本篇文章聊聊,如何使用 Ollama、Dify 和 Docker 来完成本地 Llama 3.1 模型服务的搭建。
如果你需要将 Ollama 官方不支持的模型运行起来,或者将新版本 llama.cpp 转换的模型运行起来,并且想更轻松的使用 Dify 构建 AI 应用,那么本文或许会对你有所帮助。
写在前面
最近这阵比较忙,线下见了非常多不同地区的朋友,围绕 Dify 和开源社区做了不少应用和实践分享。

不论是 Dify 生态还是其他的软件生态,越来越多的朋友开始使用 Ollama 来了解模型。不过更多时候,我们见到的是“下载预制菜”使用的玩法,如果我们本地有微调好的模型,又该如何运行呢?
以及,在最近 Llama.cpp 的一次版本发布中,支持了 Llama 3.1 的“rope scaling factors”特性后,新换后的通用模型,其实并不能够被 Ollama 直接启动运行,那么又该怎么处理呢?
为了解决上面两个问题,以及最近忙于线下分享,没有写博客的问题,这篇文章就来聊聊,如何使用 Ollama 来完成“个性化的”模型服务搭建,适合微调后的模型的推理使用呢?
本文当然包含了上面这些问题的答案。
让我们开始实战。
准备工作
默认情况下,我们的准备工作只有两项,准备模型文件和准备 Ollama 运行程序。
本文中,我们以 Llama 最新发布的 3.1 版本原始模型为例,你可以参考这个方式,来转换你的本地微调好的模型,或者其他,Ollama 官方不支持的模型。
下载模型
先来聊聊下载模型。
下载模型可以参考《节省时间:AI 模型靠谱下载方案汇总》中提到的方法。
如果你的服务器或本地服务在国内,可以使用 ModelScope,社区已经有同学将 HuggingFace 上的 Llama 3.1 搬运到了模型库中:8B、70B。
为了不影响我们的服务器或本地的环境,可以创建一个独立的容器镜像环境,来完成模型下载任务。
执行下面的命令,能够创建一个持续运行的容器镜像:
docker run -d --name=downloader -v `pwd`:/models python:3.10-slim tail -f /etc/hosts
使用下面的命令,进入容器的命令行环境:
docker exec -it downloader bash
接着,进行一些简单的软件源加速配置:
sed -i 's/snapshot.debian.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list.d/debian.sources
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
cd /models
pip install modelscope
最后,执行下面的命令,开始具体模型的下载。
python -c "from modelscope import snapshot_download;snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='./models/')"
以 8B 版本的模型为例,完整仓库尺寸在 30GB,如果你是千兆宽带,满速下载时间大概只需要几分钟。
下载后的目录内容、主要模型的校验结果、目录尺寸如下:
# ls
config.json LICENSE model-00003-of-00004.safetensors original tokenizer_config.json
configuration.json model-00001-of-00004.safetensors model-00004-of-00004.safetensors README.md tokenizer.json
generation_config.json model-00002-of-00004.safetensors model.safetensors.index.json special_tokens_map.json USE_POLICY.md
# ls *.safetensors | xargs -I {} shasum {}
b8006f35b7d4a8a51a1bdf9d855eff6c8ee669fb model-00001-of-00004.safetensors
38a23f109de9fcdfb27120ab10c18afc3dac54b8 model-00002-of-00004.safetensors
5ebfe3caea22c3a16dc92d5e8be88605039fd733 model-00003-of-00004.safetensors
57d3f7ef9a903a0e4d119c69982cfc3e7c5b23e8 model-00004-of-00004.safetensors
# du -hs .
30G
下载 Ollama 的 Docker 镜像
我们可以在 Ollama 的 Docker 页面中找到所有可以下载的版本。
官方出于项目的可维护性(省的写如何升级),建议我们直接使用下面的命令来下载 ollama 的 Docker 镜像。
# 使用 CPU 或者 Nvidia GPU 来推理模型
docker pull ollama/ollama
# 使用 AMD GPU 来推理模型
docker pull ollama/ollama:rocm
不过,我个人还是建议,我们始终使用具体的版本的镜像,来确保我们的运行环境是明确的,运行环境可维护性,使用类似下面的方式下载镜像。
# CPU 或 Nvidia GPU 运行
docker pull ollama/ollama:0.3.0
# AMD 显卡运行
docker pull ollama/ollama:0.3.0-rocm
针对不同的设备,我们的运行指令也需要有不同的调整:
# 默认 CPU 模式运行
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# Nvidia GPU 模式运行
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# AMD 显卡运行
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
使用 llama.cpp 转换模型程序
Ollama 的模型仓库默认提供了几十种可以直接运行的模型,我们可以通过类似下面的命令快速获取预制菜。
ollama run llama3
不过,出于授人以渔的目的,以及在许多场景下,我们终究要运行自己 finetune 微调后的模型,这里我们选择使用 Llama.cpp 来量化自己的模型为 Ollama 可以运行的格式。
在《零一万物模型折腾笔记:官方 Yi-34B 模型基础使用》文章中的“尝试对模型进行几种不同的量化操作”、《本地运行“李开复”的零一万物 34B 大模型》中的“编译使用 GPU 的 llama.cpp”、《CPU 混合推理,非常见大模型量化方案:“二三五六” 位量化》三篇文章中,我分别提到过 Llama.cpp 的 CPU 程序编译、GPU 程序编译、通用模型格式的量化操作。如果你感兴趣,可以自行翻阅。
构建新版本的 llama.cpp
简单来说,我们可以通过下面的方式,来手动构建适合自己设备的 llama.cpp 程序:
# 下载代码
git clone https://github.com/ggerganov/llama.cpp.git --depth=1
# 切换工作目录
cd llama.cpp
# 常规模式构建 llama.cpp
cmake -B build
cmake --build build --config Release
# 如果你是 macOS,希望使用 Apple Metal
GGML_NO_METAL=1 cmake --build build --config Release
# 如果你使用 Nvidia GPU
apt install nvidia-cuda-toolkit -y
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
当我们构建完毕 llama.cpp 后,我们就能够对转换后的模型进行运行验证了。
通过 llama.cpp 转换模型格式
为了能够转换模型,我们还需要安装一个简单的依赖:
pip install sentencepiece
接下来,就可以使用官方的新的转换脚本,来完成模型从 Huggingface Safetensors 格式到通用模型格式 GGML 的转换啦。
# ./convert_hf_to_gguf.py ../LLM-Research/Meta-Llama-3___1-8B-Instruct
INFO:hf-to-gguf:Loading model: Meta-Llama-3___1-8B-Instruct
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model weight map from 'model.safetensors.index.json'
INFO:hf-to-gguf:gguf: loading model part 'model-00001-of-00004.safetensors'
INFO:hf-to-gguf:token_embd.weight, torch.bfloat16 --> F16, shape = {4096, 128256}
INFO:hf-to-gguf:blk.0.attn_norm.weight, torch.bfloat16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.0.ffn_down.weight, torch.bfloat16 --> F16, shape = {14336, 4096}
INFO:hf-to-gguf:blk.0.ffn_gate.weight, torch.bfloat16 --> F16, shape = {4096, 14336}
INFO:hf-to-gguf:blk.0.ffn_up.weight, torch.bfloat16 --> F16, shape = {4096, 14336}
...
INFO:hf-to-gguf:Set model quantization version
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf: n_tensors = 292, total_size = 16.1G
Writing: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 16.1G/16.1G [00:24<00:00, 664Mbyte/s]
INFO:hf-to-gguf:Model successfully exported to ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf
验证转换后模型
转换完的模型,我们可以使用下面的命令,来查看基本状况:
# ./build/bin/llama-lookup-stats -m ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf
llama_model_loader: loaded meta data with 29 key-value pairs and 292 tensors from ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Meta Llama 3___1 8B Instruct
llama_model_loader: - kv 3: general.finetune str = 3___1-Instruct
llama_model_loader: - kv 4: general.basename str = Meta-Llama
llama_model_loader: - kv 5: general.size_label str = 8B
llama_model_loader: - kv 6: general.license str = llama3.1
llama_model_loader: - kv 7: general.tags arr[str,6] = ["facebook", "meta", "pytorch", "llam...
llama_model_loader: - kv 8: general.languages arr[str,8] = ["en", "de", "fr", "it", "pt", "hi", ...
llama_model_loader: - kv 9: llama.block_count u32 = 32
llama_model_loader: - kv 10: llama.context_length u32 = 131072
llama_model_loader: - kv 11: llama.embedding_length u32 = 4096
llama_model_loader: - kv 12: llama.feed_forward_length u32 = 14336
llama_model_loader: - kv 13: llama.attention.head_count u32 = 32
llama_model_loader: - kv 14: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 15: llama.rope.freq_base f32 = 500000.000000
llama_model_loader: - kv 16: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 17: general.file_type u32 = 1
llama_model_loader: - kv 18: llama.vocab_size u32 = 128256
llama_model_loader: - kv 19: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 20: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 21: tokenizer.ggml.pre str = llama-bpe
llama_model_loader: - kv 22: tokenizer.ggml.tokens arr[str,128256] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 23: tokenizer.ggml.token_type arr[i32,128256] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 24: tokenizer.ggml.merges arr[str,280147] = ["Ġ Ġ", "Ġ ĠĠĠ", "ĠĠ ĠĠ", "...
llama_model_loader: - kv 25: tokenizer.ggml.bos_token_id u32 = 128000
llama_model_loader: - kv 26: tokenizer.ggml.eos_token_id u32 = 128009
llama_model_loader: - kv 27: tokenizer.chat_template str = {% set loop_messages = messages %}{% ...
llama_model_loader: - kv 28: general.quantization_version u32 = 2
llama_model_loader: - type f32: 66 tensors
llama_model_loader: - type f16: 226 tensors
llm_load_vocab: special tokens cache size = 256
llm_load_vocab: token to piece cache size = 0.7999 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 128256
llm_load_print_meta: n_merges = 280147
llm_load_print_meta: vocab_only = 0
llm_load_print_meta: n_ctx_train = 131072
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_swa = 0
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 4
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 14336
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 500000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 131072
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 8B
llm_load_print_meta: model ftype = F16
llm_load_print_meta: model params = 8.03 B
llm_load_print_meta: model size = 14.96 GiB (16.00 BPW)
llm_load_print_meta: general.name = Meta Llama 3___1 8B Instruct
llm_load_print_meta: BOS token = 128000 '<|begin_of_text|>'
llm_load_print_meta: EOS token = 128009 '<|eot_id|>'
llm_load_print_meta: LF token = 128 'Ä'
llm_load_print_meta: EOT token = 128009 '<|eot_id|>'
llm_load_print_meta: max token length = 256
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
llm_load_tensors: ggml ctx size = 0.14 MiB
llm_load_tensors: offloading 0 repeating layers to GPU
llm_load_tensors: offloaded 0/33 layers to GPU
llm_load_tensors: CPU buffer size = 15317.02 MiB
.........................................................................................
llama_new_context_with_model: n_ctx = 131072
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 500000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CUDA_Host KV buffer size = 16384.00 MiB
llama_new_context_with_model: KV self size = 16384.00 MiB, K (f16): 8192.00 MiB, V (f16): 8192.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 8984.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 264.01 MiB
llama_new_context_with_model: graph nodes = 1030
llama_new_context_with_model: graph splits = 420
n_draft = 5
n_predict = 0
n_drafted = 0
t_draft_flat = 0.00 ms
t_draft = 0.00 ms, -nan us per token, -nan tokens per second
n_accept = 0
accept = -nan%
当然,也可以“跑个分”:
# ./build/bin/llama-bench -m ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
| model | size | params | backend | ngl | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------------: | ---------------: |
| llama 8B F16 | 14.96 GiB | 8.03 B | CUDA | 99 | pp512 | 10909.62 ± 38.48 |
| llama 8B F16 | 14.96 GiB | 8.03 B | CUDA | 99 | tg128 | 56.51 ± 0.04 |
或者使用 simple 程序,来完成上面两个命令的“打包操作”:
# ./build/bin/llama-simple -m ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf
...
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
llm_load_tensors: ggml ctx size = 0.14 MiB
llm_load_tensors: offloading 0 repeating layers to GPU
llm_load_tensors: offloaded 0/33 layers to GPU
llm_load_tensors: CPU buffer size = 15317.02 MiB
.........................................................................................
llama_new_context_with_model: n_ctx = 131072
llama_new_context_with_model: n_batch = 2048
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 500000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CUDA_Host KV buffer size = 16384.00 MiB
llama_new_context_with_model: KV self size = 16384.00 MiB, K (f16): 8192.00 MiB, V (f16): 8192.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: CUDA0 compute buffer size = 8984.00 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 264.01 MiB
llama_new_context_with_model: graph nodes = 1030
llama_new_context_with_model: graph splits = 420
main: n_predict = 32, n_ctx = 131072, n_kv_req = 32
<|begin_of_text|>Hello my name is Emily and I am a 25 year old artist living in the beautiful city of Portland, Oregon. I am a painter and a print
main: decoded 27 tokens in 7.64 s, speed: 3.54 t/s
llama_print_timings: load time = 5626.11 ms
llama_print_timings: sample time = 5.47 ms / 28 runs ( 0.20 ms per token, 5122.58 tokens per second)
llama_print_timings: prompt eval time = 506.98 ms / 5 tokens ( 101.40 ms per token, 9.86 tokens per second)
llama_print_timings: eval time = 7598.61 ms / 27 runs ( 281.43 ms per token, 3.55 tokens per second)
llama_print_timings: total time = 13260.46 ms / 32 tokens
验证完转换的模型是正确,并且能够运行的之后,这里我们可以选择根据自己的硬件情况,进行一些量化操作,来降低模型运行对硬件的需求。
对转换后的通用模型进行量化
默认情况下,llama.cpp 支持以下的量化方式:
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
33 or Q4_0_4_4 : 4.34G, +0.4685 ppl @ Llama-3-8B
34 or Q4_0_4_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
35 or Q4_0_8_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing
我个人通常会选择 Q4_K_M 一类的量化类型,保持小巧,又不会太掉性能,你可以根据自己的习惯来进行量化:
# ./build/bin/llama-quantize ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf Q4_K_M
main: build = 1 (4730fac)
main: built with cc (Ubuntu 13.2.0-23ubuntu4) 13.2.0 for x86_64-linux-gnu
main: quantizing '../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf' to '../LLM-Research/Meta-Llama-3___1-8B-Instruct/ggml-model-Q4_K_M.gguf' as Q4_K_M
llama_model_loader: loaded meta data with 29 key-value pairs and 292 tensors from ../LLM-Research/Meta-Llama-3___1-8B-Instruct/Meta-Llama-8B-3___1-Instruct-F16.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
...
[ 290/ 292] blk.31.ffn_down.weight - [14336, 4096, 1, 1], type = f16, converting to q6_K .. size = 112.00 MiB -> 45.94 MiB
[ 291/ 292] blk.31.ffn_norm.weight - [ 4096, 1, 1, 1], type = f32, size = 0.016 MB
[ 292/ 292] output_norm.weight - [ 4096, 1, 1, 1], type = f32, size = 0.016 MB
llama_model_quantize_internal: model size = 15317.02 MB
llama_model_quantize_internal: quant size = 4685.30 MB
main: quantize time = 22881.80 ms
main: total time = 22881.80 ms
我们可以使用上文中的方式,对量化后的模型再次进行验证:
# ./build/bin/llama-simple -m ../LLM-Research/Meta-Llama-3___1-8B-Instruct/ggml-model-Q4_K_M.gguf
main: decoded 27 tokens in 2.47 s, speed: 10.93 t/s
llama_print_timings: load time = 5247.69 ms
llama_print_timings: sample time = 4.08 ms / 28 runs ( 0.15 ms per token, 6857.70 tokens per second)
llama_print_timings: prompt eval time = 179.68 ms / 5 tokens ( 35.94 ms per token, 27.83 tokens per second)
llama_print_timings: eval time = 2445.16 ms / 27 runs ( 90.56 ms per token, 11.04 tokens per second)
llama_print_timings: total time = 7718.22 ms / 32 tokens
可以看到,默认情况下,使用 CPU 进行推理的速度就提升了 3 倍。
接下来,我们来使用 Docker 和 Ollama 来运行刚刚量化好的模型,完成服务的搭建。
Ollama 服务的启动
当我们搞定 Ollama 可以导入的模型文件之后,就可以开始折腾 Ollama 啦。
完成 Ollama 模型的构建
我们可以创建一个干净的目录,将刚刚在其他目录中量化好的模型放进来,创建一个 ollama 模型配置文件,方便后续的操作:
# 创建一个新的工作目录
mkdir ollama
# 切换工作目录
cd ollama
# 将量化好的模型放到目录中
cp ../llama3/LLM-Research/Meta-Llama-3___1-8B-Instruct/ggml-model-Q4_K_M.gguf .
# 创建一个 ollama 模型配置文件
echo "FROM ./ggml-model-Q4_K_M.gguf" > Modelfile
然后,使用上文中提到的命令,将服务运行起来:
docker run -d --gpus=all -v `pwd`:/root/.ollama -p 11434:11434 --name ollama-llama3 ollama/ollama:0.3.0
接着,使用下面的命令,进入 ollama 容器交互命令行环境:
docker exec -it ollama-llama3 bash
执行下面的命令,完成 ollama 模型的导入:
ollama create custom_llama_3_1 -f ~/.ollama/Modelfile
正常情况下,我们将看到类似下面的日志输出:
transferring model data
using existing layer sha256:c6f9cdd9aca1c9bc25d63c4175261ca16cc9d8c283d0e696ad9eefe56cf8400f
using autodetected template llama3-instruct
creating new layer sha256:0c41faf4e1ecc31144e8f17ec43fb74f81318a2672ee88088e07c09a680f2212
writing manifest
success
导入模型后,我们可以通过 show 命令,来查看模型的基础状况:
# ollama show custom_llama_3_1
Model
arch llama
parameters 8.0B
quantization Q4_K_M
context length 131072
embedding length 4096
转换完毕的模型,会保存在 ~/.ollama/models 目录中。
du -hs ~/.ollama/models/
4.6G /root/.ollama/models/
因为我们刚刚在启动服务的时候,已经在模型目录映射到了本地,所以接下来,我们只需要重新创建一个容器,携带合适的命令,就能够完成服务的搭建了,而无需再次构建 ollama 镜像。
启动 Ollama 模型服务
通常情况下,如果已经完成了模型的转换,我们可以结合上文中的命令进行调整,在命令后添加要执行的模型,来完成服务的启动:
docker run -d --gpus=all -v `pwd`:/root/.ollama -p 11434:11434 --name ollama-llama3 ollama/ollama:0.3.0
不过,最近 llama.cpp 有更新,更新后的模型 ollama 是无法启动的,我们需要从源码重新构建 Ollama 镜像。
当然,为了更简单的解决问题,我已经将构建好的镜像上传到了 DockerHub,我们可以使用下面的命令,来下载这个 CPU 和 N 卡通用的镜像(AMD Rocm镜像比较大,如果有需要,我再上传吧)。
docker pull soulteary/ollama:0.3.0-fix
然后,将命令替换为:
docker run -d --gpus=all -v `pwd`:/root/.ollama -p 11434:11434 --name ollama-llama3 soulteary/ollama:0.3.0-fix
接下来,我们就可以通过 API 来调用 Ollama 服务,运行我们的自定义模型啦(custom_llama_3_1)。
curl http://localhost:11434/api/generate -d '{
"model": "custom_llama_3_1",
"prompt":"Why is the sky blue?"
}'
调用后的输出结果类似下面这样:
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:05.390939108Z","response":"The","done":false}
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:05.390944605Z","response":" sky","done":false}
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:05.391066439Z","response":" appears","done":false}
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:05.391068088Z","response":" blue","done":false}
...
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:08.259730694Z","response":" atmosphere","done":false}
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:08.268042795Z","response":".","done":false}
{"model":"custom_llama_3_1","created_at":"2024-07-28T12:59:08.276441118Z","response":"","done":true,"done_reason":"stop","context":[128006,882,128007,271,10445,374,279,13180,6437,30,128009,128006,78191,128007,271,791,13180,8111,6437,311,603,1606,315,264,25885,2663,72916,11,902,13980,994,40120,84261,449,279,13987,35715,315,45612,304,279,9420,596,16975,13,5810,596,264,44899,16540,1473,16,13,3146,31192,4238,29933,9420,596,16975,96618,3277,40120,29933,1057,16975,11,433,17610,315,682,279,8146,315,279,9621,20326,11,2737,2579,11,19087,11,14071,11,6307,11,6437,11,1280,7992,11,323,80836,627,17,13,3146,3407,31436,13980,96618,578,24210,320,12481,8,93959,527,38067,304,682,18445,555,279,13987,35715,315,45612,1778,439,47503,320,45,17,8,323,24463,320,46,17,570,1115,374,3967,439,13558,64069,72916,11,7086,1306,279,8013,83323,10425,13558,64069,11,889,1176,7633,279,25885,304,279,3389,220,777,339,9478,627,18,13,3146,6720,261,93959,1522,1555,96618,578,5129,93959,11,1093,2579,323,19087,11,527,539,38067,439,1790,323,3136,311,5944,304,264,7833,1584,11,19261,1057,6548,505,810,2167,13006,627,19,13,3146,8140,6548,45493,279,1933,96618,3277,584,1427,520,279,13180,11,1057,6548,5371,279,38067,6437,3177,505,682,18445,11,902,374,3249,433,8111,6437,382,8538,5217,9547,430,10383,279,10186,1933,315,279,13180,2997,1473,9,3146,1688,8801,33349,4787,96618,578,3392,315,16174,11,83661,11,323,3090,38752,304,279,16975,649,7958,1268,1790,40120,374,38067,627,9,3146,1489,315,1938,323,1060,96618,578,2361,315,279,7160,323,279,9392,315,40120,16661,279,16975,649,1101,5536,279,26617,1933,315,279,13180,627,9,3146,16440,82,323,25793,96618,15161,82,323,83661,304,279,3805,649,45577,3177,304,2204,5627,11,7170,3339,279,13180,5101,810,305,13933,477,18004,382,4516,11,311,63179,25,279,13180,8111,6437,1606,315,279,72916,315,24210,320,12481,8,93959,315,40120,555,13987,35715,304,279,9420,596,16975,13],"total_duration":4835140836,"load_duration":1865770271,"prompt_eval_count":16,"prompt_eval_duration":12268000,"eval_count":356,"eval_duration":2913570000}
当然,为了更直观,我们可以使用 Dify 来调用 Ollama 的 API,构建 AI 应用。这个内容,我们在本文的下一小节展开。
从源码构建 Ollama 程序镜像
想要从源码构建 Ollama 并不复杂,但是我们需要做一些准备工作。
# 下载仓库代码
git clone https://github.com/ollama/ollama.git ollama-src
# 切换代码目录
cd ollama-src
# 进入核心组件目录
cd llm
# 更新组件代码
git submodule update --init --recursive
# 更新 llama.cpp 主分支相关代码
cd llama.cpp
git checkout master
git pull
完成代码的获取后,我们可以根据需要进行容器的构建:
# 回到代码根目录
cd ../../
# 构建修补后或调整后的程序镜像
bash scripts/build_docker.sh
# 你也可以在命令前添加你希望构建的架构,减少构建时间
BUILD_ARCH=amd64 bash scripts/build_docker.sh
作者并没有针对 Docker 构建做优化,所以构建时间会相对的长一些:
BUILD_ARCH=amd64 bash scripts/build_docker.sh
[+] Building 27.4s (48/48) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 6.25kB 0.0s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 107B 0.0s
=> [internal] load metadata for docker.io/nvidia/cuda:11.3.1-devel-centos7 1.7s
=> [internal] load metadata for docker.io/library/ubuntu:22.04 0.0s
=> [internal] load metadata for docker.io/rocm/dev-centos-7:6.1.2-complete 1.7s
=> [internal] load metadata for docker.io/library/centos:7 1.7s
=> [auth] nvidia/cuda:pull token for registry-1.docker.io 0.0s
=> [auth] rocm/dev-centos-7:pull token for registry-1.docker.io 0.0s
=> [auth] library/centos:pull token for registry-1.docker.io 0.0s
=> [runtime-amd64 1/3] FROM docker.io/library/ubuntu:22.04
...
=> [runtime-rocm 3/3] COPY --from=build-amd64 /go/src/github.com/ollama/ollama/ollama /bin/ollama 0.4s
=> exporting to image 1.9s
=> => exporting layers 1.9s
=> => writing image sha256:c8f45a6cf0e212476d61757e5ef1e9d279be45369f87c5f0e362d42f4f41713f 0.0s
=> => naming to docker.io/ollama/release:0.3.0-12-gf3d7a48-dirty-rocm 0.0s
Skipping manifest generation when not pushing images are available locally as
ollama/release:0.3.0-12-gf3d7a48-dirty-amd64
ollama/release:0.3.0-12-gf3d7a48-dirty-arm64
ollama/release:0.3.0-12-gf3d7a48-dirty-rocm
完成构建后,我们将得到上面输出的几个拥有很长名称的 Docker 镜像,为了更好的维护和使用,我们可以给镜像起个合适的名字:
docker tag ollama/release:0.3.0-12-gf3d7a48-dirty-amd64 soulteary/ollama:0.3.0-fix
这个镜像,我已经上传到了 DockerHub,有需要的同学可以直接下载使用:
docker pull soulteary/ollama:0.3.0-fix
Ollama 在 Dify 中的使用
关于 Dify 的实战内容,我之前已经写过了一些,如果你感兴趣,可以阅读这里,了解各种有趣的使用方法。之前提到的一些内容,我就不再展开。
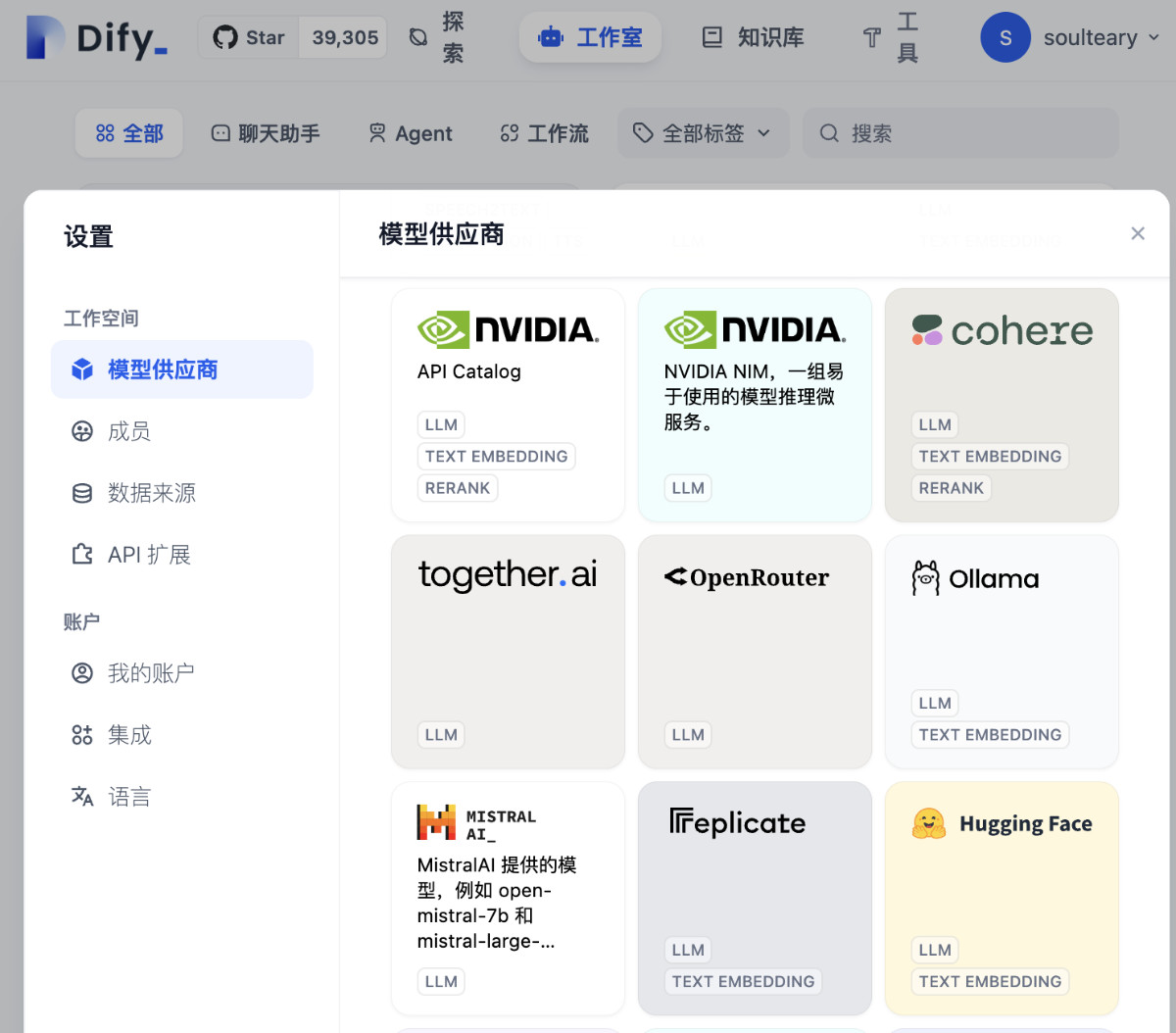
想要在 Dify 中愉快的使用 Ollama 的 API,我们需要先打开“设置”中的“添加模型”界面,选择 Ollama。
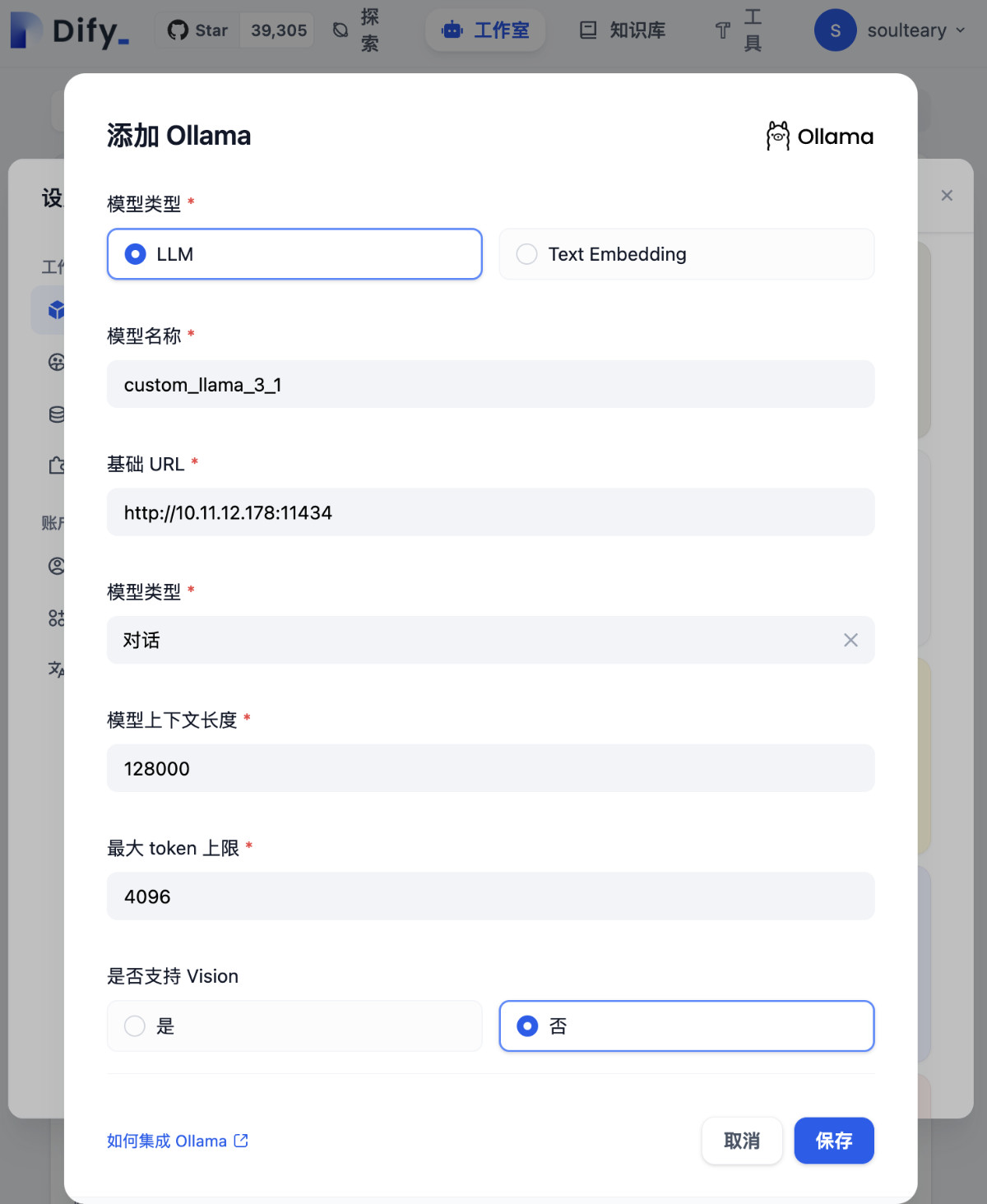
参考上文中的信息,我们完成包括模型名称、模型配置参数的填写,点击“保存”,完成新模型的添加。
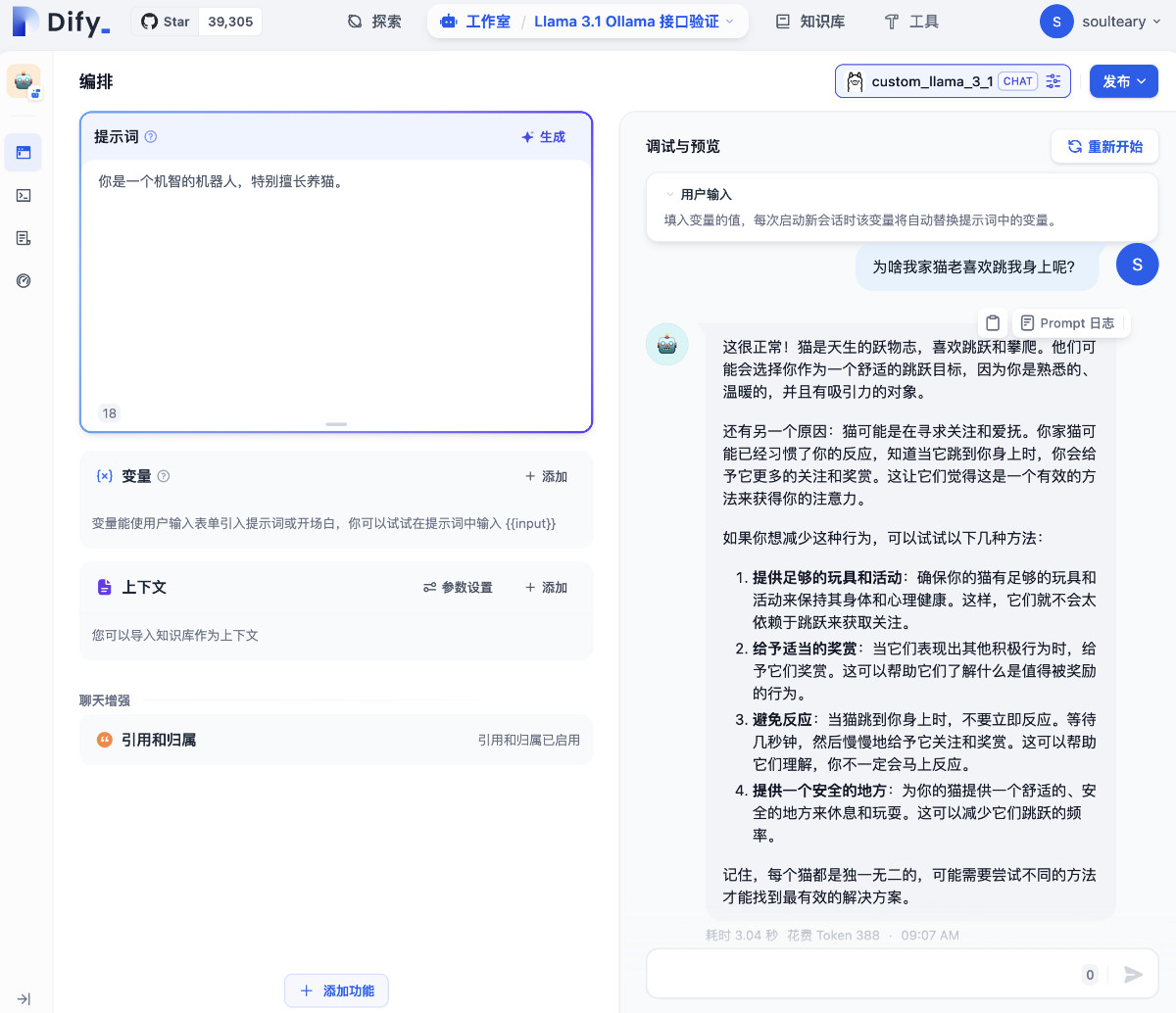
返回 Dify 的主界面,创建一个新的 AI 应用,随便起个名字,我这里使用的是“Llama 3.1 Ollama 接口验证”。
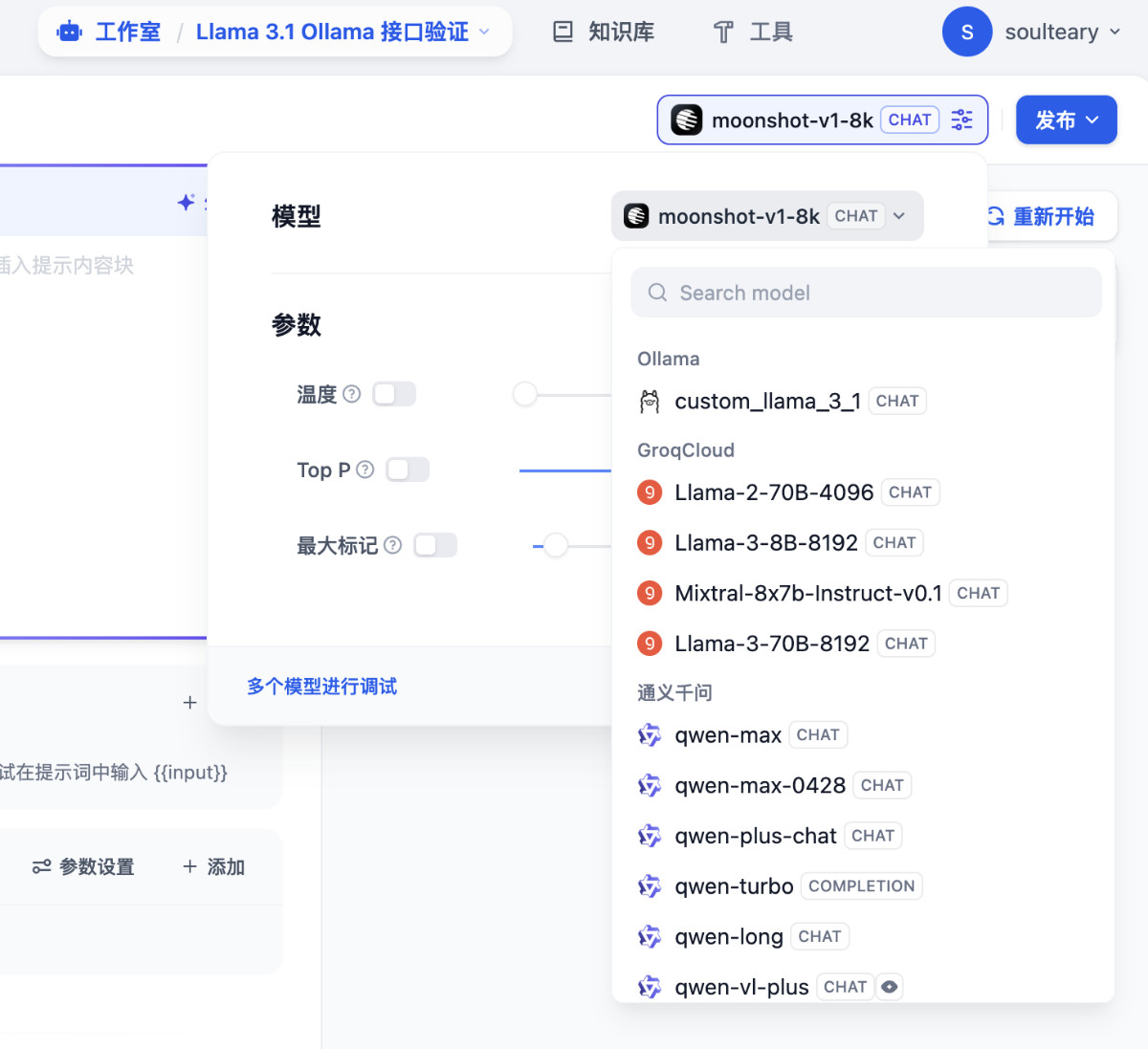
在新建的 AI 应用界面,选择刚刚添加的 Ollama 模型。
接下来,就是愉快的 Dify 时间,根据你的需要来和 Ollama 模型进行交互啦。如果你对具体的应用玩法感兴趣,可以参考我之前写过的 Dify 相关的实战内容。
最后
接下来的相关内容,让我们继续聊聊今年下半年“大模型”新赛季版本的一些有趣玩法升级吧。
下一篇文章见。
–EOF