hs 能够直观的看到近十年,GitHub 数据量的快速增长。
# du -hs *
4.6G 2011
13G 2012
26G 2013
57G 2014
75G 2015
112G 2016
145G 2017
177G 2018
254G 2019
420G 2020
503G 2021
657G 2022
将数据转换为图表,能够看到非常上升的曲线,如果我们排除掉 2020 年后的数据,增长斜率接近 45 度角。
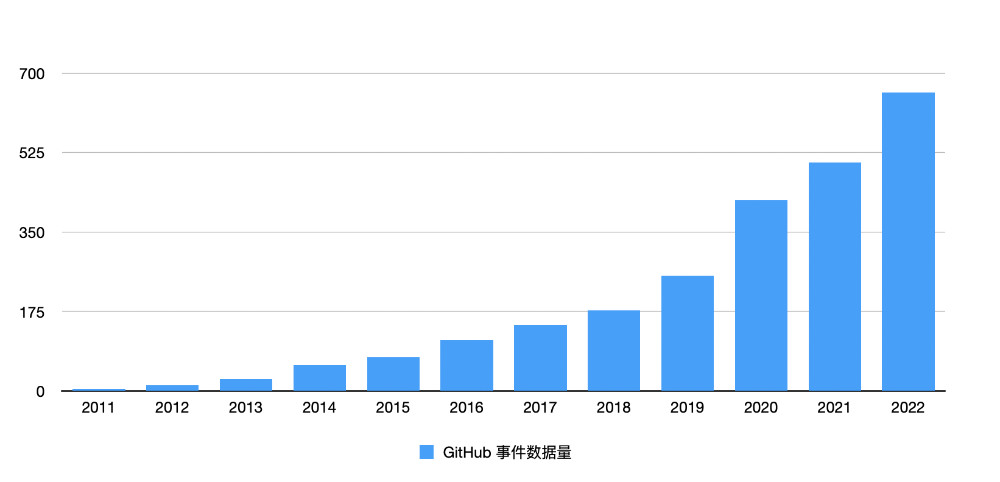
2011~2014年,GitHub 每年的数据量都翻了一番,18年 6 月,GitHub 被收购之后,GitHub 的数据量开启了“飞升之路”,虽然增长比例不高,但是增长数据的绝对值不容小觑,尤其是“黑天鹅事件”开始的三年,GitHub 的数据增长出现了更快的增长。
到底是哪些项目、哪些语言、哪些事件造成了平台的迅速增长,就需要我们进行更深入的“数据钻探”和分析啦。关于这类内容,我们后面的文章再说。
GitHub 的停机时刻(服务中断)
在不进行深入的数据分析之前,我们单单通过数据集缺失文件的列表,能够发现在过去十年里,GitHub 的因为故障而没有提供在线服务的时刻:
cat not-download.txt | awk -F '/' '{print $NF}' | sed -e 's/.json.gz//g'
完整的停机时刻列表(大于 1 小时的服务中断),共计 319 小时,粗略进行 SLA 计算,服务正常的比例在 99.7%(两个 9),19 年和 20 年的长时间停机开始出现,其中 21 年出现停机的“顶峰”。不过,随后的 2022 年,没有任何一次停机持续时间超过一小时。(至少从 GH Archive 数据采集视角看的话)
2016-10-21-18
2018-10-21-23
2018-10-22-0
2018-10-22-1
2019-05-08-12
2019-05-08-13
2019-09-12-8
2019-09-12-9
2019-09-12-10
2019-09-12-11
2019-09-12-12
2019-09-12-13
2019-09-12-14
2019-09-12-15
2019-09-12-16
2019-09-12-17
2019-09-12-18
2019-09-12-19
2019-09-12-20
2019-09-12-21
2019-09-12-22
2019-09-12-23
2019-09-13-0
2019-09-13-1
2019-09-13-2
2019-09-13-3
2019-09-13-4
2019-09-13-5
2020-03-05-22
2020-06-10-12
2020-06-10-13
2020-06-10-14
2020-06-10-15
2020-06-10-16
2020-06-10-17
2020-06-10-18
2020-06-10-19
2020-06-10-20
2020-06-10-21
2020-08-21-9
2020-08-21-10
2020-08-21-11
2020-08-21-12
2020-08-21-13
2020-08-21-14
2020-08-21-15
2020-08-21-16
2020-08-21-17
2020-08-21-18
2020-08-21-19
2020-08-21-20
2020-08-21-21
2020-08-21-22
2020-08-21-23
2020-08-22-0
2020-08-22-1
2020-08-22-2
2020-08-22-3
2020-08-22-4
2020-08-22-5
2020-08-22-6
2020-08-22-7
2020-08-22-8
2020-08-22-9
2020-08-22-10
2020-08-22-11
2020-08-22-12
2020-08-22-13
2020-08-22-14
2020-08-22-15
2020-08-22-16
2020-08-22-17
2020-08-22-18
2020-08-22-19
2020-08-22-20
2020-08-22-21
2020-08-22-22
2020-08-22-23
2020-08-23-0
2020-08-23-1
2020-08-23-2
2020-08-23-3
2020-08-23-4
2020-08-23-5
2020-08-23-6
2020-08-23-7
2020-08-23-8
2020-08-23-9
2020-08-23-10
2020-08-23-11
2020-08-23-12
2020-08-23-13
2020-08-23-14
2020-08-23-15
2021-08-25-17
2021-08-25-18
2021-08-25-19
2021-08-25-20
2021-08-25-21
2021-08-25-22
2021-08-25-23
2021-08-26-0
2021-08-26-1
2021-08-26-2
2021-08-26-3
2021-08-26-4
2021-08-26-5
2021-08-26-6
2021-08-26-7
2021-08-26-8
2021-08-26-9
2021-08-26-10
2021-08-26-11
2021-08-26-12
2021-08-26-13
2021-08-26-14
2021-08-26-15
2021-08-26-16
2021-08-26-17
2021-08-26-18
2021-08-26-19
2021-08-26-20
2021-08-26-21
2021-08-26-22
2021-08-26-23
2021-08-27-0
2021-08-27-1
2021-08-27-2
2021-08-27-3
2021-08-27-4
2021-08-27-5
2021-08-27-6
2021-08-27-7
2021-08-27-8
2021-08-27-9
2021-08-27-10
2021-08-27-11
2021-08-27-12
2021-08-27-13
2021-08-27-14
2021-08-27-15
2021-08-27-16
2021-08-27-17
2021-08-27-18
2021-08-27-19
2021-08-27-20
2021-08-27-21
2021-08-27-22
2021-10-22-5
2021-10-22-6
2021-10-22-7
2021-10-22-8
2021-10-22-9
2021-10-22-10
2021-10-22-11
2021-10-22-12
2021-10-22-13
2021-10-22-14
2021-10-22-15
2021-10-22-16
2021-10-22-17
2021-10-22-18
2021-10-22-19
2021-10-22-20
2021-10-22-21
2021-10-22-22
2021-10-23-2
2021-10-23-3
2021-10-23-4
2021-10-23-5
2021-10-23-6
2021-10-23-7
2021-10-23-8
2021-10-23-9
2021-10-23-10
2021-10-23-11
2021-10-23-12
2021-10-23-13
2021-10-23-14
2021-10-23-15
2021-10-23-16
2021-10-23-17
2021-10-23-18
2021-10-23-19
2021-10-23-20
2021-10-23-21
2021-10-23-22
2021-10-24-3
2021-10-24-4
2021-10-24-5
2021-10-24-6
2021-10-24-7
2021-10-24-8
2021-10-24-9
2021-10-24-10
2021-10-24-11
2021-10-24-12
2021-10-24-13
2021-10-24-14
2021-10-24-15
2021-10-24-16
2021-10-24-17
2021-10-24-18
2021-10-24-19
2021-10-24-20
2021-10-24-21
2021-10-24-22
2021-10-25-1
2021-10-25-2
2021-10-25-3
2021-10-25-4
2021-10-25-5
2021-10-25-6
2021-10-25-7
2021-10-25-8
2021-10-25-9
2021-10-25-10
2021-10-25-11
2021-10-25-12
2021-10-25-13
2021-10-25-14
2021-10-25-15
2021-10-25-16
2021-10-25-17
2021-10-25-18
2021-10-25-19
2021-10-25-20
2021-10-25-21
2021-10-25-22
2021-10-26-0
2021-10-26-1
2021-10-26-2
2021-10-26-3
2021-10-26-4
2021-10-26-5
2021-10-26-6
2021-10-26-7
2021-10-26-8
2021-10-26-9
2021-10-26-10
2021-10-26-11
2021-10-26-12
2021-10-26-13
2021-10-26-14
2021-10-26-15
2021-10-26-16
2021-10-26-17
2021-10-26-18
2021-10-26-19
2021-10-26-20
2021-10-26-21
2021-10-26-22
2021-10-26-23
2021-10-27-0
2021-10-27-1
2021-10-27-2
2021-10-27-3
2021-10-27-4
2021-10-27-5
2021-10-27-6
2021-10-27-7
2021-10-27-8
2021-10-27-9
2021-10-27-10
2021-10-27-11
2021-10-27-12
2021-10-27-13
2021-10-27-14
2021-10-27-15
2021-10-27-16
2021-10-27-17
2021-10-27-18
2021-10-27-19
2021-10-27-20
2021-10-27-21
2021-10-27-22
2021-10-27-23
2021-10-28-0
2021-10-28-1
2021-10-28-2
2021-10-28-3
2021-10-28-4
2021-10-28-5
2021-10-28-6
2021-10-28-7
2021-10-28-8
2021-10-28-9
2021-10-28-10
2021-10-28-11
2021-10-28-12
2021-10-28-13
2021-10-28-14
2021-10-28-15
2021-10-28-16
2021-10-28-17
2021-10-28-18
2021-10-28-19
2021-10-28-20
2021-10-28-21
2021-10-28-22
2021-10-28-23
2021-10-29-0
2021-10-29-1
2021-10-29-2
2021-10-29-3
2021-10-29-4
2021-10-29-5
2021-10-29-6
2021-10-29-7
2021-10-29-8
2021-10-29-9
2021-10-29-10
2021-10-29-11
2021-10-29-12
2021-10-29-13
2021-10-29-14
2021-10-29-15
2021-10-29-16
2021-10-29-17
GitHub 最活跃的巅峰时刻
通过下面的命令,我们可以得到 GitHub 平台上,用户和机器人最活跃的时刻:
tail sort.txt -n 10 | awk -F ' ' '{print $2}' | xargs -I {} du -hs {} | sort -r
数据结果,目前如下:
380M ./2022/2022-03-12-0.json.gz
336M ./2022/2022-05-19-0.json.gz
328M ./2022/2022-05-18-23.json.gz
321M ./2022/2022-05-19-2.json.gz
304M ./2022/2022-05-18-22.json.gz
291M ./2022/2022-02-26-6.json.gz
289M ./2022/2022-02-26-8.json.gz
286M ./2022/2022-02-26-7.json.gz
284M ./2022/2022-02-26-5.json.gz
281M ./2022/2022-03-11-23.json.gz
果然,半夜不睡,是符合工程师习惯的。
GitHub 最活跃的月份
想要得到 GitHub 上最活跃的月份,需要写一个简单的程序,来帮助我们进行数据累加:
const { readFileSync } = require("fs");
const du = (size) => {
const i = size == 0 ? 0 : Math.floor(Math.log(size) / Math.log(1024));
return (size / Math.pow(1024, i)).toFixed(2) * 1 + " " + ["kB", "MB", "GB", "TB"][i];
};
const totalRecords = readFileSync("./sort.txt", "utf-8")
.split("\n")
.map((n) => n.trim())
.filter((n) => n)
.map((n) => {
let [size, filename] = n.split("\t");
size = parseInt(size, 10);
filename = filename.split("/")[2].split(".")[0];
const [year, month, day, hour] = filename
.split("-")
.slice(0, 4)
.map((n) => parseInt(n, 10));
return { size, year, month, day, hour };
});
const groupByMonth = totalRecords.reduce((prev, item) => {
const { size, month } = item;
prev[month] = prev[month] || 0;
prev[month] += size;
return prev;
}, {});
Object.keys(groupByMonth).forEach((key) => {
groupByMonth[key] = du(groupByMonth[key]);
});
console.log(groupByMonth);
最终数据如下:
{
'1': '172.49 GB',
'2': '184.24 GB',
'3': '207.08 GB',
'4': '196.82 GB',
'5': '212.64 GB',
'6': '198.75 GB',
'7': '198.24 GB',
'8': '198.49 GB',
'9': '216.7 GB',
'10': '209.58 GB',
'11': '227.52 GB',
'12': '226.62 GB'
}
可能,只有年底,大家才会想起来要“打打卡”。
GitHub 数据集相关的故事
文章开头提到,在 GHArchive 项目中,我们能够看到目前全球有至少二十~三十个基于 GitHub 进行分析的开源项目,它们基于不同的维度、提供了不同的功能,甚至有一些项目因为年代久远,已经下线成为了“互联网活化石”的一部分。
最近一年中,最令人记忆深刻的应该莫属 “OSS Insight” 啦。它具备漂亮过各种前任的界面,支持一些相对初级的数据分析。随后推出的 PingCAP Cloud 也集成了这个功能,你可以掏点钱来“分分钟”体验一个属于你的,但是只有很少(似乎只包含2022.01.01 数据)的在线 Demo。
虽然官方博客里,描述这个项目看起来是一个在 2022 年一时兴起的点子,但其实这个“种草”应该早在一年之前。

OSS Insight 项目的起源或许来自于 2021 年 3月,当时一个有趣的老板需求。不管出于什么原因,能够造福社区的“一时兴起”的老板需求,或许多来一些也无妨。
不过,关于 GitHub 数据探索的故事的起源,也并非 2021 年,而能够回溯到更早的 2020 年。

在 2020 年的时候,有海外的同学使用 ClickHouse 实现过一遍针对 GitHub 的数据分析,并写了一篇翔实的文章,发布在了 ClickHouse 的网站上,这或许才是 OSS Insight 的原型之一。可惜的是,这个内容中的数据集,伴随文章停留在了 2020 年,也缺少不少复现细节,以及相比 OSS Insight 还少了漂亮的前端界面。
当然,GitHub 的数据探索,也并非只是 2020 年才开始的。

在 GH Archive 网站上,还列举了其他的前人,对于这份数据的探索、贡献列表,可以供任何想要了解开源世界的人,进行学习和研究。
最后
这篇文章完成于春节假期,因为我的快递迟迟不能送达,所以只能先折腾下数据,以防后续出现“无米之炊”的情况。最近,团队有同学想深入了解这个数据集,趁着机会,将内容整理成文,希望能够帮助到有同样需求的,对开源世界好奇的你。
–EOF