这篇文章中,我们来聊聊如何快速上手一众模型里,具有 14B 参数,但是比较特别的 RNN 模型:ChatRWKV。
本文将介绍如何快手上手,包含使用一张 24 显存的 4090 高速推理生成内容,以及如何只使用 1.5G 显存就能运行这个模型。
写在前面
如果你有 20GB 左右的显存,哪怕是一张家用游戏显卡,都可以得到一个惊人的推理效率。当然,如果你手头显卡显存没有那么大,只要有 2GB,将这个模型跑起来也问题不大。
二月初的时候,在网上看到了这个模型,当时折腾了一把 Docker 容器,但是因为手头还有其他的事情,就放下了。

最近群里有朋友提到想试用下,正好在等待昨天文章中提到的 65B 大模型的 fine-tune 结果,那么就写一篇和它相关的内容吧。
如果你只好奇如何使用 1.5 G 显存来运行模型,可以仅阅读模型准备工作和 1.5 G 模型部分相关的内容。
模型运行的准备工作
这次的模型的准备工作只有两步:获取包含容器的项目代码,构建容器镜像。
获取 Docker ChatRWKV 项目代码
为了能够更简单的运行这个模型,我对官方项目进行了 fork,并添加了可以快速复现模型的容器配置和程序,项目地址是:soulteary/docker-ChatRWKV。
你可以通过下面的方式来获取代码:
git clone https://github.com/soulteary/docker-ChatRWKV.git
# or
curl -sL -o chatrwkv.zip https://github.com/soulteary/docker-ChatRWKV/archive/refs/heads/main.zip
获取完必要的代码之后,我们需要配置和准备容器环境。
准备容器环境
在之前的文章《基于 Docker 的深度学习环境:入门篇》中,我们提到过如何配置 Docker 来和显卡交互,这里就不过多赘述了。你可以执行简单的一条命令,来创建一个“干净又卫生”的容器环境。
进入项目目录,使用 Nvidia 原厂的 PyTorch Docker 基础镜像来完成基础环境的构建,相比于我们直接从 DockerHub 拉制作好的镜像,自行构建将能节约大量时间。
docker build -t soulteary/model:chatrwkv . -f docker/Dockerfile
构建过程中,因为会从 HF 下载一个近 30G 的模型文件,所以会比较漫长。
# docker build -t soulteary/model:chatrwkv . -f docker/Dockerfile
[+] Building 1129.8s (8/12)
=> [internal] load .dockerignore 0.1s
=> => transferring context: 2B 0.0s
=> [internal] load build definition from Dockerfile 0.1s
=> => transferring dockerfile: 850B 0.0s
=> [internal] load metadata for nvcr.io/nvidia/pytorch:23.02-py3 0.0s
=> CACHED [1/8] FROM nvcr.io/nvidia/pytorch:23.02-py3 0.0s
=> [internal] load build context 0.1s
=> => transferring context: 5.72kB 0.0s
=> [2/8] RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple && pip install huggingface_hub 4.6s
=> [3/8] WORKDIR /app 0.1s
=> [4/8] RUN cat > /get-models.py <<EOF 0.3s
=> [5/8] RUN python /get-models.py && rm -rf /get-models.py && pip install ninja rwkv==0.6.2 gradio 1124.7s
=> => # Downloading (…)ctx8192-test1050.pth: 99%|█████████▉| 27.9G/28.3G [08:06<00:06, 57.6MB/s]
当镜像构建完毕之后,就能够开始玩啦。
在聊 1.5G 的“极限挑战”之前,我们先使用相对充足的资源,快速将模型运行起来,体验下它的执行效率。
使用 Docker 快速运行 ChatRWKV
如果你的显卡有 20G 或以上的显存,直接执行下面的命令即可启动一个带界面的 ChatRWKV 模型程序:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 soulteary/model:chatrwkv
当你执行完命令之后,将看到类似下面的日志:
=============
== PyTorch ==
=============
NVIDIA Release 23.02 (build 53420872)
PyTorch Version 1.14.0a0+44dac51
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
Using /root/.cache/torch_extensions/py38_cu120 as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py38_cu120/wkv_cuda...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py38_cu120/wkv_cuda/build.ninja...
Building extension module wkv_cuda...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/3] c++ -MMD -MF wrapper.o.d -DTORCH_EXTENSION_NAME=wkv_cuda -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1013\" -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++14 -c /usr/local/lib/python3.8/dist-packages/rwkv/cuda/wrapper.cpp -o wrapper.o
[2/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=wkv_cuda -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1013\" -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=1 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_52,code=sm_52 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_61,code=sm_61 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_90,code=compute_90 -gencode=arch=compute_90,code=sm_90 --compiler-options '-fPIC' -t 4 -std=c++17 --use_fast_math -O3 --extra-device-vectorization -c /usr/local/lib/python3.8/dist-packages/rwkv/cuda/operators.cu -o operators.cuda.o
[3/3] c++ wrapper.o operators.cuda.o -shared -L/usr/local/lib/python3.8/dist-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o wkv_cuda.so
Loading extension module wkv_cuda...
RWKV_JIT_ON 1 RWKV_CUDA_ON 1 RESCALE_LAYER 6
Loading /root/.cache/huggingface/hub/models--BlinkDL--rwkv-4-pile-14b/snapshots/5abf33a0a7aca020a5d3fc189a50e9bf17def979/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth ...
Strategy: (total 40+1=41 layers)
* cuda [float16, uint8], store 20 layers
* cuda [float16, float16], store 21 layers
0-cuda-float16-uint8 1-cuda-float16-uint8 2-cuda-float16-uint8 3-cuda-float16-uint8 4-cuda-float16-uint8 5-cuda-float16-uint8 6-cuda-float16-uint8 7-cuda-float16-uint8 8-cuda-float16-uint8 9-cuda-float16-uint8 10-cuda-float16-uint8 11-cuda-float16-uint8 12-cuda-float16-uint8 13-cuda-float16-uint8 14-cuda-float16-uint8 15-cuda-float16-uint8 16-cuda-float16-uint8 17-cuda-float16-uint8 18-cuda-float16-uint8 19-cuda-float16-uint8 20-cuda-float16-float16 21-cuda-float16-float16 22-cuda-float16-float16 23-cuda-float16-float16 24-cuda-float16-float16 25-cuda-float16-float16 26-cuda-float16-float16 27-cuda-float16-float16 28-cuda-float16-float16 29-cuda-float16-float16 30-cuda-float16-float16 31-cuda-float16-float16 32-cuda-float16-float16 33-cuda-float16-float16 34-cuda-float16-float16 35-cuda-float16-float16 36-cuda-float16-float16 37-cuda-float16-float16 38-cuda-float16-float16 39-cuda-float16-float16 40-cuda-float16-float16
emb.weight f16 cpu 50277 5120
blocks.0.ln1.weight f16 cuda:0 5120
blocks.0.ln1.bias f16 cuda:0 5120
blocks.0.ln2.weight f16 cuda:0 5120
blocks.0.ln2.bias f16 cuda:0 5120
blocks.0.att.time_decay f32 cuda:0 5120
blocks.0.att.time_first f32 cuda:0 5120
blocks.0.att.time_mix_k f16 cuda:0 5120
blocks.0.att.time_mix_v f16 cuda:0 5120
blocks.0.att.time_mix_r f16 cuda:0 5120
blocks.0.att.key.weight i8 cuda:0 5120 5120
blocks.0.att.value.weight i8 cuda:0 5120 5120
blocks.0.att.receptance.weight i8 cuda:0 5120 5120
blocks.0.att.output.weight i8 cuda:0 5120 5120
blocks.0.ffn.time_mix_k f16 cuda:0 5120
blocks.0.ffn.time_mix_r f16 cuda:0 5120
blocks.0.ffn.key.weight i8 cuda:0 5120 20480
blocks.0.ffn.receptance.weight i8 cuda:0 5120 5120
blocks.0.ffn.value.weight i8 cuda:0 20480 5120
............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
blocks.39.ln1.weight f16 cuda:0 5120
blocks.39.ln1.bias f16 cuda:0 5120
blocks.39.ln2.weight f16 cuda:0 5120
blocks.39.ln2.bias f16 cuda:0 5120
blocks.39.att.time_decay f32 cuda:0 5120
blocks.39.att.time_first f32 cuda:0 5120
blocks.39.att.time_mix_k f16 cuda:0 5120
blocks.39.att.time_mix_v f16 cuda:0 5120
blocks.39.att.time_mix_r f16 cuda:0 5120
blocks.39.att.key.weight f16 cuda:0 5120 5120
blocks.39.att.value.weight f16 cuda:0 5120 5120
blocks.39.att.receptance.weight f16 cuda:0 5120 5120
blocks.39.att.output.weight f16 cuda:0 5120 5120
blocks.39.ffn.time_mix_k f16 cuda:0 5120
blocks.39.ffn.time_mix_r f16 cuda:0 5120
blocks.39.ffn.key.weight f16 cuda:0 5120 20480
blocks.39.ffn.receptance.weight f16 cuda:0 5120 5120
blocks.39.ffn.value.weight f16 cuda:0 20480 5120
ln_out.weight f16 cuda:0 5120
ln_out.bias f16 cuda:0 5120
head.weight f16 cuda:0 5120 50277
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
等到看到 Running on local URL: http://0.0.0.0:7860 时,打开浏览器,访问运行这个容器机器的 IP (如果是本地运行,访问 http://127.0.0.1:7860 )就能看到下面的界面啦。
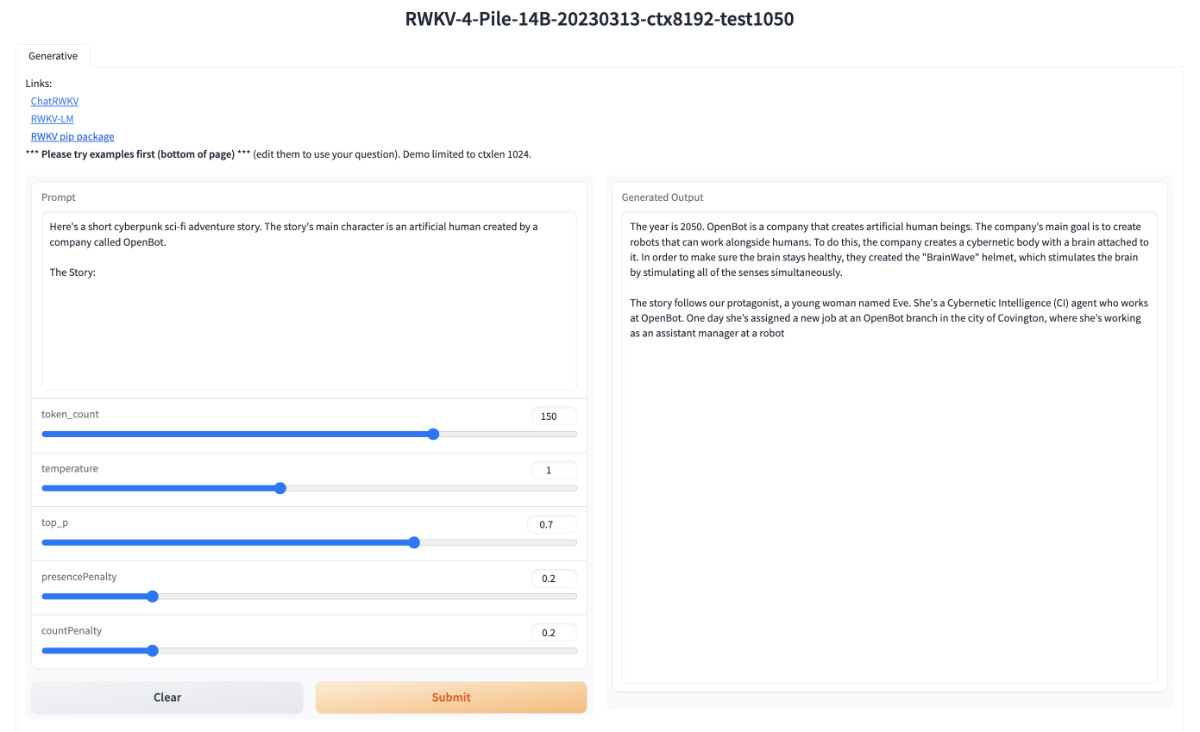
因为是使用 gradio 默认模版,所以界面非常简单(简陋),在左边输入你要测试的内容,或者使用页面下方预置的文案,然后点击“提交”按钮,等待模型疯狂输出即可。

可以看到运行速度还是非常快的,如果能够结合我们自己的语料进行 fine-tune,或许也会有更好的效果。不过目前看来距离每天在使用的工具还有一段距离,希望项目能够越来越好。
此时,我们如果使用 nvidia-smi 管理工具来查看显卡状态,能够看到显存使用量在 20G 左右。
nvidia-smi
Sat Mar 25 14:09:48 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 34C P8 22W / 450W | 20775MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1290 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1506 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 4120 C python 20750MiB |
+-----------------------------------------------------------------------------+
预转换模型格式
虽然 ChatRWKV 运行速度很快,但是每次启动的时候,都会十分漫长的进行载入操作,这里最耗时的部分是:当程序启动时,会将下载好的开源模型,根据“固定策略”进行格式转换。
如果能够预先执行一次这样的转换操作,那么我们将节约大量的运行时间。以及节约不必要的计算资源使用。官方提供了一段代码,简单讲解了项目是如何转换模型格式的,详细的转换细节,在项目提供的 PyPI 包的源代码中。
我们可以执行下面的命令,启动包含我们之前下载好模型的容器镜像,并一键进入交互 shell 里:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 soulteary/model:chatrwkv bash
然后对官方的例子进行一些简化操作:
from huggingface_hub import hf_hub_download
title = "RWKV-4-Pile-14B-20230313-ctx8192-test1050"
model_path = hf_hub_download(repo_id="BlinkDL/rwkv-4-pile-14b", filename=f"{title}.pth")
from rwkv.model import RWKV
RWKV(model=model_path, strategy='cuda fp16i8 *20 -> cuda fp16', convert_and_save_and_exit = f"./models/{title}.pth")
这里的转换策略(strategy)保持和容器中 app.py(官方例子)一致即可,关于 RWKV 策略的使用,我们下文会提到,暂时不展开。
我们将上面的代码保存为 convert.py,然后执行 python convert.py,耐心等待模型进行格式转换即可:
# python convert.py
RWKV_JIT_ON 1 RWKV_CUDA_ON 0 RESCALE_LAYER 6
Loading /root/.cache/huggingface/hub/models--BlinkDL--rwkv-4-pile-14b/snapshots/5abf33a0a7aca020a5d3fc189a50e9bf17def979/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth ...
Strategy: (total 40+1=41 layers)
* cuda [float16, uint8], store 20 layers
* cuda [float16, float16], store 21 layers
0-cuda-float16-uint8 1-cuda-float16-uint8 2-cuda-float16-uint8 3-cuda-float16-uint8 4-cuda-float16-uint8 5-cuda-float16-uint8 6-cuda-float16-uint8 7-cuda-float16-uint8 8-cuda-float16-uint8 9-cuda-float16-uint8 10-cuda-float16-uint8 11-cuda-float16-uint8 12-cuda-float16-uint8 13-cuda-float16-uint8 14-cuda-float16-uint8 15-cuda-float16-uint8 16-cuda-float16-uint8 17-cuda-float16-uint8 18-cuda-float16-uint8 19-cuda-float16-uint8 20-cuda-float16-float16 21-cuda-float16-float16 22-cuda-float16-float16 23-cuda-float16-float16 24-cuda-float16-float16 25-cuda-float16-float16 26-cuda-float16-float16 27-cuda-float16-float16 28-cuda-float16-float16 29-cuda-float16-float16 30-cuda-float16-float16 31-cuda-float16-float16 32-cuda-float16-float16 33-cuda-float16-float16 34-cuda-float16-float16 35-cuda-float16-float16 36-cuda-float16-float16 37-cuda-float16-float16 38-cuda-float16-float16 39-cuda-float16-float16 40-cuda-float16-float16
emb.weight f16 cpu 50277 5120
blocks.0.ln1.weight f16 cpu 5120
blocks.0.ln1.bias f16 cpu 5120
blocks.0.ln2.weight f16 cpu 5120
blocks.0.ln2.bias f16 cpu 5120
blocks.0.att.time_decay f32 cpu 5120
blocks.0.att.time_first f32 cpu 5120
blocks.0.att.time_mix_k f16 cpu 5120
blocks.0.att.time_mix_v f16 cpu 5120
blocks.0.att.time_mix_r f16 cpu 5120
blocks.0.att.key.weight i8 cpu 5120 5120
blocks.0.att.value.weight i8 cpu 5120 5120
blocks.0.att.receptance.weight i8 cpu 5120 5120
blocks.0.att.output.weight i8 cpu 5120 5120
blocks.0.ffn.time_mix_k f16 cpu 5120
blocks.0.ffn.time_mix_r f16 cpu 5120
blocks.0.ffn.key.weight i8 cpu 5120 20480
blocks.0.ffn.receptance.weight i8 cpu 5120 5120
blocks.0.ffn.value.weight i8 cpu 20480 5120
............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
blocks.39.ln1.weight f16 cpu 5120
blocks.39.ln1.bias f16 cpu 5120
blocks.39.ln2.weight f16 cpu 5120
blocks.39.ln2.bias f16 cpu 5120
blocks.39.att.time_decay f32 cpu 5120
blocks.39.att.time_first f32 cpu 5120
blocks.39.att.time_mix_k f16 cpu 5120
blocks.39.att.time_mix_v f16 cpu 5120
blocks.39.att.time_mix_r f16 cpu 5120
blocks.39.att.key.weight f16 cpu 5120 5120
blocks.39.att.value.weight f16 cpu 5120 5120
blocks.39.att.receptance.weight f16 cpu 5120 5120
blocks.39.att.output.weight f16 cpu 5120 5120
blocks.39.ffn.time_mix_k f16 cpu 5120
blocks.39.ffn.time_mix_r f16 cpu 5120
blocks.39.ffn.key.weight f16 cpu 5120 20480
blocks.39.ffn.receptance.weight f16 cpu 5120 5120
blocks.39.ffn.value.weight f16 cpu 20480 5120
ln_out.weight f16 cpu 5120
ln_out.bias f16 cpu 5120
head.weight f16 cpu 5120 50277
Saving to ./models/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth...
Converted and saved. Now this will exit.
不需要太长时间,当看到“Converted and saved.”的提示时,我们就能够得到预先转换好格式的模型啦,使用官方默认策略,能够发现模型尺寸还下降了 10G 左右:
# du -hs models/*
21G models/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth
然后,手动执行 python app.py,就能快速启动模型应用啦。
挑战 1.5G 小显存运行 ChatRWKV 模型
想要使用小显存资源来运行模型,现阶段有一些相对靠谱的方法:
- 将模型量化为8位或者4位,甚至是更低,降低模型文件尺寸的同时,将部分显存卸载到 CPU 使用的内存中。
- 将模型使用流式方式进行模型加载,减少同一时间显存中的资源占用量。
在官方文档中,我们能够找到一个非常“极限”的方案,将几乎所有的 layers 都进行流式处理,策略内容:'cuda fp16i8 *0+ -> cpu fp32 *1'。
不过,在实战之前,还需要一个额外的准备工作。
如何限制显卡显存,模拟小显存设备
因为我手头就一张家用游戏卡(RTX4090),所以我需要想办法限制显卡的显存。
使用 GPU 服务器的同学应该知道 Nvidia 有一个 MIG(NVIDIA Multi-Instance GPU)技术,能够对显卡进行虚拟化和限制应用使用的具体缓存资源上限。但是,这个功能只开放给了几种“高级卡”:A30、A100、H100。
但好在,不论是 Tensorflow、还是 PyTorch,都支持软限制软件的显存用量,虽然没有到硬件层,但是在某些场景用于模拟低显存的设备足够啦。
在 ChatRWKV 项目中,作者使用了 PyTorch,所以我们只需要在引用 Torch 的地方随手加上资源限制用量声明即可:
import os, gc, torch
torch.cuda.set_per_process_memory_fraction(0.5)
比如,上面的代码中,我们通过限制最多只能使用到 50% 的显存,就将显卡从 4090 降级到了RTX 3060 的显卡容量水平。
此时,我们可以进行一个简单的验证,使用下面的命令,进入一个交互式的 shell 中:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 soulteary/model:chatrwkv bash
将上面的代码加入到 app.py 中合适的地方,然后执行 python app.py,不出意外,将得到证明限制有效的“运行报错”。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 200.00 MiB (GPU 0; 23.65 GiB total capacity; 11.46 GiB already allocated; 11.48 GiB free; 11.82 GiB allowed; 11.71 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
一键预转换模型格式
上文中,我们详细聊过了“原理”和“细节实现”,所以这里我们就不再做没意义的重复啦,直接执行下面的命令,开始模型格式转换:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 -v `pwd`/models:/app/ChatRWKV/models soulteary/model:chatrwkv python convert.mini.py
命令执行完毕,我们将得到一个 15GB 左右的模型文件。
# du -hs models/*
15G models/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth
一键运行只需要 1.5G 显存的模型程序
想要低显存资源使用程序,只需要执行下面的命令:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 -v `pwd`/models:/app/ChatRWKV/models soulteary/model:chatrwkv python webui.mini.py
当命令执行完毕之后,我们使用 nvidia-smi 查看资源,能够看到模型“待命”状态只需要 500MB 左右的显存资源。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 33C P8 22W / 450W | 463MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1290 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1506 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 33684 C python 406MiB |
+-----------------------------------------------------------------------------+
实际使用的过程中,内存会根据实际输出的内容的多少产生变化,我个人多次试验,基本上使用在 800MB ~ 1.4GB 左右。
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 46C P2 132W / 450W | 1411MiB / 24564MiB | 84% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1290 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1506 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 10942 C python 1354MiB |
+-----------------------------------------------------------------------------+
最后
本篇文章就先写到这里啦。
至于模型的效果如何,属于小马过河的问题,自己来试试吧。
–EOF