这篇文章聊聊如何从零到一安装、配置一个基于 Docker 容器的深度学习环境。
写在前面
这段时间,不论是 NLP 模型,还是 CV 模型,都得到了极大的发展。有不少模型甚至可以愉快的在本地运行,并且有着不错的效果。所以,经常有小伙伴对于硬件选择,基础环境准备有这样、那样的问题。
恰逢团队里有小伙伴也想了解这块如何折腾,就先写一篇内容聊聊吧。
本文中的方法,可用于 Nvidia 显卡以及常见硬件,如:A100 服务器、RTX4090 家用显卡。(手头素材不多,如果其他显卡有不同,欢迎补充)
考虑到 Nvidia 官方容器镜像的选择目前是 Ubuntu,以及目前 Ubuntu 社区的蓬勃发展,所以本篇文章的基础环境就选它啦。
安装 Ubuntu 操作系统
安装 Ubuntu 的流程和以往并没有太大不同,依旧是老生常谈的三步曲:下载镜像、制作启动盘、安装系统。
关于如何制作镜像启动盘,以及基础的安装过程,参考《在笔记本上搭建高性价比的 Linux 学习环境:基础篇》中提到的内容即可。
如果你希望更快的完成系统设置,可以参考本章节的“安装细节拾遗”小节,来加速安装和调整 BIOS 设置。
升级老系统
一般来说,我们选择 LTS 版本的系统镜像即可,如果你已经完成了系统的安装,可以跳过这个小节的内容。
如果你使用的是早些时候的 Ubuntu 版本,可以考虑参考早些时候的文章《抢先体验 Ubuntu 22.04 Jammy Jellyfish》,来进行系统升级。
安装细节拾遗
为了避免一些不必要的麻烦,建议在安装之前,前往 BIOS 关闭 “Secure Boot”。
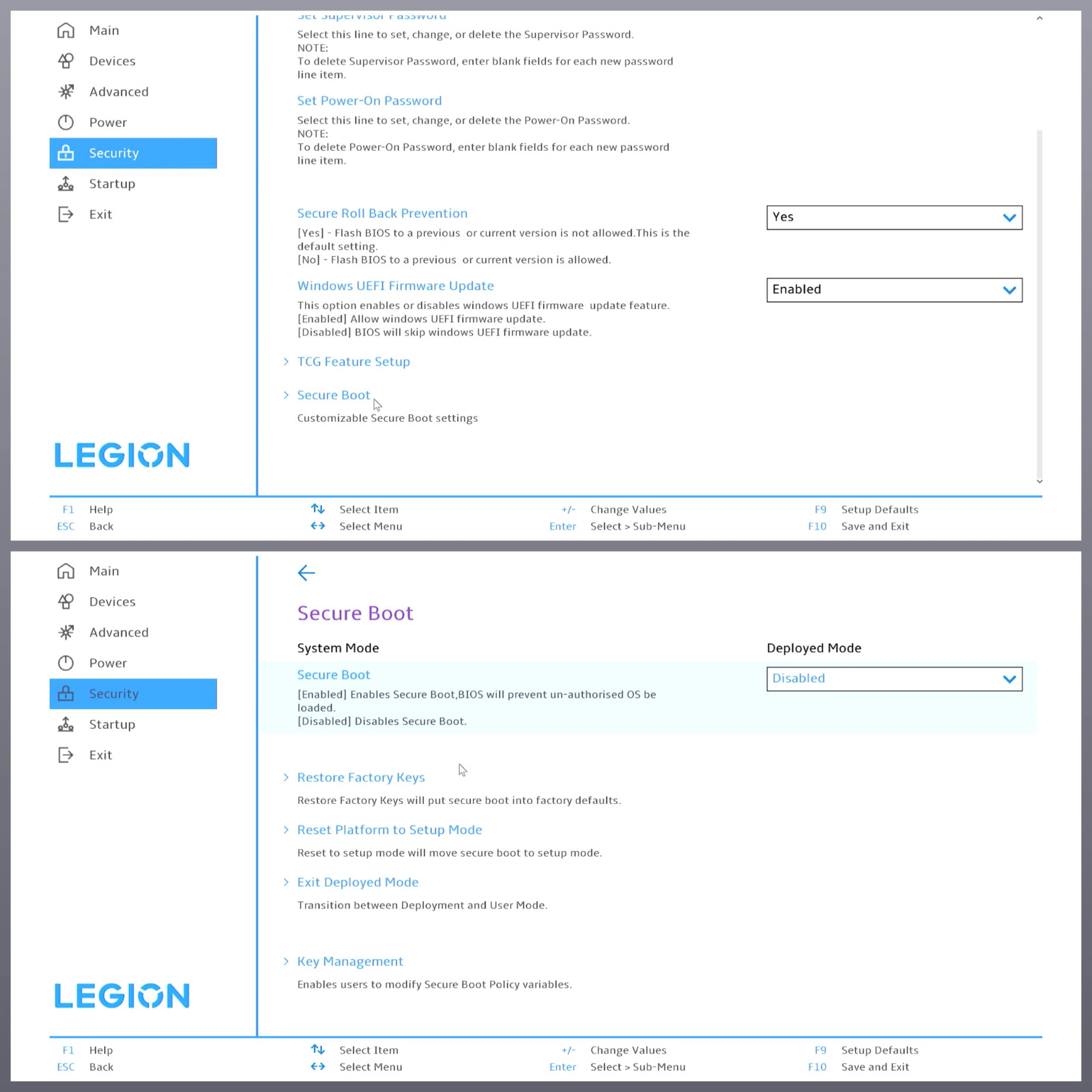
在国内的网络环境,考虑到从官方下载大量更新和驱动极大的延长安装时间,这里我们可以不进行任何额外组件的下载。等到系统安装完毕之后,能够自由调整软件源,再安装不迟。Server 版本支持设置软件包来源或设置网络代理,是否在此处更新软件,根据你的喜好来即可。

“一路 Next” 之后 ,我们等待系统完成安装即可。
等待安装完毕,重新启动进入系统,就能够开始配置环境啦。
系统基础环境配置
配置系统同样分为三步,分别是:
- 初始化 SSH 环境,确保我们能够从外部设备访问这台计算设备。
- 完成系统软件包的升级,打上所有的安全漏洞补丁,规避基础安全问题。
- 安装显卡驱动,让显卡能够在操作系统层面能够正常使用。
更详细的配置过程,可以参考这篇文章的“系统基础配置”部分。本文只提一些必要的步骤。
初始化 SSH 环境
如果你在安装过程中没有设置和安装 ssh,为了让我们能够通过其他的设备进行访问,可以在设备上手动安装 openssh-server:
sudo apt-get update && sudo apt-get install -y openssh-server
安装完毕之后,我们可以通过命令 ip addr 搭配 grep inet 来获取设备的 IP:(通过在路由器里找登录设备也是可行的)
# ip addr | grep inet
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 10.11.12.178/24 brd 10.11.12.255 scope global dynamic noprefixroute enp2s0
...
然后,使用 ssh username@10.11.12.178 (根据你的实际情况调整) 就可以登录设备了。如果你也不喜欢使用“密码登录”服务器,可以选择使用“信任的证书”来进行鉴权:
ssh-copy-id -i ~/.ssh/your-private-key 10.11.12.178
soulteary@10.11.12.178's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '10.11.12.178'"
and check to make sure that only the key(s) you wanted were added.
然后再使用 ssh 10.11.12.178 就能够远程访问设备啦:
# ssh 10.11.12.178
Welcome to Ubuntu 22.10 (GNU/Linux 5.19.0-35-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
145 updates can be applied immediately.
84 of these updates are standard security updates.
To see these additional updates run: apt list --upgradable
Last login: Tue Mar 21 22:30:24 2023 from 10.11.12.90
soulteary@LEGION-REN9000K-34IRZ:~$
软件包升级
完成系统安装之后,首先需要更新基础软件,以及给系统打上安全补丁。
sudo apt update && sudo apt -y upgrade
如果你觉得直接访问 Ubuntu 官方软件源比较慢,可以切换软件源到国内,我这里使用了“清华源”(如何切换可参考本小节开头的引文)。
命令执行过后,将看到类似下面的日志:
Get:1 http://mirrors.tuna.tsinghua.edu.cn/ubuntu kinetic InRelease [267 kB]
Get:2 http://mirrors.tuna.tsinghua.edu.cn/ubuntu kinetic-updates InRelease [118 kB]
Get:3 http://mirrors.tuna.tsinghua.edu.cn/ubuntu kinetic-backports InRelease [99.9 kB]
Get:4 http://mirrors.tuna.tsinghua.edu.cn/ubuntu kinetic-security InRelease [109 kB]
Get:5 http://mirrors.tuna.tsinghua.edu.cn/ubuntu kinetic/main amd64 Packages [1,384 kB]
...
Processing triggers for libc-bin (2.36-0ubuntu4) ...
Processing triggers for man-db (2.10.2-2) ...
Processing triggers for udev (251.4-1ubuntu7.1) ...
Processing triggers for initramfs-tools (0.140ubuntu17) ...
update-initramfs: Generating /boot/initrd.img-5.19.0-35-generic
Processing triggers for hicolor-icon-theme (0.17-2) ...
Processing triggers for ca-certificates (20211016ubuntu0.22.10.1) ...
Updating certificates in /etc/ssl/certs...
0 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d...
done.
安装显卡驱动
完成了基础软件的更新,就可以来进行显卡驱动的安装了。我们可以通过 nvidia-detector 来获取最新的稳定版本的驱动。
# nvidia-detector
nvidia-driver-525
在安装驱动之前,我们暂时是不能使用 nvidia-smi 管理工具的。
# nvidia-smi
zsh: command not found: nvidia-smi
安装驱动时,建议除了安装 nvidia-driver 驱动,可以顺带安装 nvidia-dkms ,方便后续如果需要升降级内核的时候,减少不必要的麻烦:
sudo apt-get install -y nvidia-driver-525 nvidia-dkms-525
完成驱动安装之后,再次执行 nvidia-smi ,我们就可以进行显卡管理啦。
# nvidia-smi
Tue Mar 21 22:53:37 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 On | Off |
| 31% 34C P8 19W / 450W | 53MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1331 G /usr/lib/xorg/Xorg 36MiB |
| 0 N/A N/A 1552 G /usr/bin/gnome-shell 15MiB |
+-----------------------------------------------------------------------------+
GPU Docker 环境的安装和配置
安装配置一个能够调用显卡的 Docker 环境,只需要两步:安装 Docker 环境,以及安装 GPU Docker 运行时。
宿主机的 Docker 安装
宿主机的 Docker 基础环境的安装,可以参考这篇文章中“更简单的 Docker 安装”小节,完成快速的安装配置。
安装 Docker 显卡运行时
想要在 Docker 中能够“调用显卡”,我们需要安装“NVIDIA 容器工具包存储库”,这个项目是开源的,本文主要介绍 Ubuntu 环境的快速安装配置,如果你涉及其他系统,可以在 Container Toolkit 官方文档中找到相关参考。
如果你使用的是 Ubuntu LTS 版本,诸如 22.04、20.04、18.04 可以直接使用,如果你和我一样,追求最新的硬件支持和系统变化,使用的是 Non-LTS,可以通过指定安装版本为上一个版本的 LTS 来解决安装问题,比如为 Ubuntu 22.10 安装:
distribution=ubuntu22.04 && \
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && \
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
命令执行完毕之后,我们的系统中就添加好了 Lib Nvidia Container 工具的软件源啦,然后更新系统软件列表,使用命令安装 nvidia-container-toolkit 即可:
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
完成 nvidia-container-toolkit 的安装之后,我们继续执行 nvidia-ctk runtime configure 命令,为 Docker 添加 nvidia 这个运行时。完成后,我们的应用就能在容器中使用显卡资源了:
sudo nvidia-ctk runtime configure --runtime=docker
命令执行成功,我们将看到类似下面的日志输出:
# sudo nvidia-ctk runtime configure --runtime=docker
INFO[0000] Loading docker config from /etc/docker/daemon.json
INFO[0000] Successfully loaded config
INFO[0000] Flushing docker config to /etc/docker/daemon.json
INFO[0000] Successfully flushed config
INFO[0000] Wrote updated config to /etc/docker/daemon.json
INFO[0000] It is recommended that the docker daemon be restarted.
在完成配置之后,别忘记重启 docker 服务,让配置生效:
sudo systemctl restart docker
服务重启完毕,我们查看 Docker 运行时列表,能够看到 nvidia 已经生效啦。
# docker info | grep Runtimes
Runtimes: nvidia runc io.containerd.runc.v2
AI 相关的 Docker 镜像,及实际使用
相比较直接安装和配置深度学习应用所需要的环境,通过 Docker,我们可以下载到各种具备不同能力的“开箱即用”的环境,我一般会优先从下面三个地址获取基础镜像:
- https://catalog.ngc.nvidia.com/containers
- https://hub.docker.com/u/nvidia
- https://hub.docker.com/u/pytorch
诸如在 RTX 4090 这类卡刚发布后,相比较自己从零到一构建镜像,官方镜像是个不错的额外选项,能够更好发挥显卡性能,还不需要折腾。
举个例子,如果我们想使用最新的 CUDA 版本,搭配一个能开箱即用的 PyTorch 环境,而此时 Conda 社区还未做兼容适配,最好的选择不是我们去翻不同软件包社区,做一些 Hack 完成安装,而是直接使用官方的镜像。
比如,一条命令,我们就能够启动一个包含了最新版本的 CUDA 和 PyTorch 的实验环境(环境的发布文档):
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:23.02-py3
当然,我们也可以调整命令,比如执行 nvidia-smi 来检查运行环境以及获取显卡的状态:
# docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:23.02-py3 nvidia-smi
=============
== PyTorch ==
=============
NVIDIA Release 23.02 (build 53420872)
PyTorch Version 1.14.0a0+44dac51
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
NOTE: The SHMEM allocation limit is set to the default of 64MB. This may be
insufficient for PyTorch. NVIDIA recommends the use of the following flags:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 ...
Tue Mar 21 15:30:19 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 On | Off |
| 31% 33C P0 33W / 450W | 174MiB / 24564MiB | 5% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
在上面的命令中,我们虽然调用了显卡,但是输出的日志中提醒我们并行计算需要的缓存是不足的。为了最佳的性能实现,我们可以继续调整命令如下:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -it --rm nvcr.io/nvidia/pytorch:23.02-py3
当然,在社区中对于 Nvidia 官方推荐的参数 有一些 “不同的看法”。不论你的选择是什么,在实际使用过程中,因为结合了容器能力,我们的应用可以更轻松的指定资源。文件路径、CPU 资源、内存资源,以及最重要的,指定显卡。
比如,将上文中的 --gpus all 替换为显卡编号,即可在多卡机器中指定某张卡来运行程序:
docker run --gpus "0" --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -it --rm nvcr.io/nvidia/pytorch:23.02-py3
如果你希望八卡的机器只有单数卡能够被容器访问,可以调整参数为:
--gpus "1,3,5,7"
其他
聊一些其他的有趣的话题。
较新显卡的设备兼容性:RTX 4090 或其他
如果你细心观察社区的反馈,你会发现主流框架也好、社区训练框架也罢,大家对于新硬件的适配速度、以及生态中不同组件新版本的支持是比较慢的,诸如下面这类问题:
- PyTorch: CUDA 12 Support Tracking Issue
- HF trainer: RTX 4090 Huggingface Trainer Compatible?
- yolov7: Training yolov7 on RTX4090
- huggingface/diffusers: Performance Issue with RTX 4090 and all SD/Diffusers versions
当我们遇到这类问题,除了死磕,一点点改上下游依赖和代码之外,还有一个简单的方案就是基于本文提到的方案,使用官方已经适配好的 PyTorch、CUDA 版本的容器来运行程序。如果你追求极致性能,还可以将官方构建好的 so 文件,复制到具有相同版本的 Ubuntu 镜像甚至是裸金属服务器上使用。
使用自定义内核或新版驱动,无法和 Nvidia 驱动通信的问题
有一些时候,我们想测试最新版本的驱动,或者某个新版本的 Linux 内核是否能够带来性能提升。
如果你没有和上文中,在操作系统安装细节中,处理 BIOS 设置,很大概率你将遇到 “NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.” 的问题。
# docker run --gpus all --ipc=host --ulimit memlock=-1 -it --rm nvcr.io/nvidia/pytorch:23.02-py3
docker: Error response from daemon: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running hook #0: error running hook: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: initialization error: nvml error: driver not loaded: unknown.
(base) soulteary in ~/llama λ nvidia-smi
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
此时,如果你使用 modprobe 手动挂载驱动,可能是不行的。
# sudo modprobe nvidia
modprobe: ERROR: could not insert 'nvidia': Key was rejected by service
正确的解决问题的方式,是前往 BIOS,关闭 secure boot 选项。
最后
好啦,本篇文章就先写到这里。下一篇相关的文章里,我们或许会聊聊如何逆传统的 Docker 最佳实践,让容器化身为稳定的开发、训练环境,以及优雅的自动提供对外公开访问能力。
–EOF