本篇文章,我们聊聊如何在 Windows 环境下使用 Docker 作为深度学习环境,以及快速运行 SDXL 1.0 正式版,可能是目前网上比较简单的 Docker、WSL2 配置教程啦。
写在前面
早些时候,写过一篇《基于 Docker 的深度学习环境:入门篇》,聊过了在 Linux 环境下,如何简单、正确的配置 GPU Docker 环境。
这几周总有不少好玩的开源模型和相关的应用组团出现,最近几篇文章发布后(尤其是 LLaMA2),总有 Windows 玩家因为环境原因提问。我觉得或许需要写一篇 Windows 下的 Docker 深度学习环境的配置教程,作为查缺补漏参考之用,应该能够减少不少因为环境所带来的问题。
我使用的操作系统版本为 Windows 11 家庭版,如果你使用的操作系统版本低于 Windows 11,可以考虑适当调整命令。
准备 Docker 虚拟化运行环境
想要完成 Docker 虚拟化环境的准备,一共分为三步:安装 Docker、配置 WSL2,开始玩。
安装 Docker 应用程序
我们可以从 Docker 官方网站,获取到 Docker 应用程序安装包的下载。

下载完毕之后,“一路 Next” 完成安装后,点击安装程序的“重启按钮”等待程序安装完毕。
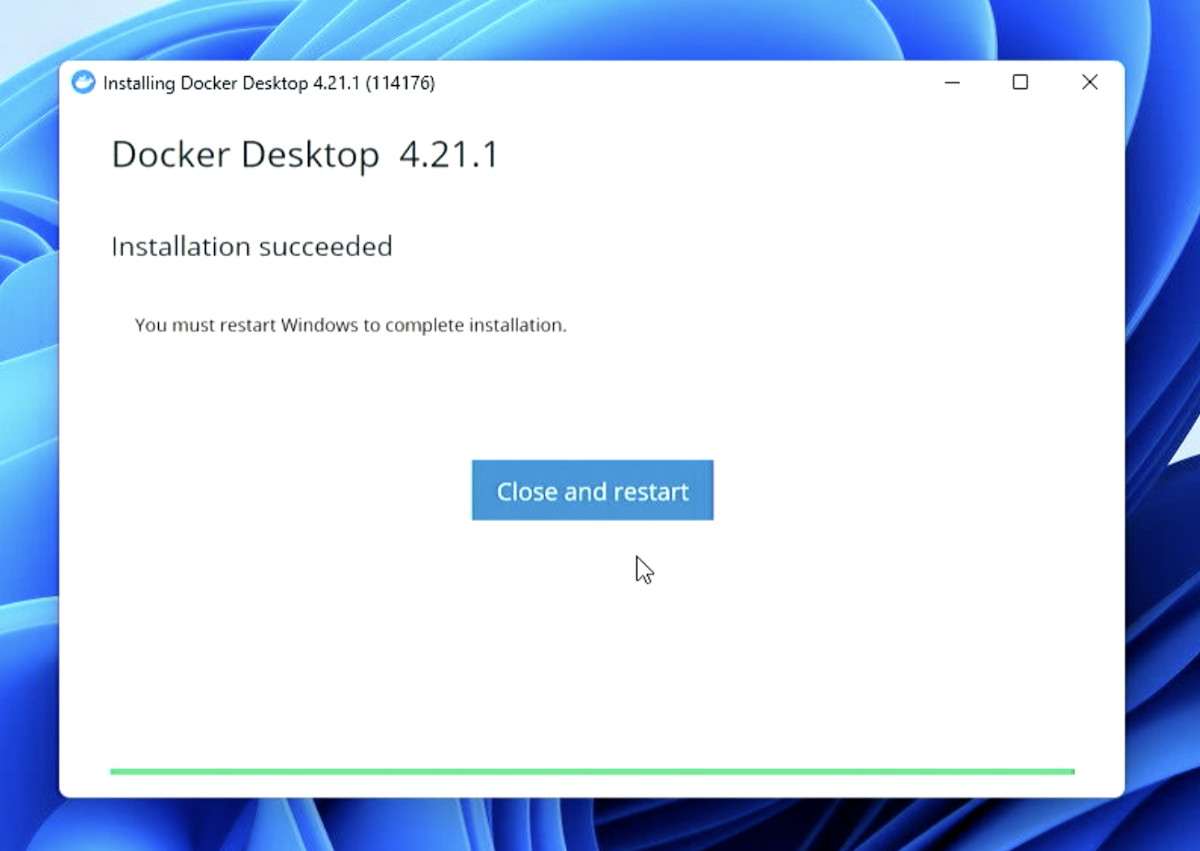
等待电脑重启完毕,我们启动 Docker ,可能会遇到报错提示,提醒我们需要 “WSL” 新版本。(如果已经是 WSL2 环境,则可以跳过下面的小节,如果不确定,可以跟着走一遍)
接下来,我们来准备 WSL2 的运行环境。
准备 WSL2 的运行环境
网上的安装教程绝大多数都是陈旧的资料,都比较繁琐,其实配置 WSL2 的环境非常简单。
右键任务栏上的“Windows”徽标,选择“终端管理员”,打开 Powershell 终端界面,执行下面的命令。
wsl --install
命令执行后,可能会得到执行命令超时的提醒。没有关系,再次执行命令即可,等到能够看到终端展示支持的 Linux 操作系统的列表,表示 WSL 初始化正常,网络访问正常:
# wsl --install
适用于 Linux 的 Windows 子系统已安装。
操作超时
如果遇到超时,没关系的,再试试就好:
# wsl --install
适用于 Linux 的 Windows 子系统已安装。
以下是可安装的有效分发的列表。
请使用“wsl --install -d <分发>”安装。
NAME FRIENDLY NAME
Ubuntu Ubuntu
Debian Debian GNU/Linux
kali-linux Kali Linux Rolling
Ubuntu-18.04 Ubuntu 18.04 LTS
Ubuntu-20.04 Ubuntu 20.04 LTS
Ubuntu-22.04 Ubuntu 22.04 LTS
OracleLinux_7_9 Oracle Linux 7.9
OracleLinux_8_7 Oracle Linux 8.7
OracleLinux_9_1 Oracle Linux 9.1
openSUSE-Leap-15.5 openSUSE Leap 15.5
SUSE-Linux-Enterprise-Server-15-SP4 SUSE Linux Enterprise Server 15 SP4
SUSE-Linux-Enterprise-15-SP5 SUSE Linux Enterprise 15 SP5
openSUSE-Tumbleweed openSUSE Tumbleweed
当你看到上面的命令后,我们就可以执行第二条命令 wsl --update 来完成 wsl 主体程序的更新啦:
# wsl --update
正在安装: 适用于 Linux 的 Windows 子系统
已安装 适用于 Linux 的 Windows 子系统。
命令执行完毕后,我们能够看到类似上面的提醒。查看程序版本和内核,能够看到类似下面的信息:
# wsl --version
WSL 版本: 1.2.5.0
内核版本: 5.15.90.1
WSLg 版本: 1.0.51
MSRDC 版本: 1.2.3770
Direct3D 版本: 1.608.2-61064218
DXCore 版本: 10.0.25131.1002-220531-1700.rs-onecore-base2-hyp
Windows 版本: 10.0.22621.1778
接着,为了让 Docker 跑的更欢脱,以及能够正常调用 GPU,我们需要切换 WSL 默认版本为 WSL2:
# wsl --set-default-version 2
有关与 WSL 2 关键区别的信息,请访问 https://aka.ms/wsl2
操作成功完成。
上面的操作都完成后,我们再次打开 Docker,就能够看到正常运行的界面啦。
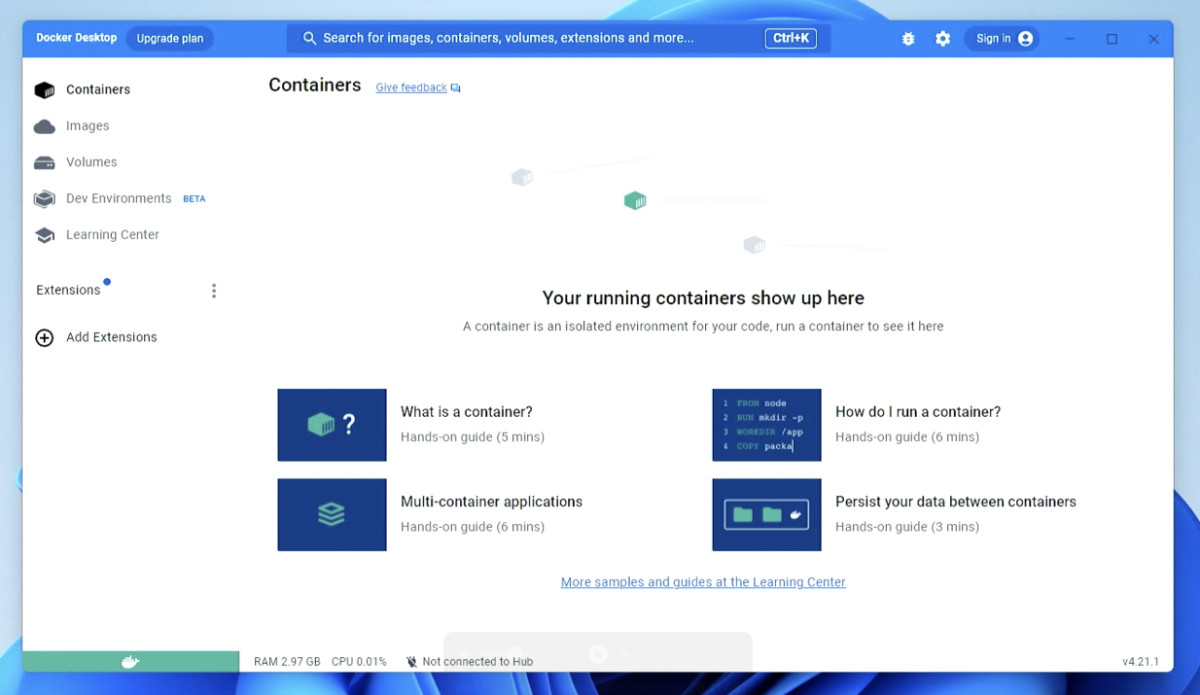
在使用 Docker 调用容器镜像前,我们还需要验证下 Docker 是否能够和 GPU 正常通信。
验证 Docker 中 GPU 是否能够被正常调用
和上篇文章一样,可以先下载一个 Nvidia 官方的 PyTorch 镜像:
docker pull nvcr.io/nvidia/pytorch:23.07-py3
镜像比较大,需要耐心等待几分钟:
# docker pull nvcr.io/nvidia/pytorch:23.07-py3
23.07-py3: Pulling from nvidia/pytorch
...
...
Digest: sha256:c53e8702a4ccb3f55235226dab29ef5d931a2a6d4d003ab47ca2e7e670f7922b
Status: Downloaded newer image for nvcr.io/nvidia/pytorch:23.07-py3
当镜像下载完毕后,我们可以使用命令 docker run -it --gpus=all --rm nvcr.io/nvidia/pytorch:23.07-py3 nvidia-smi 来使用 Docker 启动一个容器,并在容器中调用 nvidia-smi 显卡管理程序,来查看显卡的状况:
# docker run -it --gpus=all --rm nvcr.io/nvidia/pytorch:23.07-py3 nvidia-smi
=============
== PyTorch ==
=============
NVIDIA Release 23.07 (build 63867923)
PyTorch Version 2.1.0a0+b5021ba
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
NOTE: The SHMEM allocation limit is set to the default of 64MB. This may be
insufficient for PyTorch. NVIDIA recommends the use of the following flags:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 ...
Sat Jul 29 01:44:04 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.37 Driver Version: 531.30 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 On | Off |
| 32% 38C P8 23W / 450W| 571MiB / 24564MiB | 4% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
通过上面的日志,可以看到显卡状态正常,同时能够读取到所有我们需要的信息。
写到这里,Windows 环境下的 Docker 深度学习环境就聊完了,如果你想了解更多,可以翻阅《基于 Docker 的深度学习环境:入门篇》文章中的“AI 相关的 Docker 镜像,及实际使用”和“其他”小节,来进行查缺补漏。
使用 Docker 在容器中调用 GPU
当然,不实实在在来一场实践,不是我的写作风格。
所以,在环境就绪之后,我们来使用 Docker 来尝试运行上一篇文章《使用 Docker 快速上手 Stability AI 的 SDXL 1.0 正式版》中提到的 Stable Diffusion XL 1.0 的镜像,让它能够在 Windows 环境下正常使用。
这里,我们跳过上一篇的准备工作和镜像构建,直接使用现成的运行环境来折腾 SDXL 1.0。当然,如果你感兴趣,可以翻阅上篇文章全文,来了解背后的技术细节,这里就不展开啦。
下载模型文件和容器环境
我们可以从网盘地址1和网盘地址2,分别下载官方的模型文件和整理好的 Docker 容器环境(环境只下载 sdxl-runtime.tar 即可)。
如果下载出现问题,可以前往 soulteary/docker-sdxl 项目 issue 留言反馈或参考上一篇文章,从 HuggingFace 下载模型,和进行容器镜像的手动构建。
加载模型并准备工作目录
以 C 盘为例,我们在盘根创建一个名为 docker-sdxl 的目录,然后将 sdxl-runtime.tar 和下载模型目录中的 stabilityai 放到这个目录中。
然后,切换工作目录到 C:/docker-sdxl:
cd C:/docker-sdxl/
接着,执行命令,载入容器镜像文件 docker load -i .\docker-sdxl\sdxl-runtime.tar:
docker load -i .\docker-sdxl\sdxl-runtime.tar
68ad565f4346: Loading layer [==================================================>] 2.56kB/2.56kB
b279d196469f: Loading layer [==================================================>] 384.6MB/384.6MB
08135af11e7a: Loading layer [==================================================>] 1.536kB/1.536kB
6b36eae25335: Loading layer [==================================================>] 6.144kB/6.144kB
72a8d0a30e5a: Loading layer [==================================================>] 18.94kB/18.94kB
Loaded image: soulteary/sdxl:runtime
镜像加载完毕之后,我们就可以运行 Docker 容器,来玩 SDXL 啦:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v C:/docker-sdxl/stabilityai/:/app/stabilityai -p 7860:7860 soulteary/sdxl:runtime
可以看到,命令和前一篇适用于 Linux 环境的文章几乎一致,除了在 Linux 环境下,我们可以通过 pwd 来表示当前目录,而 Windows 环境中,最佳实践是通过完整目录(C:/docker-sdxl/stabilityai/)来表示。
在命令执行完毕后,我们就进入了交互式的终端,接下来我们可以执行和上一篇文章一样的三个程序:basic.py、refiner.py、refiner-low-vram.py:
# 执行基础模型程序
python basic.py
# 执行全家桶模型程序
python refiner.py
# 执行使用显存稍低的程序
python refiner-low-vram.py
资源要求和消耗和上一篇并没有什么不同,唯一的差别可能是 WSL2 的数据传输性能相比 Linux 环境要低不少,模型加载的时间会长很多,需要耐心等待。
当模型完全加载完毕,我们能够看到下面的日志:
python basic.py
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████| 7/7 [00:03<00:00, 1.95it/s]
Running on local URL: http://0.0.0.0:7860/
To create a public link, set `share=True` in `launch()`.
接下来,访问 http://localhost:7860 或者 http://你的IP:7860 来访问 SDXL 1.0 的 Web 界面啦。
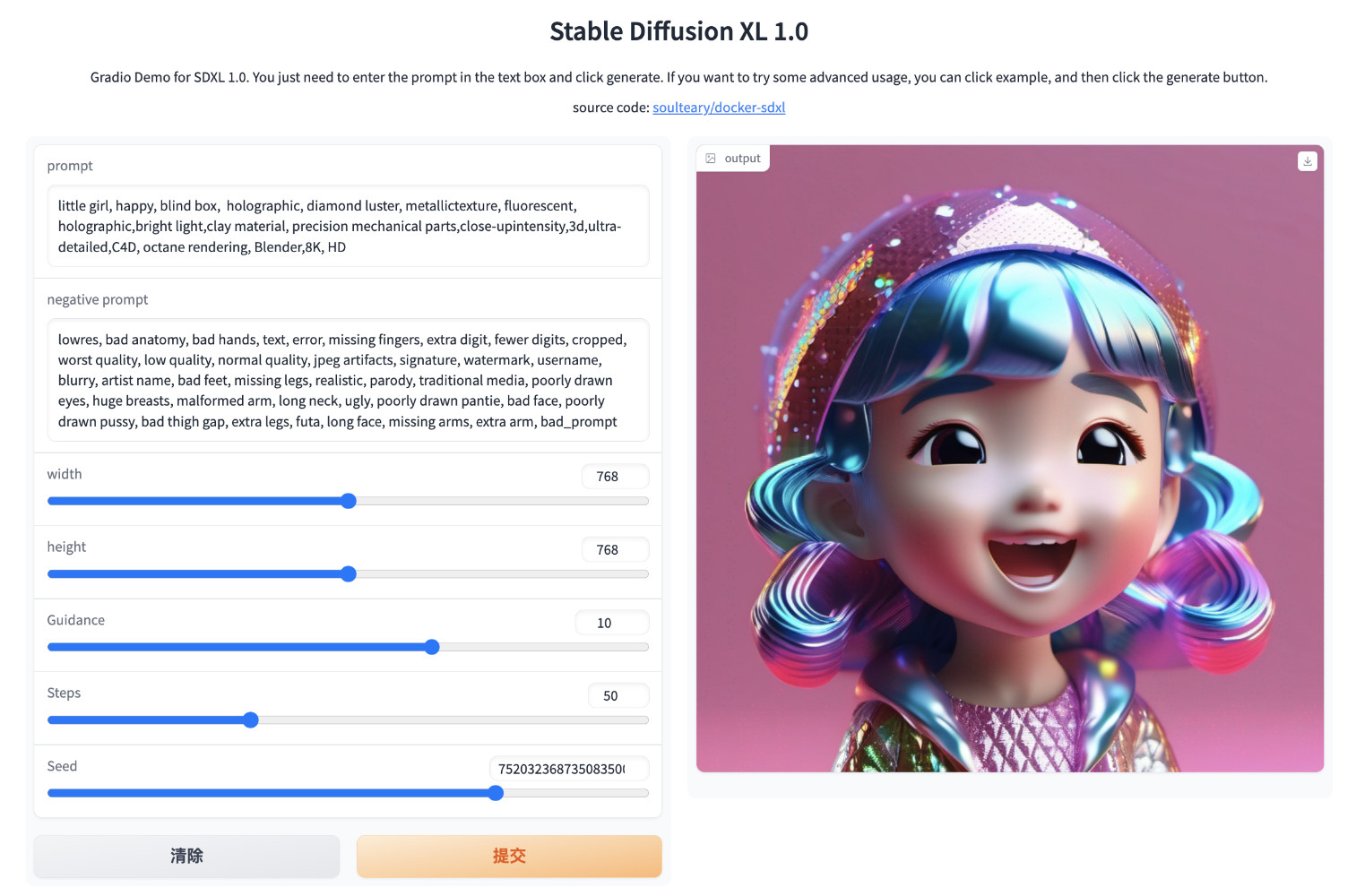
虽然上面日志中加载模型的性能比较差,但实际推理的性能非常好,能够达到 11~13it/s,和 Linux 没有什么差异。(都在显存里了,没有数据交换)
因为 Windows 默认会打开防火墙,限制程序对外暴露端口,避免一些安全问题。在使用的时候,如果你的 Windows 主机和你要访问这个服务的设备是两台设备,你需要关闭或者在防火墙内放行这个应用,有类似情况的小伙伴可以注意下,调整下系统防火墙配置。
其他
我之前已经写过不少 AI 相关的内容,尤其是偏实践类的文章,你可以访问下面几个链接来获取能够快速上手的教程。比如,“Python” 主题的内容、“Llama ” 主题相关的内容、“Stable Diffusion ” 主题相关的内容。
或者,也可以访问我在 GitHub 上公开的项目,获取相关的代码或者 Docker 镜像,自己亲手试验下 “人工智能” 的 iPhone Moment 时代的各种模型。
最后
好了,这篇文章就先写到这里啦,:-D
–EOF