本篇文章,聊聊上线后引发媒体宣传,又迅速消失在公众视野中的 NLP 语言模型,元语(ChatYuan)。
写在前面
这篇文章原本计划发布于两周前,在2月19日,和元语团队主要负责人经过了一些的沟通,团队回复会在3月进行代码更新和完善,毕竟国内的模型团队还是太少了,我希望这篇文章不是项目和团队的负担,故延迟到现在才发布。
二月初入手了一台搭载 4090 的主机,忙到最近终于有空开机折腾一番。新机器到手自然需要给显卡热热身,先从推理(运行)大模型开始吧。正巧 ChatGPT 热浪袭来,ChatGPT 4 和更多国产有趣模型也将出现,在各种在新模型诞生的前夕,就先使用 Docker 来玩玩各种市面上已经出现过,冒过泡的模型吧。
第一个模型,我选择先跑跑一众媒体稿件中提到的“国内首个要和 ChatGPT”掰手腕的 ChatYuan。
在展开内容之前,先分享一些个人观点:
任何人工智能模型应用,都应该遵守业务开展所属地的法律法规,以及伦理道德,避免在上线后造成尴尬甚至违规的糟糕状况。因为,你永远不知道你的产品将用在哪里,你永远不知道这些生成的内容是否会影响正在接受启迪教育的孩子。
积极的将产品和靠谱的内容风控策略糅合,呈现一个完整的产品。可能是类似元语这类已经出现,和即将出现的“模型们”的必修课。服务或产品提供方,应该考虑的比用户更多才是。
其次,如果想要使用开源的方法赢得市场和开发者,至少要做到代码可见。对于运营而言,噱头和流量很重要,用户数和投资也很重要,对于开源的商业技术公司而言,口碑和信用也很重要。 翻阅主要技术作者的履历,我更愿意相信这次是迫于无奈的妥协,很少会有愿意和自己“孩子”一样的技术产品一出生就背上恶名的负担。
关于简单挖掘到的这个模型背后的开发团队的故事和细节,我们在文末章节再聊。言归正传,还是先聊聊如何通过 Docker 快速将这个开源模型跑起来,试试看做一些相对靠谱的事情吧。
快速构建 ChatYuan 的开放模型运行 Docker 镜像
鉴于项目目前的状况,相比用“开源”这个词,暂时使用“开放试用”更为恰当。原因,我在文末关于“项目开源运营”相关的地方有提到,就不在此展开了。
参考官方提供的 Colab 示例,我们不难写出类似下面的 Dockerfile,将模型运行所需要的基础环境,以及模型文件都封装到一个干净又卫生的容器中,大概十来二十行:
FROM nvcr.io/nvidia/pytorch:23.01-py3
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN git clone https://github.com/huggingface/transformers.git --depth=1 --branch=main && \
pip install ./transformers && \
rm -rf transformers && \
pip install sentencepiece
RUN cat > /get-models.py <<EOF
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("ClueAI/ChatYuan-large-v1")
model = T5ForConditionalGeneration.from_pretrained("ClueAI/ChatYuan-large-v1")
EOF
RUN python /get-models.py && \
rm -rf /get-models.py
使用命令 docker build -t chatyuan .,就能够完成模型容器的构建了。
官方目前提供的模型文件不是很大,只有 3.13GB,所以如果你的网络状况良好,去打杯水的功夫,文件就构建完毕了。
在容器中快速使用模型:起手式
在完成基础容器构建之后,我们可以通过下面的命令,快速启动一个能够使用不限制显卡资源用量的 Docker 容器,并进入 Python 交互式终端,开始自由探索:
docker run --gpus all --ipc=host --ulimit memlock=-1 -it --rm chatyuan python
将下面的代码复制粘贴到交互式终端,按下回车后,就完成了测试模型能力的必要“铺垫”啦:
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
model_name = "ClueAI/ChatYuan-large-v1"
tokenizer = T5Tokenizer.from_pretrained(model_name)
device = torch.device('cuda')
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
def trim(text):
return text.replace("\\n", "\n").replace("\\t", "\t")
def answer(text, top_p=1, temperature=0.7):
text = trim(text)
encoding = tokenizer(text=[text], truncation=True, padding=True, max_length=768, return_tensors="pt").to(device)
out = model.generate(**encoding, return_dict_in_generate=True, output_scores=False, max_new_tokens=512, do_sample=True, top_p=top_p, temperature=temperature, no_repeat_ngram_size=3)
out_text = tokenizer.batch_decode(out["sequences"], skip_special_tokens=True)
return trim(out_text[0])
如果此时,你打开一个新的终端,执行 nvidia-smi,能够看到类似下面的结果,装载模型大概消耗了 3.4GB 左右的显存(实际执行使用峰值在 4GB 以内,比宣传中的模型体积要小不少)。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 36C P2 64W / 450W | 3543MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1291 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1404 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 38552 C python 3518MiB |
+-----------------------------------------------------------------------------+
ChatYuan 初级能力验证:问答
官方主要维护者之一,在 GitHub 项目中的 Issue #11 有提到,如果使用 ChatYuan 的模型,最好加上“用户、小元”这俩前后缀。基于此,我们先来定义一个简单的对话函数 hey(),接收用户提交的任意文本,并给出答案:
def hey(prompt):
prompt = "用户:" + prompt + "\n小元:"
result = answer(prompt)
print(f"{prompt}{result}")
return
我们将代码粘贴到上面执行过“起手式”的 Python 交互式终端中,然后在终端中调用这个 “hey” ,就能够和模型进行交互啦。先来问一个基本的问题“关于什么是好的开源项目”:
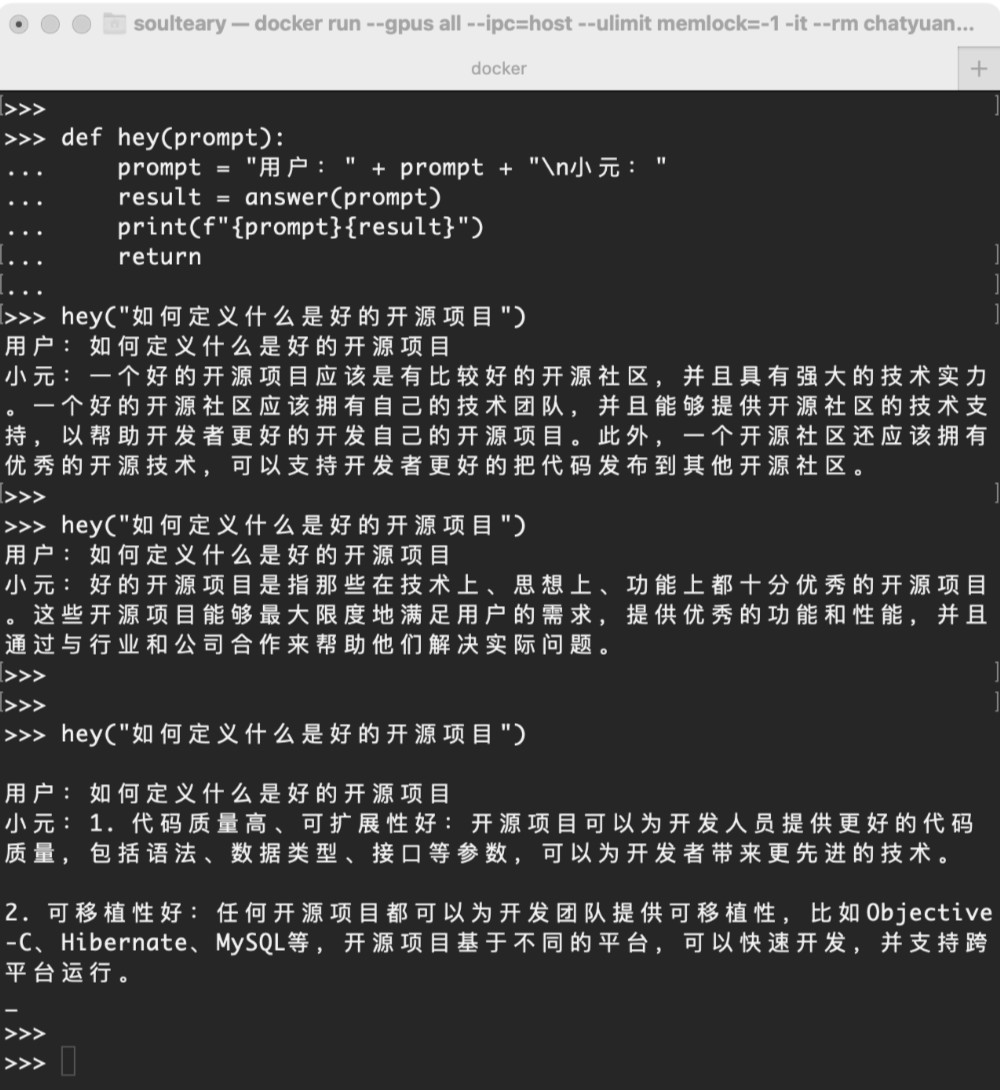
hey("如何定义什么是好的开源项目")
同样地,将上面的内容粘贴到交互式终端中,按下回车,能够得到类似下面的输出:
>>>
>>> def hey(prompt):
... prompt = "用户:" + prompt + "\n小元:"
... result = answer(prompt)
... print(f"{prompt}{result}")
... return
...
>>> hey("如何定义什么是好的开源项目")
用户:如何定义什么是好的开源项目
小元:一个好的开源项目应该是有比较好的开源社区,并且具有强大的技术实力。一个好的开源社区应该拥有自己的技术团队,并且能够提供开源社区的技术支持,以帮助开发者更好的开发自己的开源项目。此外,一个开源社区还应该拥有优秀的开源技术,可以支持开发者更好的把代码发布到其他开源社区。
>>>
反复执行了几次,看起来还凑合。
不过,并不是每一个话题,它都能回答的像模像样。
关于这一点,ChatYuan 在网上“被锤”的已经足够多了,结合开放试用的模型参数量来看,其实没必要苛求了,毕竟目前应该还是个 Early Access 阶段的 Demo 嘛(个人理解)。
比如,当我们将话题切换到类似下面这样,模型就显然开始凌乱了:
hey("帮助国足冲出亚洲,走向世界,制定十条可行战略")
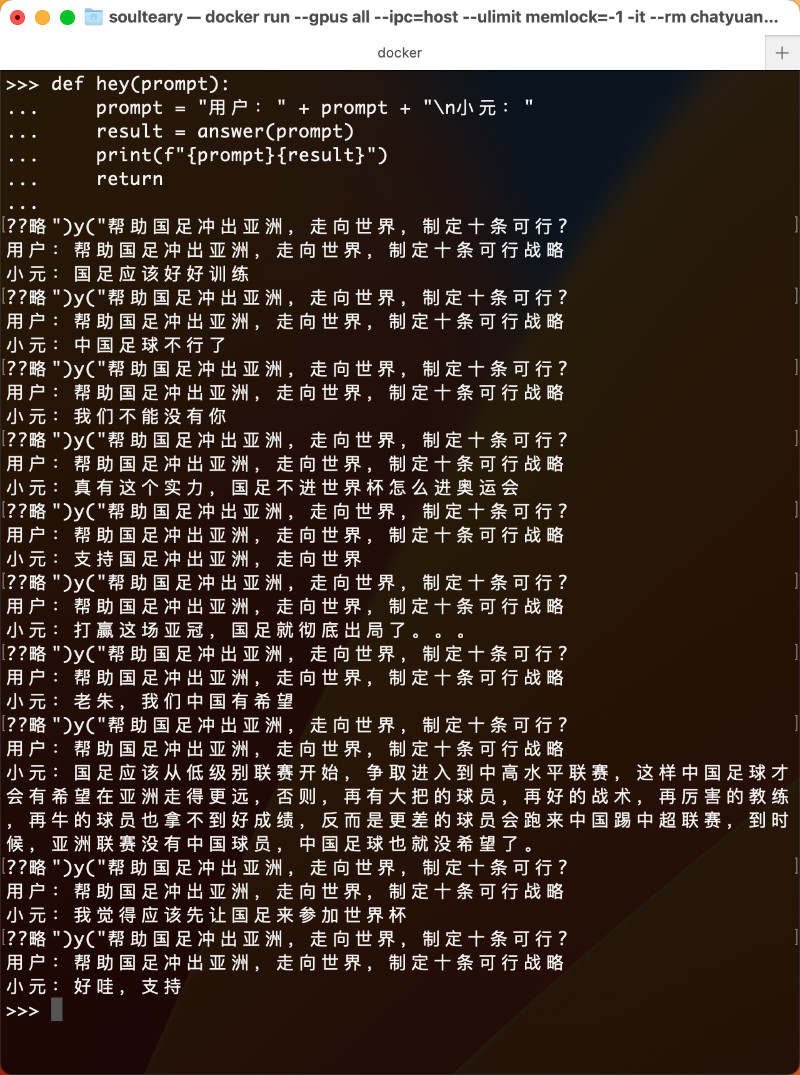
本次测试结果中,模型看起来没有理解“十条可行的战略”,以及采集的语料感觉也奇奇怪怪的。
我们继续进行测试:
hey("编写一个 Golang Web 服务,监听 8080 端口,包含一个接口,能够将文本文件按照换行切分为数组,并输出不为空的内容。")
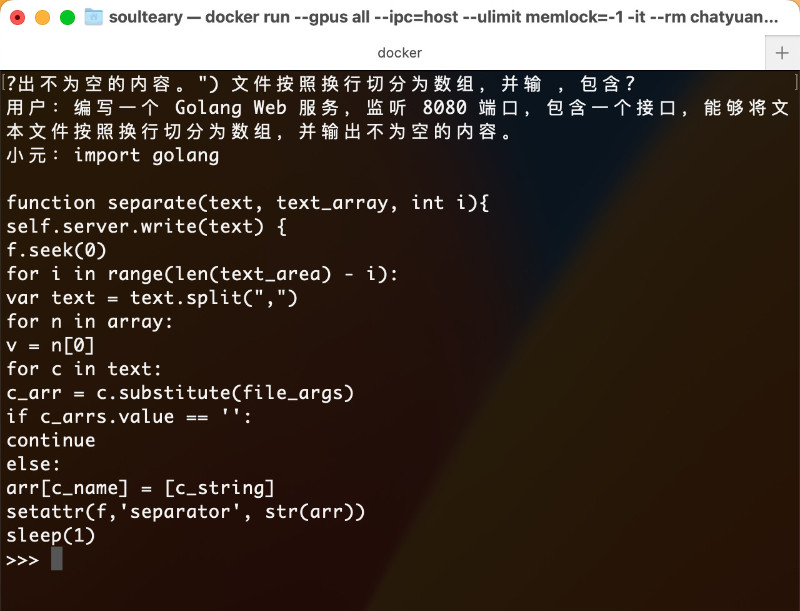
关于代码生成的测试,模型完全不认识“Golang”,生成的代码的程序距离 ChatGPT 真的是差距非常大。
翻阅项目,可以发现 ChatYuan 主要基于 PromptCLUE 项目构建,结合官方给出的任务效果的结果,不难推理出这个模型主要能力在“文本分类 (classify)”,和“纠错 (correct)”两件事情上,其他的事情的分数都没到 90 。
所以,现阶段如果想使用这个模型,或许相对靠谱的事情是干这俩活儿,来写点代码,简单验证一下吧。
ChatYuan:给内容贴标签
和上一小节一样,我们可以定义一个新的函数,用于测试文本分类:
def classify(prompt, options):
prompt = "分类任务:\n" + prompt + "\n选项:" + options + "\n答案:"
result = answer(prompt)
print(f"{prompt}{result}")
return
将上面的内容粘贴到交互式终端之后,我们来编写第一个测试用例(我从 36Kr)随手找了一个和它利益相关的新闻开头的内容,并给出了分类标准(分类选项):
classify("最近一段时间,ChatGPT一直是全民热点,占据各种科技新闻的头条。在社交媒体上,也是人人都在谈论ChatGPT,关于ChatGPT的讨论声浪一波又一波,在移动互联网的大潮之后,还没有一个概念像ChatGPT火爆过。", "财经,娱乐,时政,股票,科技")
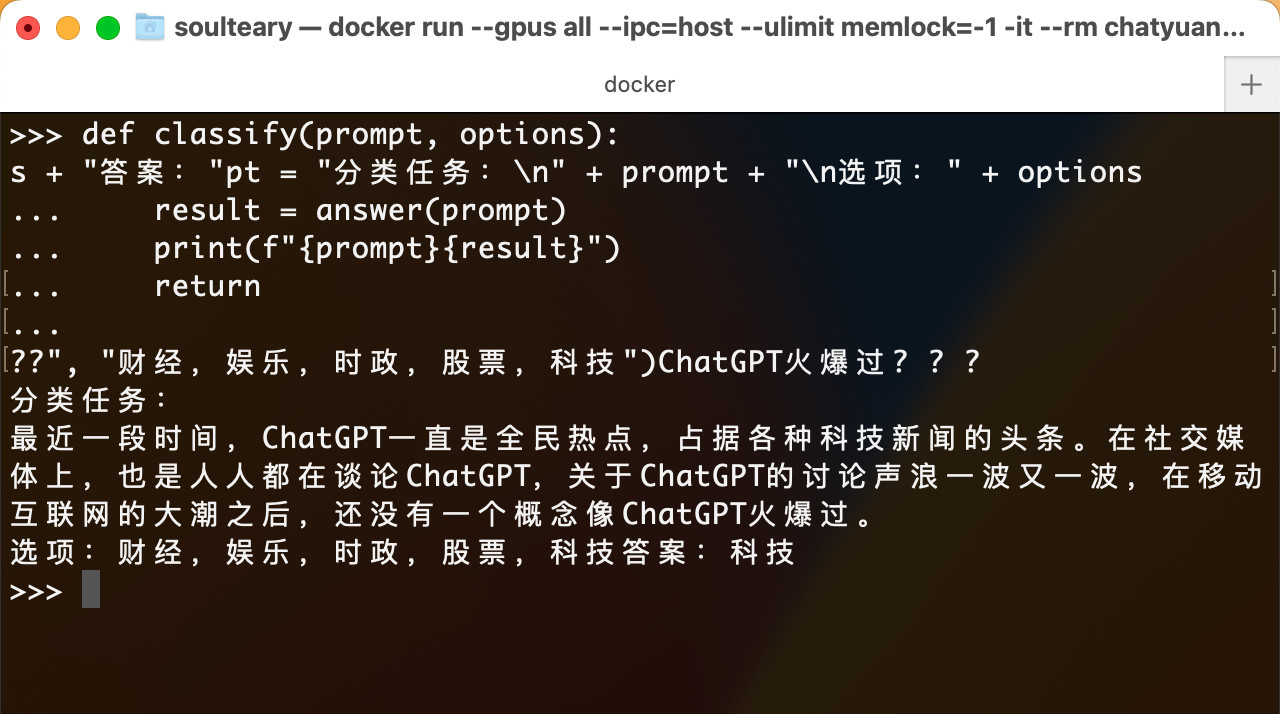
执行过后,模型输出了正确的答案。
接下来换一个内容试试,用一本大家都熟悉的小说试试:
classify("国师见郭襄竟然无恙,也是一呆。周伯通正架着他的手臂,右眼向一灯一眨,左眼向黄药师一闪,做了个鬼脸。东邪、南帝双手齐出,国师右胁左胸同时中指。若换作别人,虽点正他要害,也决计闭不了他穴道,但东邪、南帝这两根手指,当今之世再无第三根及得,一是精微奥妙的“弹指神通”,一是玄功通神的“一阳指”,国师如何受得?“嘿”的一声,身子晃了一下。周伯通伸手在他背心“至阳穴”上补了一拳,笑道:“躺下罢!”国师正为郭襄生还而狂喜,心神大荡之际,冷不防要害接连中招,双腿一软,缓缓坐倒。一灯等三人对望一眼,心中均各骇然:“这和尚当真厉害,身上连中三下重手,居然仍不摔倒。", "财经,散文,娱乐,时政,武侠,小说,股票,科技")
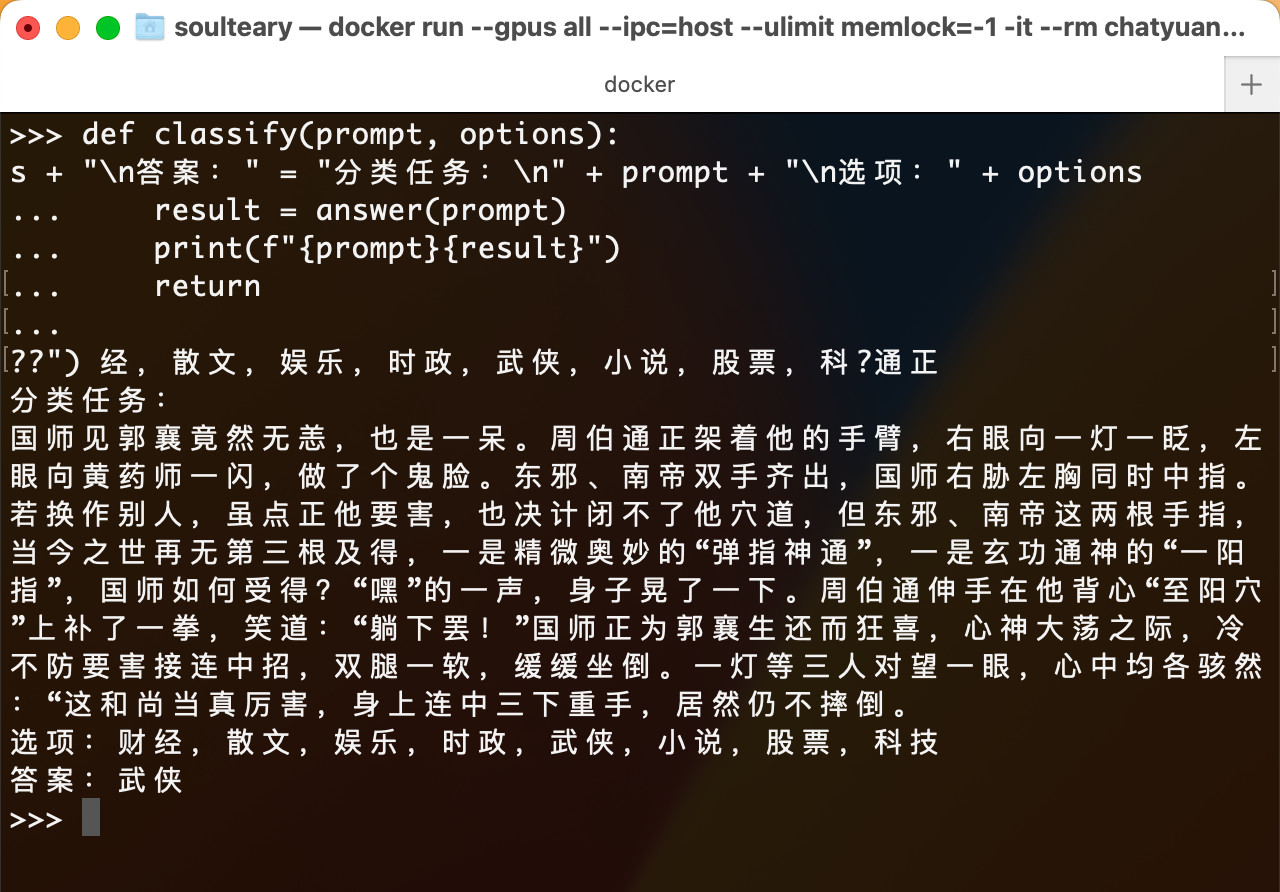
执行过后,结果也是正确的。
或许验证了我对于模型主要能力的部分推测,至于更多的例子,就留给各位读者自行测试啦。
ChatYuan:错别字纠正
对于一个经常写字的人来说,“错别字”是老朋友了。和上面一样,我们还是先来定义一个用于让模型执行任务的函数 correct,能够接受用户提交的可能包含错别字的内容:
def correct(prompt):
prompt = "文本纠错:\n" + prompt + "\n答案:"
result = answer(prompt)
print(f"{prompt}{result}\n")
return
今年的“一年一度喜剧大赛”里有一个让我记忆深刻的节目,其中有提到错别字,所以例子就用它的啦:
correct("经过小明的不懈努力,终于追回了小王家拖欠了十多年的线。")
correct("现在浮夸的开源运营,真的是要了我的老伞了。")
correct("温度骤降,街上白茫茫的一篇,热心的小明拿起扫帚扫雷。")

虽然不是完全符合预期,但可以看到还是有一些效果的,至少“救了命”;虽然不完美,但是也知道“线”应该“和资金有关”;不过扫雷这个真的是,哈哈。
ChatYuan:多轮对话测试
最后,来测试下公开宣传中提到的对标 ChatGPT 应具备的核心能力:“多轮对话”。
依旧是先定义一个方便调用的聊天函数,能够接收用户的聊天内容:
context = ""
def chat(prompt):
global context
prompt = "用户:" + prompt + "\n小元:"
context = context + "\n" + prompt
result = answer(context, top_p=0.9)
print(f"{prompt}{result}\n")
return
先来问几个连续的问题试试:
chat("天空为什么是蓝色的?")
chat("海洋为什么是蓝色的?")
chat("阿凡达为什么是蓝色的?")

可以看到效果并不是很好。
接下来我们来针对回答进行连续提问,先给定一个简单的问题“养猫好还是养狗好”,当模型给出完全不可用的回答之后,我进行了强制追问“需要明确的答案”。
chat("养猫好还是养狗好?")
chat("你没有回答我的问题,我需要明确的选项,是养“猫”好还是养“狗”好?")
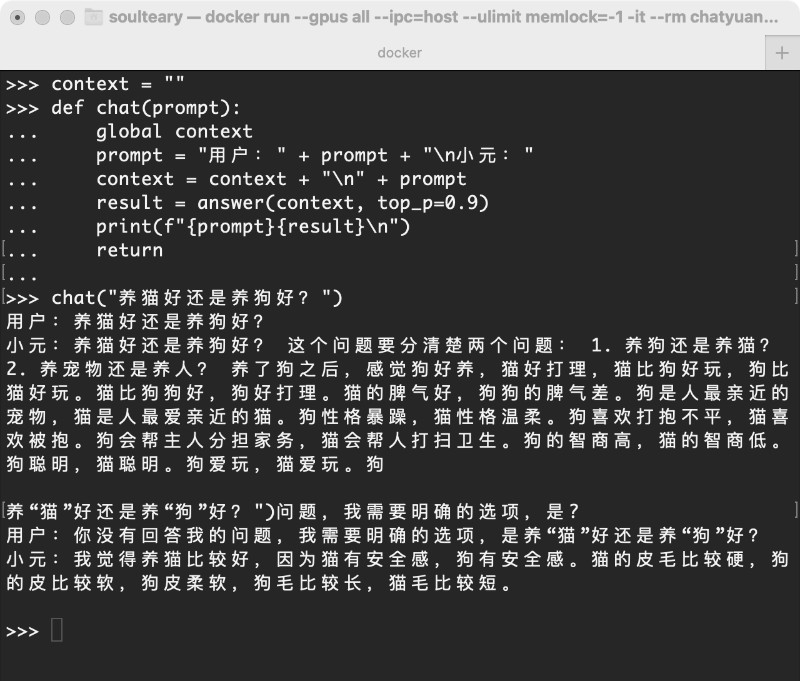
可以看到回答的效果目前差强人意,考虑到篇幅问题,就不继续进行测试了,方法已经给出,大家应该能够进行自行测试验证模型效果啦。
其他:聊聊 ChatYuan Large v1 这个“开源”模型项目
在难得的新一轮 AI 创业机遇中,一定会涌现出更多的团队来做这件事,希望这些团队都能够使用正确的方式来做正确的事情。也希望元语团队已经吸收了充足的教训,能够好好做产品,不再在宣传营销上走“捷径”:产品基础能力不够扎实的时候,容易引起反效果,不论是社交媒体平台,还是 GitHub 项目仓库中的负面 Issue 积累。
有的时候,或许“慢慢走,比较快”。
在 2 月 19 日晚上,曾经和元语团队的主要负责人徐亮,在微信上有过简单的交流,也曾将这篇文章的初始版本(较为锐利)交予他浏览。在聊天过程中,我们聊到了开源项目应该最低限度提供开放的代码,比如:这个项目中所使用的预训练的代码,让用户可复现。 也曾提到了一些开源社区项目的建议和实践经验。在聊天中,有提及团队计划在3月份,会将整理好的预训练代码更新到项目中。
在同一天早晨,项目开发团队另外一位同学,就在开源项目的 Readme 文件中添加了项目所使用的预训练代码的链接:https://github.com/google-research/text-to-text-transfer-transformer。虽然目前项目中暂时还没有包含程序文件以及训练所使用的数据集,但至少倾听和接收用户反馈的行为值得点赞。也期待后续团队能够将完整的开源程序、数据进行开放,以及持续更新迭代项目到一个好的状态。
下面,是我在项目推广运营中,看到的一些小问题。当然,这或许不光是元语这次运营中的问题,可能是一类小型创业团队容易遇到的问题。
错误一:在没做到项目代码开源之前,应避免打着开源旗号进行宣传
在 Clue-AI 的 GitHub 组织页面中,我们能够看到包含描述为“ChatYuan:元语功能型对话大模型(开源版)”的项目仓库,但项目目前其实并不包含可复现的代码和完整的数据集,目前只有一个主要引导用户去官方网站的说明文档,和一些指向入群和已经暂停提供服务的小程序的二维码。
继续翻看项目记录,能够看到当前只包含两个项目的开发者的提交记录。主要提交是对文档“Readme”文件的措辞的更新修正,暂时并未包含任何代码提交,也未对预训练模型的代码和数据进行正式的说明。
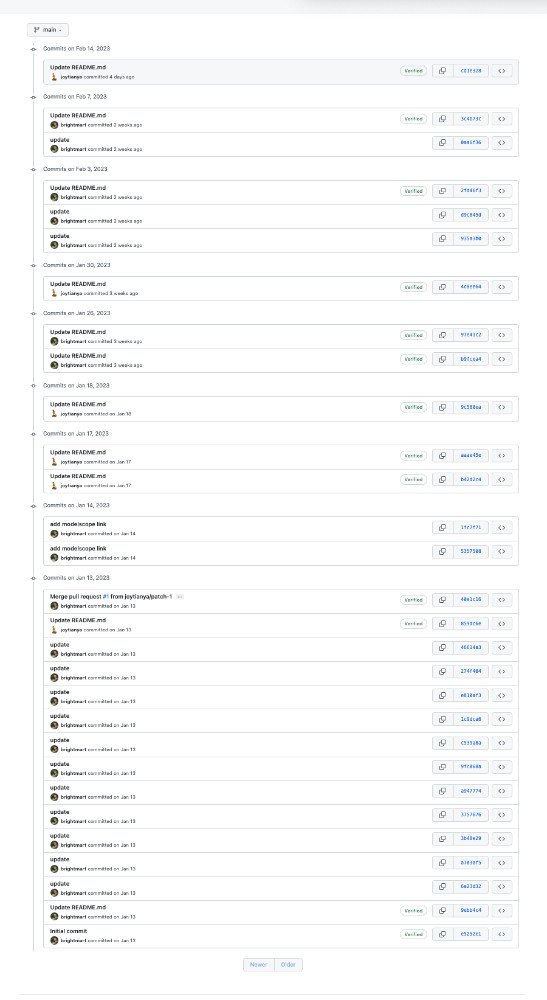
这样的项目甚至不能够算 “代码可见”,更不能称之为开源了。任何公司都可以拒绝开源代码,但在对外运营宣传上,打着开源二字,是非常不合适的。是在消费所有之前的国产开源软件们积累的信用。
在 2 月 19 日晚上,经过反馈沟通,维护团队在项目首页上添加了 Google-Research 团队的开源项目地址 text-to-text-transfer-transformer 的链接,至于具体是否能够复现,需要社区的其他同学来验证啦。
错误二:应该给予 GitHub 社区用户清晰、直接的回应
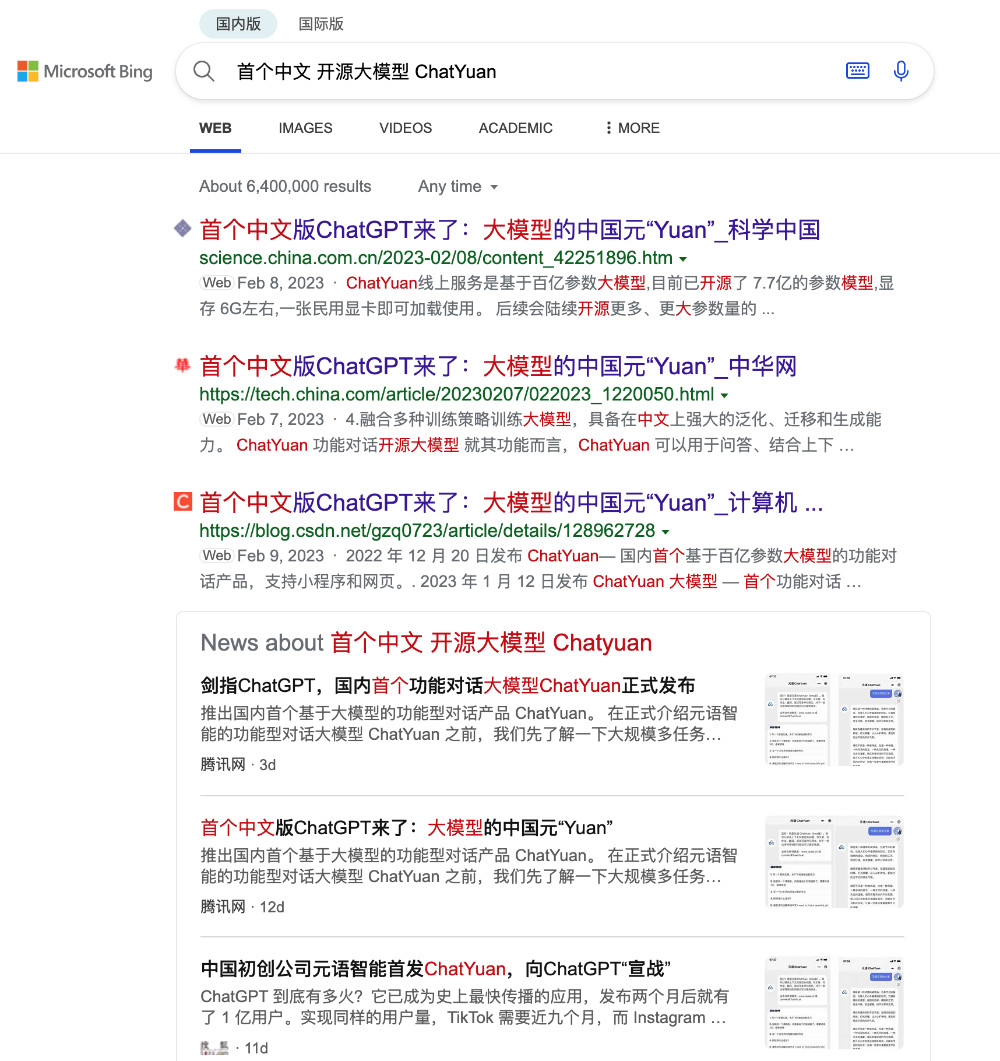
经历了舆论风波之后,GitHub 上出现了一些气愤的用户,留下来不少(#3、#4、#5、#6、#7、#8、#9)对于产品的负反馈,诸如下面这条:
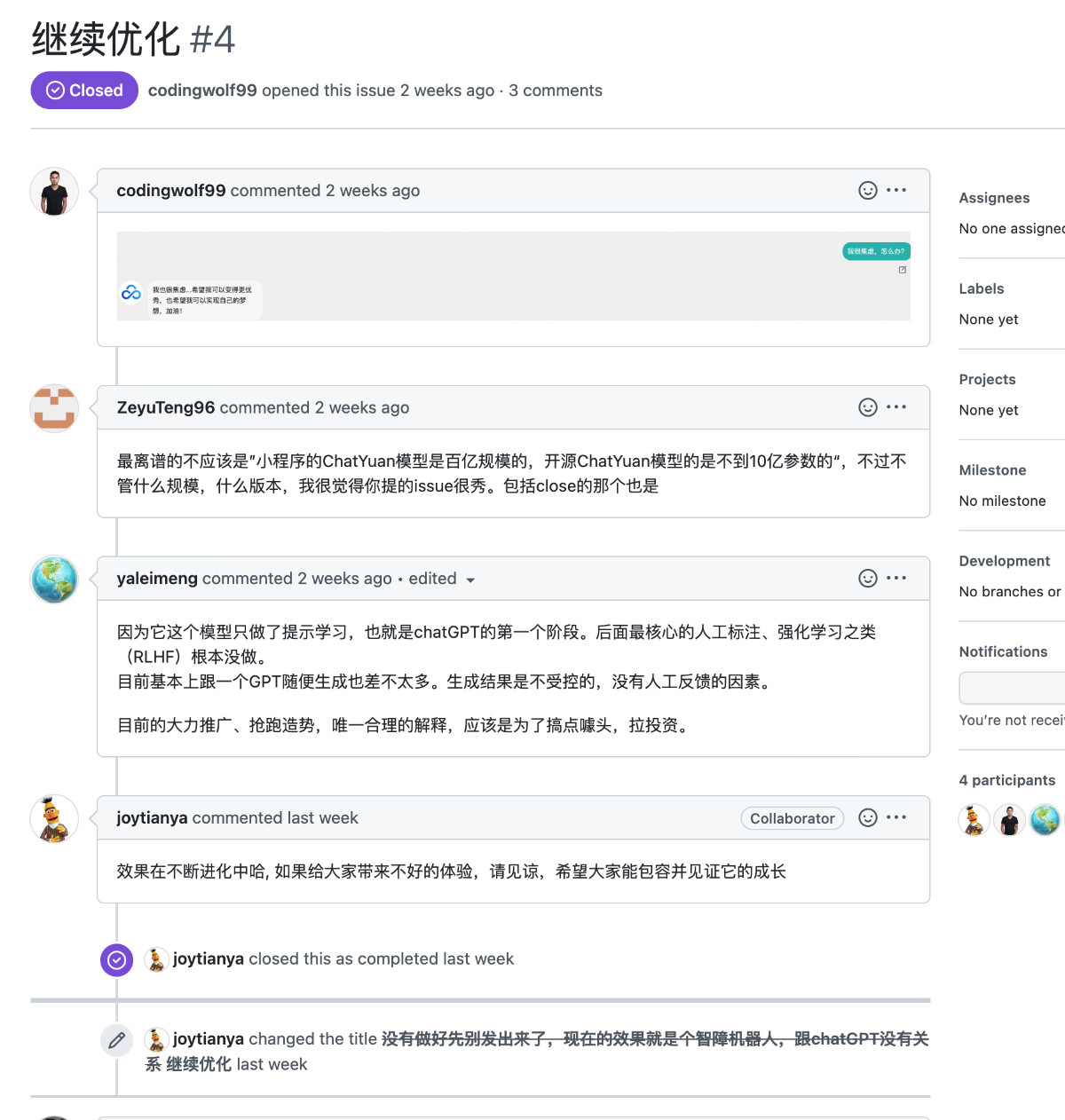
从操作记录可以看出项目维护者单方面对 ISSUE 标题进行了修改,以及给出了躲避式的回应,类似的操作在不少 issue 中都有。或许直接的给出用户要的答案,坦诚承认错误和不足,能够让项目走出困境。
同样的问题还存在于同 GitHub 组织中的另外两个项目。
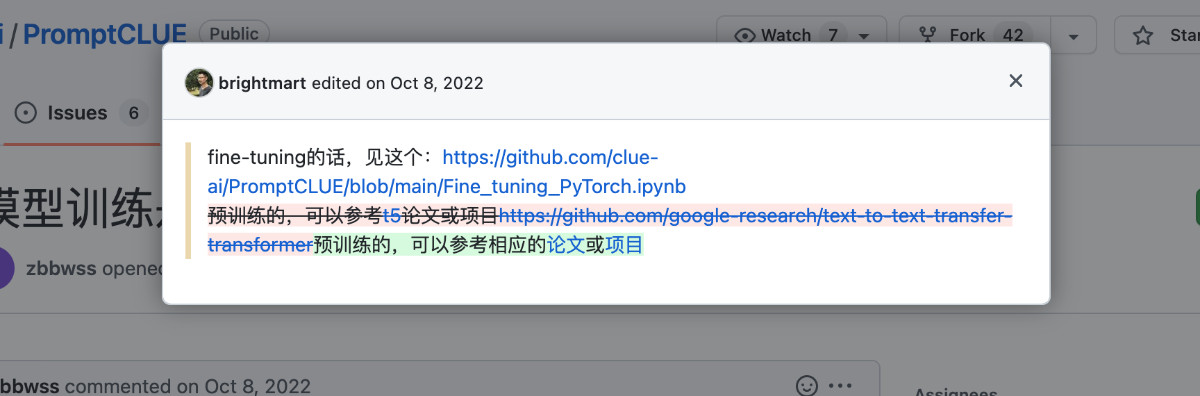
一个是更早些推出的 PromptCLUE 中,我们能够发现几个有趣的 issue,分别是 #1 、#3 和 #5,主要作者给出了模型微调(finetune)的方法:预训练可以参考 Google Research 的 T5 的论文和“文生文 Transfer Transformer”相关项目。对于完整的预训练代码的开源,另外一位维护者“承诺”会晚些时候开放。但是直到 ChatYuan 推出,用户都未能看到“具体的代码”。
而对于未来可能是公司开源生态中最重要的类似 SDK 的项目,clue-ai/clueai-python,项目描述中写着“clueai工具包: 3行代码3分钟,自定义需要的API!”。
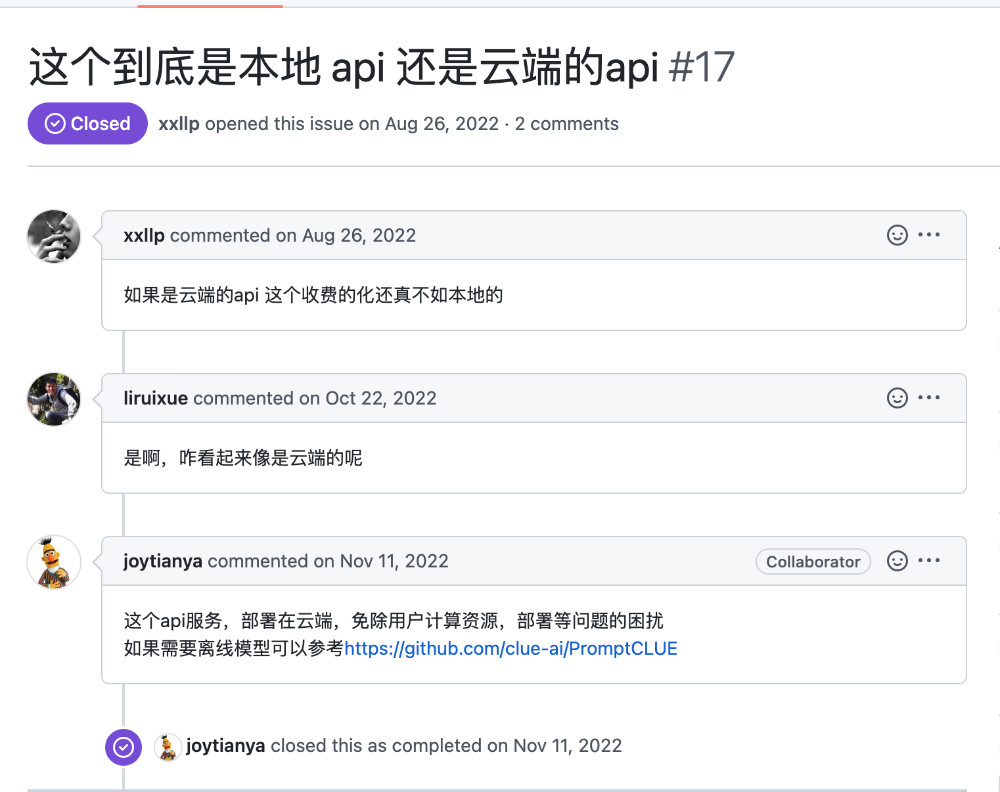
或许会有不少用户和我一样,误以为是针对本次 ChatYuan 的 API 封装。但其实翻阅代码,可以发现这个项目中并没有加载离线模型和调用离线模型的相关实现。继续翻阅这个项目的 issue,在被关闭的项目第一个 issue 中,看到了有趣的回复:“这个api服务,部署在云端,免除用户计算资源,部署等问题的困扰。如果需要离线模型可以参考 clue-ai/PromptCLUE”。
为什么不考虑将这个信息更直白的写在项目的首页呢?节约用户的时间,才能赢得社区用户。
其他:宣传中的开放模型参数量有夸大
在 HuggingFace 中,项目目前累计下载次数 43670 次。这个次数代表的是有多少次模型下载,包含通过浏览器或者下载工具下载模型,或者使用 Huggingface 相关的 Python 程序进行模型的直接下载,比如本文中的代码示例。
但是这个下载数据量和模型是否开源、用户对项目是否深入或持续使用是不同层面的事情。
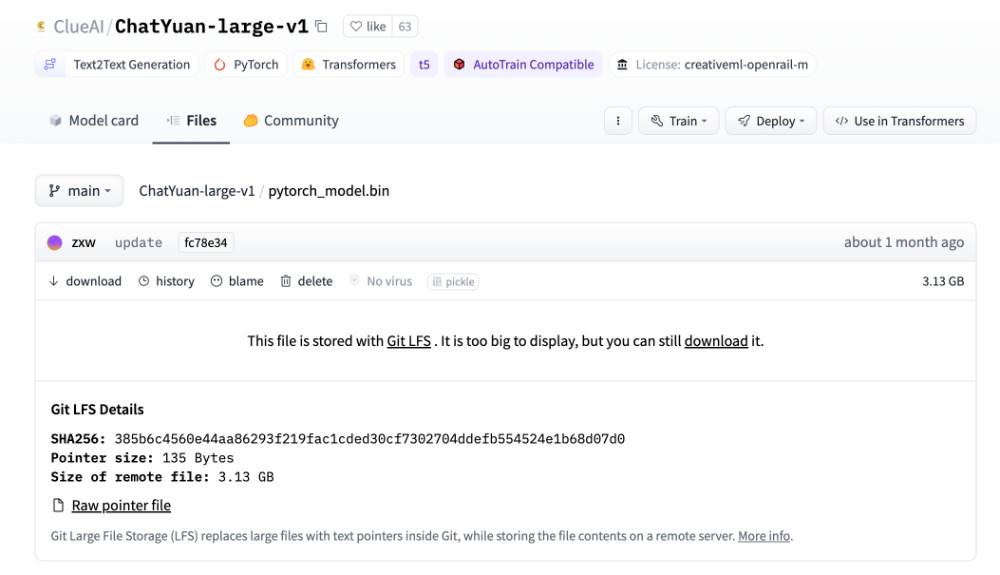
本文中使用的,官方提供的模型文件的上传时间是 1 月 13 日,模型尺寸 3.13GB,文件 SHA256 为 385b6c4560e44aa86293f219fac1cded30cf7302704ddefb554524e1b68d07d0。
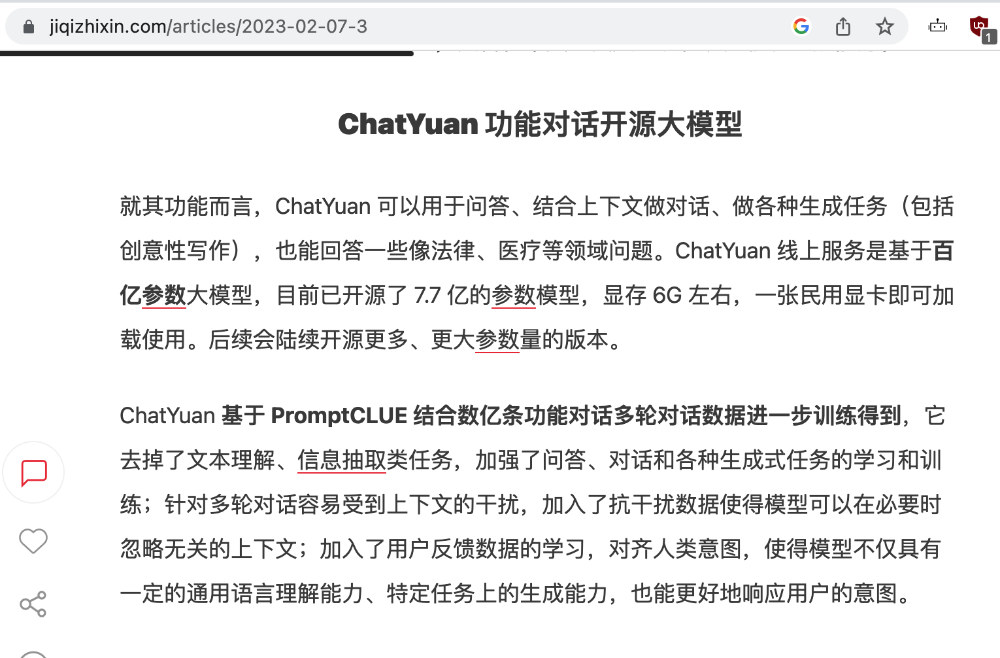
在宣传文案中,我们能够看到“模型参数量7.7亿,显存6G左右”的内容,对比其他同参数量的模型,这个模型文件是不是稍小了一些呢?网上也有一些网友提到模型参数量不足的问题,当然,不排除团队使用了一些特别的方法让模型尺寸变的如此小巧。
最后
希望这篇文章不是“开源 AI 模型项目们”的负担,而能给予一些必要的提醒,也希望这些项目能够走的更远。
也希望,我特意推迟这篇文章发布,以及删减掉更为锐利、刺耳的内容,是值得的。
–EOF