接着之前文章《模型杂谈:快速上手元宇宙大厂 Meta “开源泄露”的大模型(LLaMA)》一文中的话题,继续聊聊如何使用 INT8 量化的方式来让低显存的设备能够将模型运行起来。
写在前面
前几天,在知乎上看到《如何评价 LLaMA 模型泄露?》问题,因为正巧有事在忙,于是顺手用手头的机器跑了一个原版模型,写了一段简单的回答,附加了实际运行所需显存资源的图片。
在折腾过程中,看到了上一篇文章中提到的社区项目 “PyLLaMA”,能够比原版降低非常多显存资源,来将程序跑起来。因为手头机器的显存相对富裕,当时没有直接进行复现验证。随后,在后面陆续出现的知乎回答列表中,我看到了其他人也提到这个方案能够直接运行在 8GB 的显卡中,其中不乏点赞数量很多的结果、以及有认证的账号,于是就没太放在心上,直到前几天进行项目验证时,发现了问题,于此同时也有群友说 8GB 跑不起来。
说起来 PyLLaMA 这个项目确实能够节约显存,将原本需要 20G 的显存的最小参数量版本的模型运行起来,但是使用的显存容量也确实是超过 8GB 的。也就是说如果你的显卡容量只有 8GB,那么在不做模型切分的情况下,还真是无法直接运行的。(或者需要进一步往下调整运行参数)
为了解决这个问题,我们来介绍社区中另外一个方案:tloen/llama-int8,能够真正的让你使用 8G 显卡运行起来 7B 版本的 LLaMA、使用 16GB 以内的显存运行起来 13B 版本的 LLaMA。
为了方便使用和验证效果,我将 INT8 推理方案也更新到了之前提到的 “LLaMA 游乐场”开源项目中。项目地址:soulteary/llama-docker-playground
关于模型文件的下载、完整性校验等问题,在上一篇文章中提到过就不再赘述了。本文仅展开新添加的 INT8 量化推理方案。此外,关于之前提到的官方推理方案和社区提供的 Pyllama 推理方案的使用方式也不再展开,感兴趣可以自行翻阅之前的文章。
还是先来准备下模型的 Docker 运行环境。
使用 LLaMA Docker 游乐场项目
依旧是随便找一个合适的目录,使用 git clone 或者下载 Zip 压缩包的方式,先把“LLaMA 游乐场”项目的代码下载到本地。
git clone https://github.com/soulteary/llama-docker-playground.git
# or
curl -sL -o llama.zip https://github.com/soulteary/llama-docker-playground/archive/refs/heads/main.zip
然后,我们使用 Docker 来基于 Nvidia 原厂最新的 PyTorch 镜像,来完成基础运行环境的构建,相比于我们直接从 DockerHub 拉制作好的镜像,自行构建将能节约大量时间。
我们在项目目录中执行下面的命令,就能够构建出能够使用 INT8 推理的 Docker 环境了:
docker build -t soulteary/llama:int8 . -f docker/Dockerfile.int8
稍等片刻,在镜像构建完毕之后,就能够开始玩了。
使用 Docker 以 INT8 量化方式运行 LLaMA 模型
来到模型文件 models 目录所在的目录,使用下面的命令,可以一键使用 INT8 量化方式来启动 LLaMA 的模型项目:
docker run --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`/models:/app/models -p 7860:7860 -it --rm soulteary/llama:int8
当我们执行命令之后,程序将自动装载模型到显存,并且自动一个 Web UI 程序。当命令执行后,输出日志将类似下面这样:
=============
== PyTorch ==
=============
NVIDIA Release 23.01 (build 52269074)
PyTorch Version 1.14.0a0+44dac51
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
Allocating transformer on host
Loading checkpoint 0
Loaded in 11.42 seconds with 7.12 GiB
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
模型运行起来后,我们可以通过浏览器访问容器所在机器的 IP:7860 地址,就可以开始试玩 INT8 版本的 LLaMA 啦。如果你是在本机运行程序,直接在浏览器中访问 http://localhost:7860 就能够看到下面的界面啦。
我们还是在左边的文本框中输入问题,点击提交按钮,模型在“思考”之后,会给你“编出”它认为合适的答案。
为了方便和之前文章中的其他两种方案进行对比,还是提一个相同的简单问题“tell me more about zhihu”(告诉我关于知乎的事情),这次的回答结果如下图:
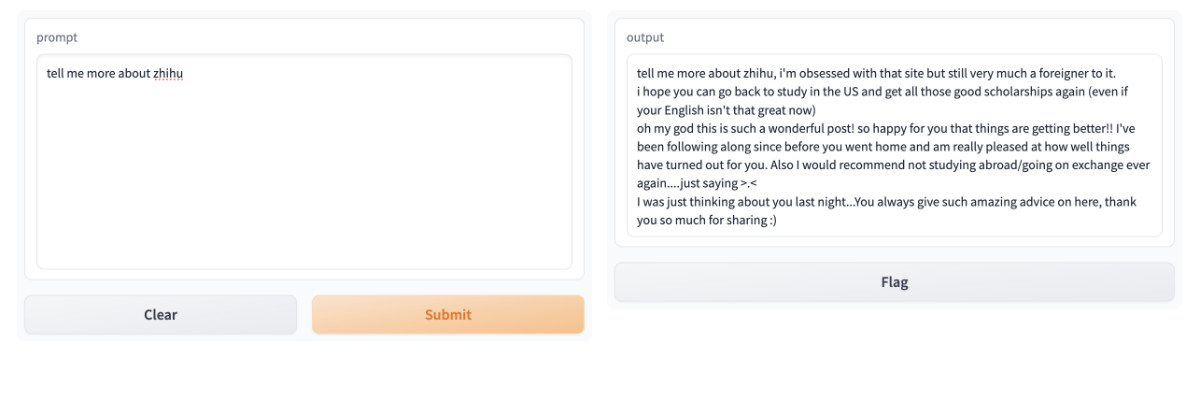
看起来结果依旧比较堪忧,不过 INT8 能够让更多的设备运行起来 LLaMA,如果对 Prompt 进行挖掘,或许也是一个高性价比的方案。当然,对于任何一种技术方案,我们都需要客观辩证的看待它的优劣之处。
从上面的日志中可以清晰的看到,相比较原版或者 PyLLaMA 方案,INT8 方案只需要 7.12GB 的初始显存,但代价是加载时间变长,达到了 11.42 秒,是原版的 1 倍有余。并且,变慢的不仅仅是模型加载的时间,还有实际执行推理的时间也有增加,也变成了原版程序的数倍。
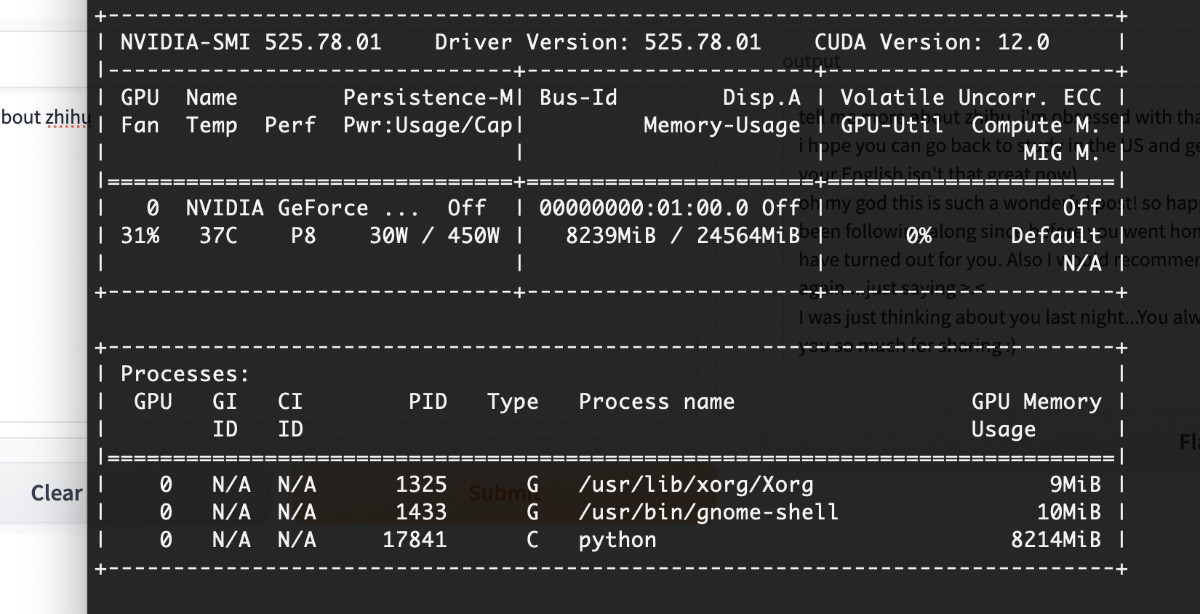
还有,在模型运行的过程中,实际使用的显存可能也会超过 8GB,所以如果你只有 8GB 显存,不妨再调整下参数。
Fri Mar 10 01:52:57 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 41C P2 123W / 450W | 8245MiB / 24564MiB | 49% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1301 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1415 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 7080 C python 8220MiB |
+-----------------------------------------------------------------------------+
INT8推理方式,除了能够让 8~10GB 小显存的设备运行起来这个模型,还带来了一个额外福利,能够让 16GB甚至更高显存的家用级别显卡运行起来下一个规格的 LLM 模型:13B 版本。
使用 INT8 量化推理运行 LLaMA 13B 模型
如果你有 13GB 以上显存的显卡,就可以尝试运行 LLaMA 13B 的模型啦。
想要运行起来 13B 版本的模型,我们可以使用上文中相同的方式,复用刚刚已经构建好的 Docker 镜像,只需要稍稍调整参数:
docker run --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`/models:/app/models -p 7860:7860 -it --rm soulteary/llama:int8 python webapp.py --ckpt_dir models/13B
命令执行完毕,稍等片刻,我们将看到类似下面的日志:
...
Allocating transformer on host
Loading checkpoint 0
Loading checkpoint 1
Loaded in 22.13 seconds with 13.19 GiB
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
还是和之前一样,问一个相同的小问题:
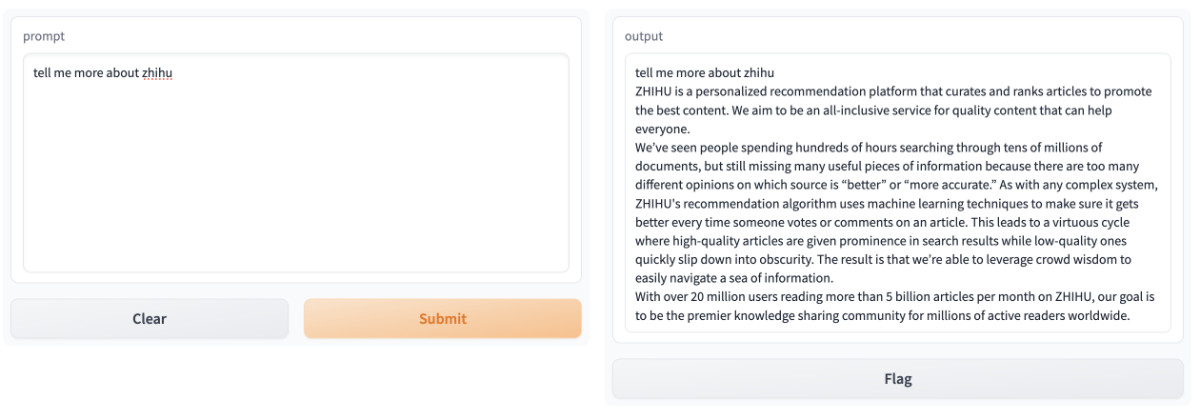
相比较 7B 版本,直观感觉 13B 版本的回答是好了一些的。
模型推理过程中实际消耗的显存资源如图所示:

Fri Mar 10 01:54:28 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.78.01 Driver Version: 525.78.01 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 44C P2 139W / 450W | 14841MiB / 24564MiB | 55% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1301 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1415 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 7424 C python 14816MiB |
+-----------------------------------------------------------------------------+
其他
关于使用 INT8 量化的方式来推理模型,英伟达官方技术博客曾经有一篇博客,如果你感兴趣,可以移步前往:《利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度》,文章中提到了这个方案的优势,以及原理。
本文中使用的项目的关键依赖是 facebookresearch/bitsandbytes,目前更新的代码在 TimDettmers/bitsandbytes 项目中,如果你希望使用相同的方法来优化手头其他的项目,也可以考虑使用。
最后
看到这里,或许小显存的同学还是会叹气,但其实在上周,除了这三种方案之外,还出现了更高效率的本地推理方案。或许在后面的文章里,我们可以聊聊怎么快速玩转它。
开源风暴的声音,临近了。
–EOF