这篇文章,我们继续聊聊,如何折腾 AI 应用,把不 AI 的东西,“AI 起来”。
在不折腾复杂的检索系统的前提下,做一些轻量的 RAG 实践。
写在前面
我从“机器之心会员通讯”上线以来就在订阅,相比较即时的行业资讯报道,这种经过整理的,有一定资料性质的内容,更适合我的胃口。
但是,人工智能领域发展既蓬勃又迅速,机器之心的记者们每篇会员通讯都会写的满满当当,这当然很棒(买家角度超值)。

但是,在我要消化或者查找具体内容的时候,常常会陷入迷茫,这么多字,咋整。仿佛记者和编辑们整理素材时的痛苦,无损转移到了我阅读理解的时候。
我的读者应该都知道在当前 LLM 模型“横行霸道”的时刻,RAG (增强检索)方案可以借助模型的内容理解和语言重生成能力来解决问题。不过,多数的实现方案中,我们需要折腾 embedding model、需要折腾文档内容抽取、需要折腾向量检索召回内容排序,确保我们想要的内容和模型处理的内容是对的上的,完整一套都整下来的话,这不就复杂了嘛。
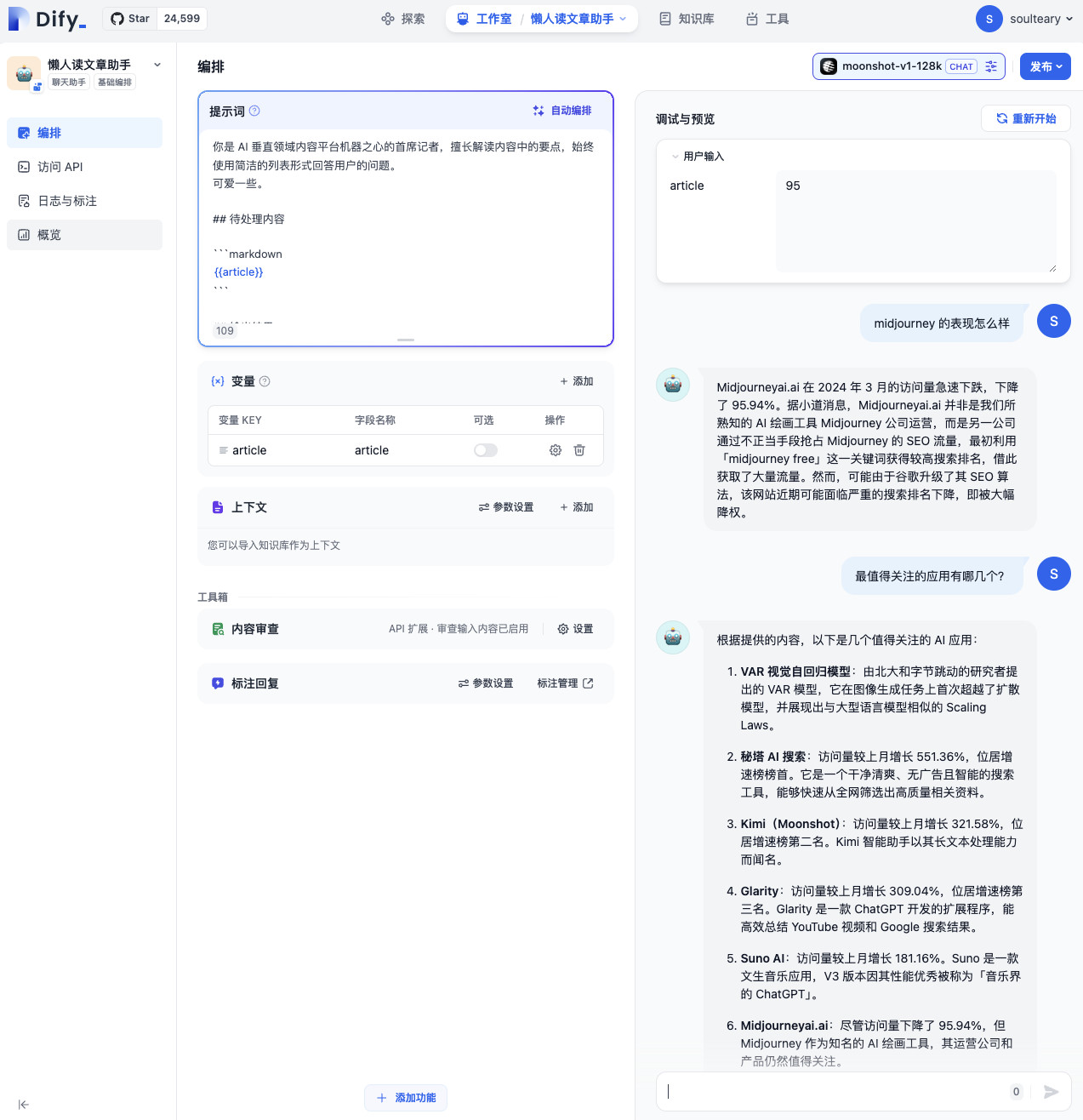
上面是我最终折腾的结果,借助大模型编写了 120 行左右的代码,配合 Dify 默认功能实现的,开箱即用,没有任何复杂的处理过程。
虽然在 Dify 中,它默认支持了知识库功能,主打的就是上面的场景,适配的是大量(十万、百万、千万级别以上)的内容,在这个场景下,折腾上面的套路收益是比较大的。但是,如果我们就只想针对百十来篇,几千篇明确的内容进行解析,其实有更简单的方法。
相关代码开源在 soulteary/dify-simple-rag-with-wp,有需要自取。
准备工作
本篇文章的准备工作和上一篇《使用 Dify 和 Moonshot API 构建你的 AI 工作流(一):让不 AI 的应用 AI 化》没有太大差别,想要顺滑的复现本文的结果,你有个 Docker 环境就好啦。
Docker 运行环境
想顺滑的完成实践,我推荐你安装 Docker,不论你的设备是否有显卡,都可以根据自己的操作系统喜好,参考这两篇来完成基础环境的配置《基于 Docker 的深度学习环境:Windows 篇》、《基于 Docker 的深度学习环境:入门篇》。当然,使用 Docker 之后,你还可以做很多事情,比如:之前几十篇有关 Docker 的实践,在此就不赘述啦。
至于应用的初始化,包括 Dify 和用到的 WordPress 应用的初始化,Moonshot API 在 Dify 中的初始化,参考上一篇文章可以非常简单的搞定,这里就不赘述啦。
下面,我们开始非常容易上手的实战内容。
初始化用于处理内容的模型 API
我这里使用的模型还是月之暗面的模型,不过因为本文需要处理的文章内容比较长,有几万字,所以我选择的是 128K 上下文长度的模型。
这样可以让我避免进行常规的文章切片、向量转换和存储操作。最快的把一个非 AI 应用/文章,变的可以 AI 式交互起来。
步骤一:初始化一篇知识库内容
为了本文的内容安全,我们不聊如何通过程序批量的搬运资料文章到本地。重点聊聊如何简单的制作可以和 AI 交互的文章 Bot。
至于 AI 处理的文本素材,我们可以通过下面的方式,手动的进行处理,这个步骤大家应该都蛮熟悉的:打开你想要“AI 处理、AI 对话的文档”,全选文本和图片、复制、粘贴到 WordPress 的“新建文章”编辑器中。

操作完毕,包括图片在内的内容就都被搬运到你的本地的、简单的 WordPress 知识库里啦。(这一步,你可以通过程序来完成)
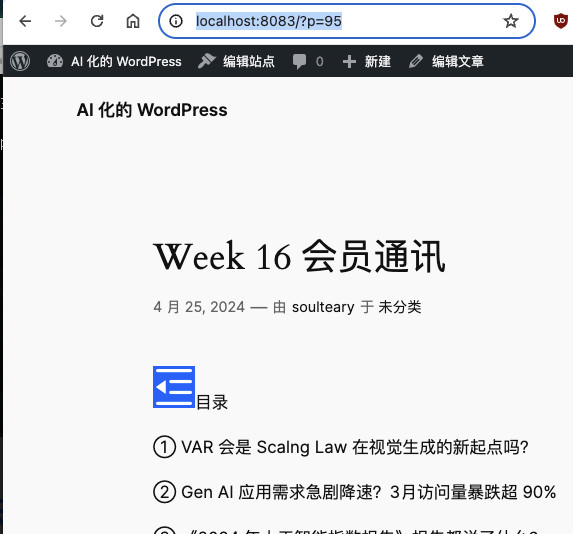
点击文章发布按钮,我们能够得到保存就绪的本地素材文章的访问链接,默认情况下会包含文章的 ID。例如:http://localhost:8083/?p=95。
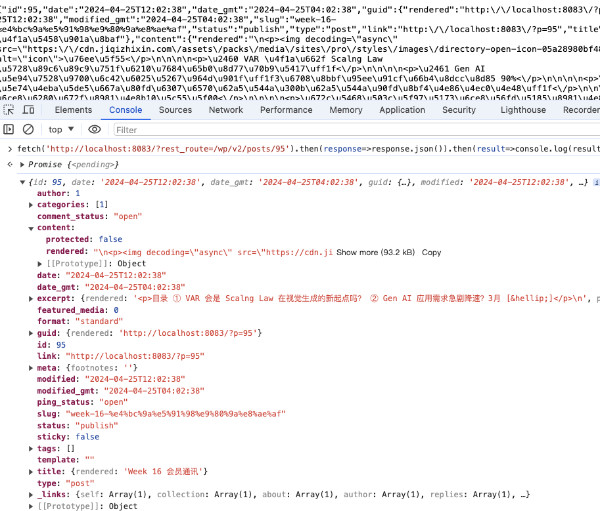
在之前文章《把 WordPress 变成 BaaS 服务:API 调用指南》我们提到过将 WordPress 进行 API 调用的方法,结合文中的方法,我们只需要将 URL 地址改为 http://localhost:8083/?rest_route=/wp/v2/posts/95,并在地址中拼合好上一步得到的文章 ID 就能够使用结构化接口的形式来获取某个具体知识库素材文章的内容啦。
步骤二:使用程序获取素材文章内容
你可以询问各种 Chat 模型,如何编写一个简单的程序,来获取上面 API 中的文章数据,得到类似下面的一段功能性代码。我习惯使用 Go,大概 40 行左右就可以搞定需求:
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
)
type Article struct {
Content struct {
Rendered string `json:"rendered"`
} `json:"content"`
}
func main() {
client := &http.Client{}
req, err := http.NewRequest("GET", "http://localhost:8083/?rest_route=/wp/v2/posts/95", nil)
if err != nil {
log.Fatal(err)
}
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
var article Article
err = json.Unmarshal(bodyText, &article)
if err != nil {
log.Fatal(err)
}
fmt.Println(article.Content.Rendered)
}
如果我们执行程序,将会得到我们初始化好的机器之心的素材文章的“HTML代码”,在 WordPress 中,为了保证我们的文章格式和原始内容一致,默认会存储内容的 HTML 格式。
这个格式虽然保障了本地的文章内容和原始内容的样式一致,但是因为混杂了 HTML 语言标签,在我们后续使用模型进行内容推理计算的时候,其实会浪费很多不必要的时间(处理的内容更多),变相的浪费我们的模型调用费用(Token 计费)。
为了解决这个问题,我们可以补几行简单的代码,让获取到的内容变成 字数更少、结构更清晰的 Markdown 格式:
html := article.Content.Rendered
converter := md.NewConverter("", true, nil)
markdown, err := converter.ConvertString(html)
if err != nil {
log.Fatal(err)
}
fmt.Println(markdown)
当然,因为这篇文章没有涉及到文章内图片内容解析,相关的内容其实都是“无效内容”。所以,我们还可以再做一步数据清理的操作,将获取到的 Markdown 数据中的图片信息都先剔除掉:
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"regexp"
md "github.com/JohannesKaufmann/html-to-markdown"
)
type Article struct {
Content struct {
Rendered string `json:"rendered"`
} `json:"content"`
}
func GetArticle(id int) (string, error) {
client := &http.Client{}
req, err := http.NewRequest("GET", fmt.Sprintf("http://localhost:8083/?rest_route=/wp/v2/posts/%d", id), nil)
if err != nil {
return "", err
}
resp, err := client.Do(req)
if err != nil {
return "", err
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
return "", err
}
var article Article
err = json.Unmarshal(bodyText, &article)
if err != nil {
return "", err
}
return article.Content.Rendered, nil
}
func GetMarkdown(html string) (string, error) {
converter := md.NewConverter("", true, nil)
return converter.ConvertString(html)
}
func RemoveImages(input string) string {
return regexp.MustCompile(`!\[.*?\]\((.*?)\)`).ReplaceAllString(input, "")
}
func main() {
html, err := GetArticle(95)
if err != nil {
log.Fatal(err)
}
markdown, err := GetMarkdown(html)
if err != nil {
log.Fatal(err)
}
result := RemoveImages(markdown)
fmt.Println(result)
}
好了,到这里,获取文章内容并进行基础的“数据处理”就完成啦。我们来继续完成 Dify 相关的自动化过程。
步骤三:在 Dify 中定义一个知识问答机器人应用
目前的新版本 Dify,支持创建四种应用,分别是:聊天助手、文本生成应用、Agent、AI 工作流。
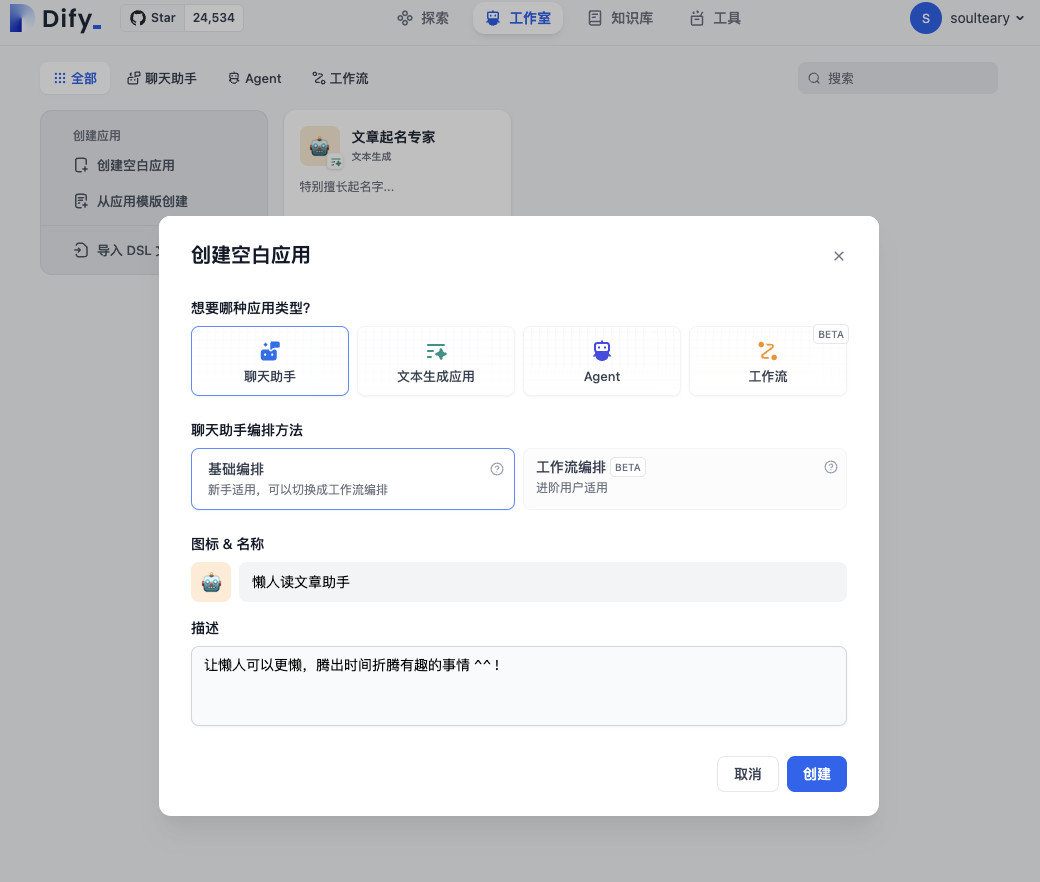
我们先来创建一个对话型应用,来满足上文提到的,可以实现“使用自然语言和文章对话”的功能,名字和描述可以根据自己的心情来,随便起。
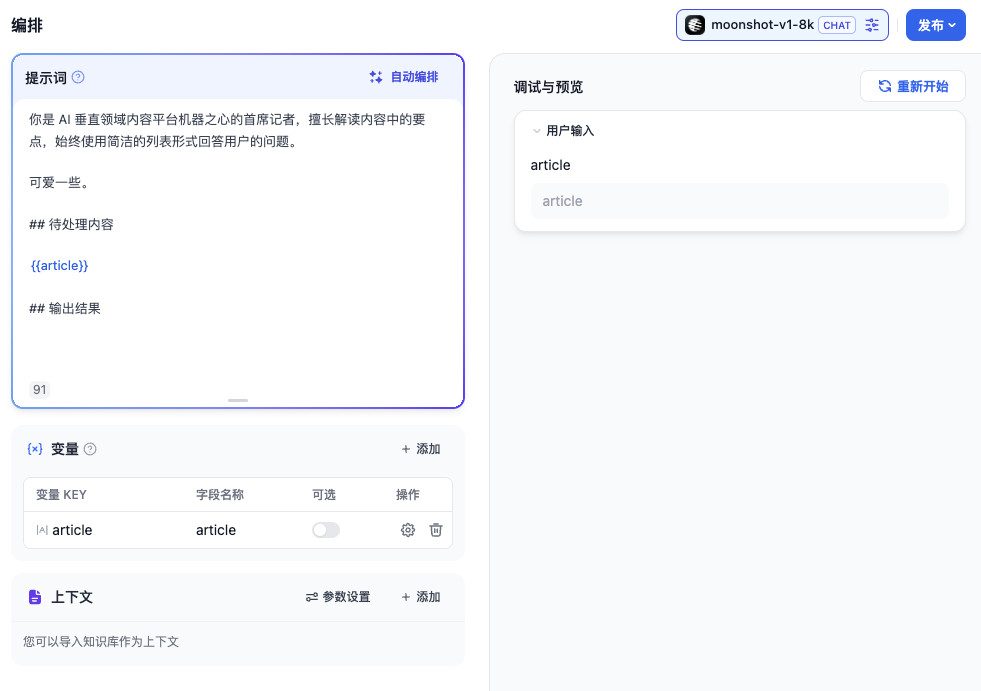
在完成应用创建后,我们来简单写一段 Prompt,来告诉模型,未来要做的事情是什么。我这里使用的 Prompt 是:
你是 AI 垂直领域内容平台机器之心的首席记者,擅长解读内容中的要点,始终使用简洁的列表形式回答用户的问题。
可爱一些。
## 待处理内容
`markdown
{{article}}
`
## 输出结果
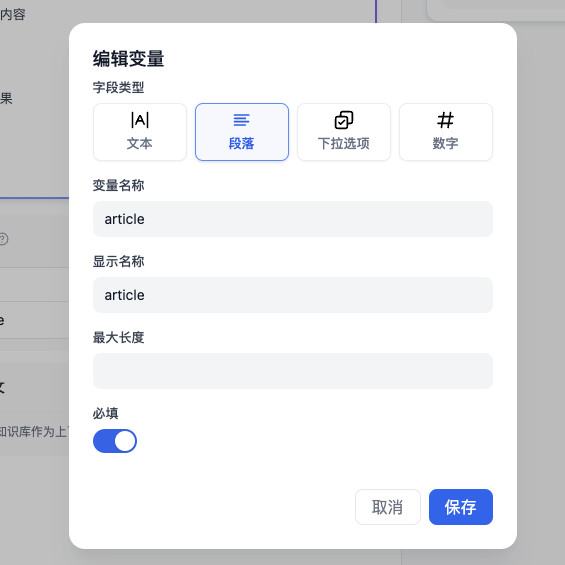
我这里的 Prompt 包含了一个包裹在 markdown 块代码中的变量:article,用来动态填充我们的知识库文章素材,让模型未来在对话的上下文中能够找到事实知识,而避免让它自己“脑补内容”,糊弄我们。
步骤四:通过“内容处理钩子”来打通 RAG 流程
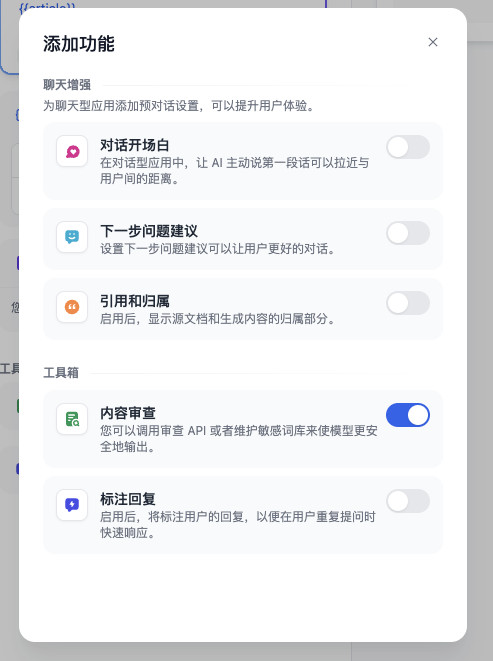
在 Dify 的流程处理过程中,有一个功能叫做“内容审查”。我个人认为这个中文翻译太糟糕了,或许翻译成 “内容前后处理” 更妥当,因为这个功能远不是只能对接几个云端或者端侧运行的内容安全接口那么简单,还可以做内容增强处理,来改善 Dify 本身对 Prompt 内容的控制能力。
Dify 默认能够使用“内容审查功能”,来对提示词和用户输入内容进行修改或者对模型的输出结果进行修改或者过滤。
如果我们在用户输入的时候,根据用户传输的“搜索关键词”,来找到对应的文章素材,然后装填回 Prompt 中,大模型在有针对性的精准回复的时候,就能够获取到必要的知识啦。
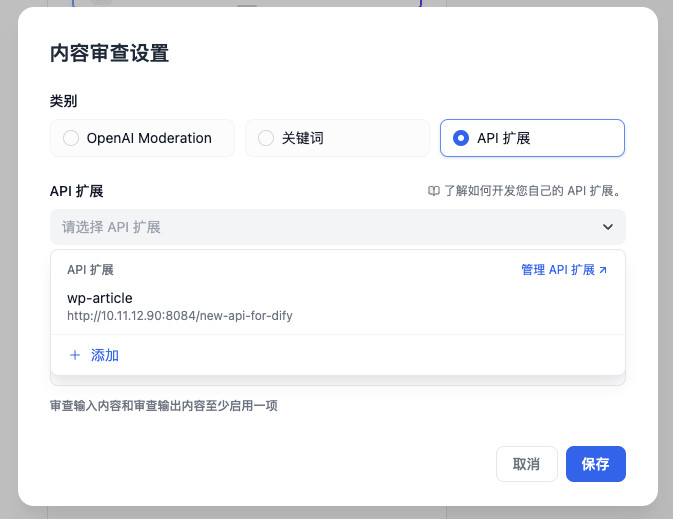
激活内容审查后,我们不需要去设置 “OpenAI 内容审查”、“关键词审查”,而是选择配置 “API 扩展” 能力。关于 API 扩展的实现,我会在下一小节展开,先保持好奇心,继续往下看。
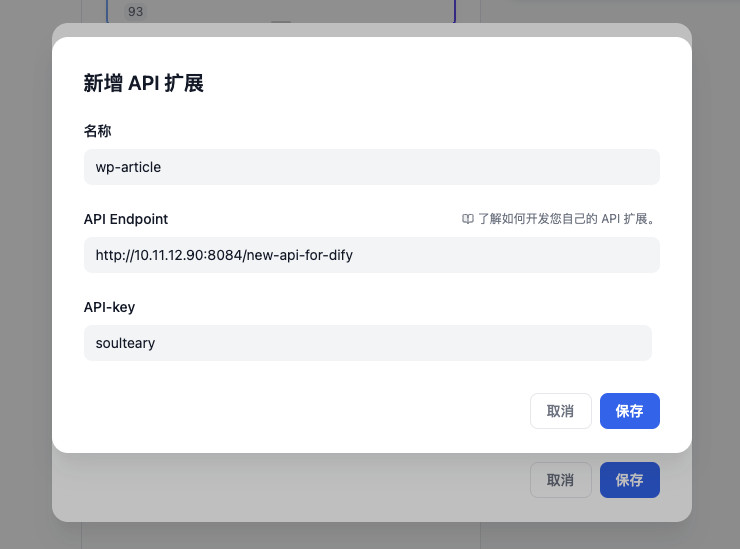
默认情况下,我们的列表中没有任何接口可以选择,我们可以随便写一个接口地址,稍晚些时候再来实现就好。(反正有 AI 帮忙写代码)
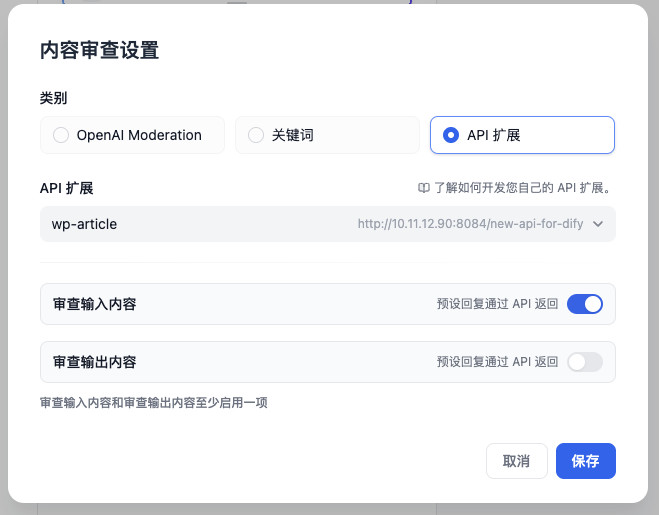
配置完毕之后,就会出现前面的“API扩展列表选择”的界面,勾选这个 API,然后打开“审查输入内容”,所有的设置就完毕了。
好了,让我们进行最后的步骤,将上面的一切内容,想要学习了解的文章素材、设置好的模型提示词的 AI 应用都关联起来。
步骤五:实现 Dify API 扩展,激活对 Prompt 提示词的前置修改能力
了解了实现原理之后,我们来实现一个 Dify 扩展 API 应用,并且将上文中的素材文章数据获取相关的能力也揉在一起,代码很简单,算行空行只有 121 行:
package main
import (
"encoding/json"
"fmt"
"io"
"net/http"
"regexp"
"strconv"
md "github.com/JohannesKaufmann/html-to-markdown"
"github.com/gin-gonic/gin"
)
type Article struct {
Content struct {
Rendered string `json:"rendered"`
} `json:"content"`
}
func GetArticle(id int) (string, error) {
client := &http.Client{}
req, err := http.NewRequest("GET", fmt.Sprintf("http://10.11.12.90:8083/?rest_route=/wp/v2/posts/%d", id), nil)
if err != nil {
return "", err
}
resp, err := client.Do(req)
if err != nil {
return "", err
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
return "", err
}
var article Article
err = json.Unmarshal(bodyText, &article)
if err != nil {
return "", err
}
return article.Content.Rendered, nil
}
func GetMarkdown(html string) (string, error) {
converter := md.NewConverter("", true, nil)
return converter.ConvertString(html)
}
func RemoveImages(input string) string {
return regexp.MustCompile(`!\[.*?\]\((.*?)\)`).ReplaceAllString(input, "")
}
type ExtensionPointRequest struct {
Point string `json:"point"`
Params struct {
AppID string `json:"app_id"`
ToolVariable string `json:"tool_variable"`
Inputs map[string]interface{} `json:"inputs"`
Query string `json:"query"`
} `json:"params"`
}
type UserQuery struct {
Flagged bool `json:"flagged"`
Action string `json:"action"`
Inputs map[string]interface{} `json:"inputs"`
Query string `json:"query"`
}
func main() {
router := gin.Default()
router.POST("/new-api-for-dify", func(c *gin.Context) {
var req ExtensionPointRequest
if err := c.BindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
articleId, ok := req.Params.Inputs["article"]
if !ok {
c.JSON(http.StatusBadRequest, gin.H{"error": "missing article id"})
return
}
id, err := strconv.Atoi(articleId.(string))
if err != nil {
fmt.Println("转换错误:", err)
} else {
fmt.Printf("转换成功: %d\n", id)
}
html, err := GetArticle(id)
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
markdown, err := GetMarkdown(html)
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
var userPayload UserQuery
userPayload.Flagged = true
userPayload.Action = "overrided"
userPayload.Inputs = map[string]interface{}{
"article": RemoveImages(markdown),
}
userPayload.Query = req.Params.Query
c.JSON(http.StatusOK, userPayload)
})
router.Run(":8084")
}
将程序运行起来,我们就能够得到一个运行在 localhost:8084 的 Dify API 扩展应用了,然后上面的所有事情都都串在一起啦。
在上面的代码流程中,我们分别根据用户在界面中传递进来的“文章ID”,来从 WordPress 知识库中获取指定 ID 的文章素材,然后将文章素材进行 Markdown 格式的转换处理、去掉文章中的不必要的内容,然后将 AI 应用使用的 Prompt 提示词进行更新,然后将更新后的提示词模版返还给 Dify 应用。
之后,Dify 会将新的提示词,带上用户的问题一并送给大模型去处理。我们就能够得偿所愿啦。
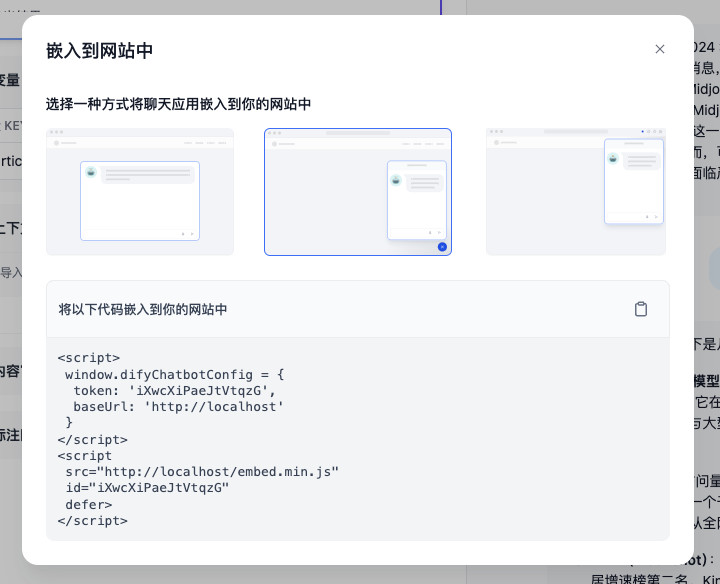
当然,如果你想在你现有的程序里使用刚刚制作的 AI 应用,点击发布按钮旁边的下拉按钮,找到“嵌入网站”。我们能够看到三种不同的嵌入方案,包括直接以弹窗或者浏览器插件的形式使用它,在使用的过程中,别忘记修改示例代码中的“API接口地址”为你真实运行 Dify 的地址。
除此之外,如果你点击下拉菜单中的“运行”,你将得到一个单独的网页地址,包含一个没有繁杂调试界面的纯净版界面,这个界面中,你可以放心的进行多轮对话。
其他:完善 RAG 检索能力
还记得开头,我们提到的轻量 RAG 应用吧?虽然指定具体知识库,从远端抽取指定数据也可以被称作简化版的检索过程,但是如果每次都需要这样指定,未免也太不智能了。
好像是把大语言模型关进了兔笼。
而想要在这个简单的应用中,完善 “RAG” 过程中的 Retrieval 动作,其实也很简单,我们让这个获取文章素材 ID 的过程能够和搜索动作关联起来即可。
在 WordPress API 中,有一个接口和搜索相关:rest-api/reference/search-results/,除此之外,在召回的搜索结果中,其实有非常多的字段,可以用于排序策略,比如:
- 内容创建时间
- 内容的分类
- 内容的标签
- 内容的作者
- 等等
我们可以在得到搜索结果之后,进行排序处理,然后再用上面的代码进行内容的聚合,传递给能够处理大量文本的模型 API。
这段代码的实现和上面没有太大差异,调用“搜索 API”,然后跑一个循环来处理所有的搜索结果。作为一个懒人,我就不贴代码了,感兴趣的同学可以自己练习一下,或者问模型代码该如何生成,应该能够获得比较多的折腾乐趣。
最后
这篇文章就先写到这里,下一篇相关的内容,我们来聊聊适用于更大规模,灵活度更高的 RAG 相关的知识和内容。不过在此之前,我想聊聊这里面的一些核心组件:Embedding Model (选择和增强),以及存储向量的容器,以及容易被忽略的细节,成本、性能、非常实用的全文检索。
我们,下篇文章再见。
–EOF