翻译工具并不稀缺,但围绕翻译形成的工作流却各不相同。
Kakapo 是一个基于 Wails v3、Go 和 Echo 构建的本地桌面应用,它尝试把多个 OpenAI 兼容模型收拢到同一个界面里,并提供翻译、比较、回译和历史记录等能力。
本文记录这个项目的实现过程,以及这套技术栈在桌面工具场景下的一些实践和取舍。
写在前面
翻译几乎是每天都会出现的动作,不论是在看国外项目文档、不同语言的技术资料,还是在处理邮件,或者是在给开源项目补 README 或整理技术文章。
原本一直在用 Mate,但慢慢发现自己的使用场景和它最擅长解决的问题有些偏离。我越来越少在网页里直接翻译内容,更多时候是在编辑器、终端、文档和 IM 工具里复制一段文本,然后希望同时看看几个模型的结果。
但其实,翻译本身并不复杂。真正麻烦的地方,往往出现在翻译之外。同样一段内容,需要反复复制和整理;几天之后想找回某个译文时,也不一定记得当时是怎么得到的。这些问题都不算大,但会反复出现。
于是,二月份春节期间抽空做了个小工具,名字叫 Kakapo。

软件功能非常简单,这里就不过多介绍了,下载之后,填入模型的 API 就能够正常使用了。
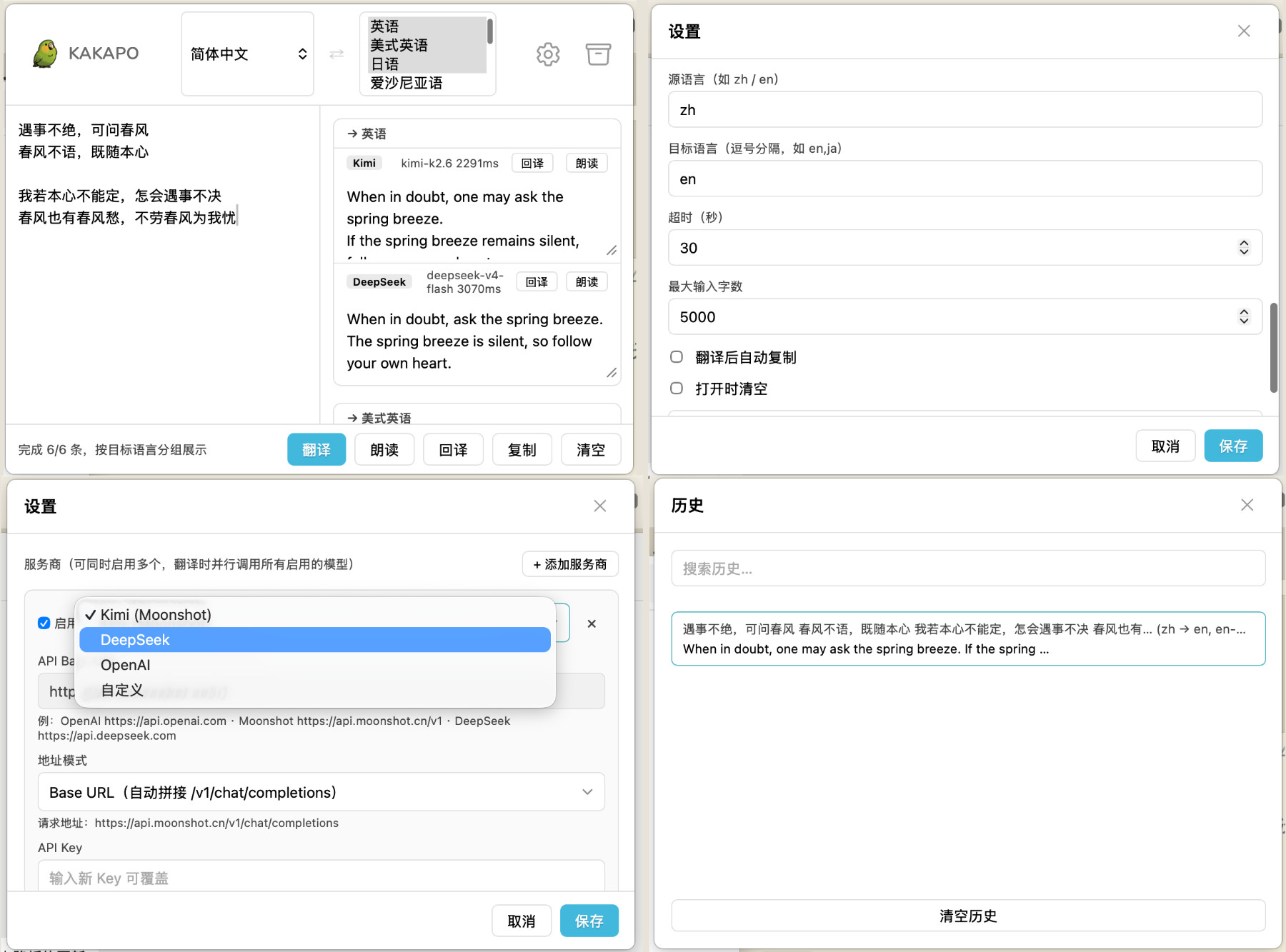
虽然这个工具软件本身并不复杂,但在实现过程中,顺便把 Wails v3、Go、Echo、系统 WebView、Keychain 和 OpenAI 兼容接口这套组合重新走了一遍,也还是踩了一些小坑。
这篇文章记录一下这个项目,以及这套技术栈在桌面工具场景下的一些实践和思考。
开源项目地址: https://github.com/soulteary/kakapo/
如果你觉得对你有帮助,欢迎“一键三连”。
为什么没有继续用 Mate
在做 Kakapo 之前,我其实用过一段时间 Mate。
无论是浏览器插件,还是 Setapp 里的桌面版本,Mate 都是一个完成度比较高的翻译产品:网页翻译、选中文字翻译、PDF、字幕、词典、发音、短语本、跨设备同步,这些能力都已经比较成熟。
所以,Kakapo 不是因为“找不到翻译工具”才出现的。
恰恰相反,正是因为已经有成熟翻译工具,才更容易发现自己的需求和这些产品的设计目标并不完全重合。
第一个问题是速度。
这里说的速度,不只是接口响应时间,而是完成一次翻译动作的整体时间。
很多时候,我并不是在浏览网页。而是在编辑器、终端、邮件客户端、文档或者 IM 工具里工作。
这类场景下,最常见的动作其实是:
复制一段文本
切换到翻译工具
粘贴
获得结果
复制回原来的工作区
Mate 在网页内嵌翻译、选中文字翻译、查词和语言学习场景里很方便。但如果大部分内容本来就来自复制粘贴,那么我更需要的是一个处理文本片段的本地工作台,而不是一个围绕网页阅读展开的翻译产品。
第二个问题是翻译风格。
传统翻译工具解决的是:
把内容翻译出来
但我更常遇到的是:
这个表达是否自然
这个语气是否合适
这个术语是否符合上下文
这段话能不能更像人写的
随着大模型的发展,翻译越来越像一种语义转换,而不只是语言转换。有时候我并不需要逐字对应。我需要的是保留原意,同时让目标语言里的表达更自然、更符合当前语境。
第三个问题是决策。
以前翻译工具通常给一个结果。现在我更习惯同时看看几个模型对同一段内容的处理:
Kimi
DeepSeek
OpenAI
其他 OpenAI 兼容服务
有时候它们给出的结果差不多。有时候差异会非常明显。
最终采用哪个版本,或者从几个版本里合并一个更合适的表达,本身已经变成工作流的一部分。
大多数成熟翻译产品并不把这个场景放在核心位置,它们更关心快速给出一个稳定结果。而我需要的是多个候选结果,以及基于这些结果做判断。
Kakapo 最初就是从这里开始的。它没有试图重新发明翻译能力,也不是要替代 Mate、DeepL、Google Translate 这类成熟产品。
它只是把多个模型放到同一个界面里。
对于经常需要复制粘贴文本、比较不同模型表达方式的人来说,省掉一些重复动作,然后把选择权重新交还给使用者。
Kakapo 做了什么
Kakapo 的能力其实可以分成四部分:模型调用、桌面能力、本地数据和一些辅助功能。
最核心的是模型调用。
它通过 OpenAI 兼容接口 (OpenAI Compatible Chat Completions) 接口接入模型服务。目前预设支持 Kimi、DeepSeek 和 OpenAI,也支持接入其他兼容接口的模型服务。
翻译时,会自动展开多个模型和目标语言的组合请求,并将结果按目标语言分组展示,方便直接比较不同模型的表达差异。
其次,是桌面能力。
项目基于 Wails v3 构建,因此除了翻译功能之外,也包含一些桌面应用常见能力:系统托盘、应用菜单、启动页、Dock Badge、本地资源嵌入、前后端事件通信。
这些能力和翻译本身关系不大,但决定了它是否能够作为一个长期驻留在桌面上的工具使用,用户体验到底如何。
另外,和很多脚本工具不同,Kakapo 会保存一些本地状态。
例如,服务商配置、翻译历史以及 API Key。
其中普通配置保存在本地文件中(settings.json),API Key 使用 macOS Keychain 保存,历史记录(history.json)则保存在本地并支持简单搜索。
最后,是一些辅助功能。
比如:系统朗读、回译、历史记录、结果复制、错误透传。
这些功能单独看都不复杂。但组合起来之后,基本能够覆盖我日常使用翻译工具时的大部分需求。
和翻译产品的不同取向
如果把 Kakapo 和 Mate、DeepL、Google Translate 这类产品放在一起比较,很容易陷入一个误区:比较谁的功能更多。
按这个标准,Kakapo 并没有优势:网页翻译、PDF、字幕、词典、短语本、同步、语言学习,这些能力都不是它的重点。
因为,它原本就不是按照翻译产品的思路设计的。
成熟翻译产品更关注:给用户一个稳定结果、围绕结果提供阅读和学习体验。
而 Kakapo 更关注:接入多个模型、比较多个结果、保留模型选择权、把翻译能力放进我自己的工作流。
两者解决的问题并不完全相同。
如果你的需求是阅读网页、学习语言或者跨设备同步,成熟翻译产品通常会是更好的选择。
所以严格来说,Kakapo 和这些成熟翻译产品并不完全在同一个方向上。前者更关注模型选择和结果比较,后者更关注翻译体验本身。
不同的工作流,对应的自然也是不同的工具设计。
一些实践和取舍
让我们来聊聊制作项目过程中的实践、思考和取舍。
项目是怎么组织起来的
Kakapo 的结构并不复杂。
它外面是一层 Wails v3 桌面应用,负责窗口、托盘、菜单、Dock Badge 和本地资源加载;里面是 Go 写的业务逻辑,负责配置、密钥、历史、模型请求和系统能力;前端则是一个普通 Web 页面,用来处理输入、设置、结果展示和历史查看。
简化之后,大致是这样:
Kakapo Desktop App
├── Wails v3
│ ├── 原生窗口
│ ├── 托盘 / 菜单 / Dock Badge
│ ├── 嵌入 frontend/dist 静态资源
│ └── 注册多个 Service
│
├── Go 后端
│ ├── TranslateWebService: /translate
│ ├── EchoService: /api
│ ├── TranslateApp: 翻译业务
│ ├── config: settings.json
│ ├── secrets: macOS Keychain / 非 macOS stub
│ ├── history: history.json
│ ├── speech: macOS say / 非 macOS unsupported
│ └── translate: OpenAI 兼容客户端
│
└── 前端页面
├── /app/index.html
└── /translate/index.html
主要功能都在 /translate 下面。
翻译页面并没有直接把所有逻辑写进前端,而是通过一组 HTTP 风格的接口调用 Go 侧服务:
POST /translate/api/translate
GET /translate/api/settings
PUT /translate/api/settings
GET /translate/api/history
POST /translate/api/history
DELETE /translate/api/history
POST /translate/api/speak
POST /translate/api/splash
这里有一个小取舍。
Wails 本身支持 Go 和前端之间的绑定调用,但 Kakapo 没有完全依赖这条路线,而是在 Wails Service 里挂了 Echo,把翻译功能写成了更接近普通 Web API 的形式。
这样写的好处是边界比较清楚。
前端就是 fetch('/translate/api/...'),后端就是路由、请求体、响应体和状态码。如果未来想把某些能力拆成独立服务,这种结构也比较容易迁移。
代价是类型约束弱一些。
前端需要自己维护请求封装,Go DTO 和 JavaScript 对象之间也需要保持一致。项目规模小的时候问题不大,接口多起来之后,就需要考虑 TypeScript 类型、OpenAPI 描述或者契约测试。
为什么选择 OpenAI 兼容接口
Kakapo 的模型接入层选择了 OpenAI 兼容接口(OpenAI Compatible Chat Completions)。
这个选择并不复杂。
现在很多模型服务都提供了类似 OpenAI 的接口形态。请求体通常围绕 model 和 messages 展开:
{
"model": "kimi-k2.6",
"messages": [
{ "role": "system", "content": "..." },
{ "role": "user", "content": "..." }
]
}
这样做最大的好处是接入成本低。
无论是 Kimi、DeepSeek,还是其他兼容 OpenAI 接口的服务,都可以通过类似的方式接进来。前端和后端也不需要为每家服务商单独维护一套 SDK。
但实际使用之后会发现,“兼容 OpenAI”并不等于“完全一致”。
不同服务商之间还是会有很多细节差异:
Base URL 是否包含 /v1
是否支持 temperature
是否支持 max_tokens
是否支持 reasoning_effort
是否支持 thinking
错误结构是否一致
限流策略是否一致
流式输出格式是否一致
Kakapo 当前已经对部分模型做了参数适配。
例如 kimi-k2* 系列不会发送 temperature,会关闭 thinking,并设置较大的 max_tokens。DeepSeek 的推理模型则会省略 temperature,设置 reasoning_effort=high,并开启 thinking。其他模型则尽量按标准形态发送。
这个处理方式足够实用,但也有明显边界。
目前它主要依赖模型名前缀判断。对于一个小工具来说,这样做简单直接;但如果要长期维护更多服务商,最好把这些规则抽出来,变成可配置的 Provider / Model Profile。
例如:
providers:
moonshot:
models:
kimi-k2.6:
endpoint_mode: openai_base
send_temperature: false
thinking: disabled
max_tokens: 32768
deepseek:
models:
deepseek-reasoner:
endpoint_mode: openai_base
send_temperature: false
reasoning_effort: high
thinking: enabled
这样新增模型时,不一定需要修改 Go 代码。这也是做多模型工具时很容易遇到的问题:统一接口可以降低接入门槛,但服务商差异依然需要一个可维护的描述层。
目前我用来翻译使用的模型比较固定,等这个场景使用的模型更多一些的时候,再更新吧。
一次翻译请求会发生什么
以一次多模型翻译为例,Kakapo 大致会做这些事情:
1. 前端收集输入文本、源语言和目标语言
2. POST /translate/api/translate
3. 后端加载 settings.json
4. 读取启用的 provider 和 model
5. 从 Keychain 获取每个 provider 的 API Key
6. 展开任务:provider × model × targetLanguage
7. 使用有限并发调用上游 Chat Completions
8. 收集每个任务的输出、耗时或错误
9. 返回 MultiTranslationResult
10. 前端按目标语言分组渲染结果卡片
11. 前端将结果写入历史
这里最关键的是任务展开。
如果启用了 3 个服务商,每个服务商 2 个模型,同时翻译成 3 种语言,一次翻译就会变成 18 个上游请求。
请求数量变多之后,不能直接一股脑全部发出去。一方面容易触发限流,另一方面失败集中出现时也很难判断原因。
所以 Kakapo 在 Go 后端里用了一个固定大小的信号量限制并发:
sem := make(chan struct{}, maxParallelTranslations)
var wg sync.WaitGroup
for i, tk := range tasks {
wg.Add(1)
go func() {
defer wg.Done()
sem <- struct{}{}
defer func() { <-sem }()
// call upstream model
}()
}
wg.Wait()
这个写法很朴素,但第一阶段够用。它不需要额外依赖,结果顺序也容易保持稳定。
当然,它也比较粗。
现在所有服务商共享同一个并发上限,但现实里不同服务商的速率限制和响应速度并不一样。继续往下做,可以拆成全局并发、服务商级并发、模型级超时、429 退避、失败任务单独重试等几层。
现在还没必要一上来就做成完整调度系统,但这个边界要明确。
另一个细节是“部分成功”。
多模型翻译里,某个模型失败很常见。可能是 Key 没配,模型名写错,参数不兼容,服务商限流,网络超时,或者上游返回格式变了。
如果一个模型失败就让整个翻译失败,体验会很差。
所以 Kakapo 的每条结果都有自己的 output、latencyMs 和 error。一个模型失败,不影响其他模型结果展示。
对对比工具来说,这比“一处失败,全部失败”更合适。
接入不同模型服务时遇到的一个小问题
接入 OpenAI 兼容接口服务时,Base URL 是一个很容易被低估的配置项。
很多服务看起来都兼容 OpenAI,但地址规则并不完全一样。有的服务希望用户填写类似下面这样的 Base URL:
https://api.moonshot.cn/v1
https://api.deepseek.com
https://api.openai.com
客户端再自动拼接 Chat Completions 路径。
也有一些自定义网关或内部服务,直接要求填写完整 endpoint。这个时候,如果客户端继续自动补 /v1/chat/completions,反而会把地址拼错。
所以,在这类工具里,模型服务地址最好不要完全依赖隐式拼接。
更稳妥的方式,是明确区分两种输入:
Base URL:填写服务根地址,由客户端补全 Chat Completions 路径
Full Endpoint:填写完整请求地址,客户端直接使用
这不是一个很大的功能,但对自定义服务商接入很有帮助。
尤其是在企业内部网关、模型代理、统一转发服务这些场景里,请求路径未必和公有云模型服务完全一致。把 endpoint 规则显式化之后,配置成本会稍微增加一点,但排错成本会低很多。
尽量显式声明,不要依赖“直觉”。
错误信息不能只写“失败”
多服务商工具里,有效展示错误信息非常重要。
第一次配置模型时,最常见的问题往往不是模型不会翻译,而是配置没配对。比如:
401:API Key 错误或未设置
429:限流或额度问题
400:参数不兼容、模型名错误、请求体格式错误
5xx:服务商异常
网络错误:DNS、代理、TLS、连接超时
响应解析错误:服务商返回结构不符合预期
如果界面只显示“请求失败”,排查会很痛苦。
Kakapo 的客户端会尝试解析几种常见错误结构:
{"error": {"message": "..."}}
{"error": "..."}
{"message": "..."}
如果解析不了,就截断原始响应返回。
这个实现同样不复杂,但很实用。它不能解决所有兼容性问题,但至少能让用户知道错误大概出在哪里。后面,其实还可以继续补设置页的“测试连接”、复制错误详情、按服务商记录最近错误、对 429 做退避重试、对 400 显示可能原因等能力。
这些功能不会提高翻译质量,但会明显降低排错成本,也能减少配置错误带来的中断感和工作效率下降。
数据存储:API Key 和翻译内容其实是两件事
Kakapo 把普通配置和 API Key 分开保存。
普通配置进入 settings.json,例如服务商、模型、源语言、目标语言、超时、最大输入长度等;API Key 则放进 macOS Keychain。
前端读取设置时,绝对不会(也不应该)拿到明文 Key,只会看到:
apiKeySet: 是否已经设置
apiKeyMask: 脱敏后的尾号提示
这比把 API Key 写进普通 JSON 文件要好。
但这并不意味着整个工具就是“安全”的。因为翻译历史仍然会保存到本地 history.json。如果翻译的是敏感邮件、合同片段、内部文档,内容仍然可能落盘。
所以,这里要分开看:
API Key 不写普通配置文件
翻译内容是否落盘,是另一类隐私问题
当前 Kakapo 的边界很清楚:
API Key:macOS Keychain
普通配置:settings.json
翻译历史:history.json,未加密
非 macOS 密钥存储:当前是 stub
这不是问题本身,而是当前阶段的取舍。如果要更适合敏感内容,至少需要补隐私模式、默认不保存历史、历史自动过期或者历史加密。
做这类本地工具时,不要把“密钥安全”和“内容隐私”混在一起。
API Key 进系统密钥链,只解决密钥保存问题。用户输入和模型输出是否保存、保存多久、怎么删除,是另一套设计。
本地历史先简单做
Kakapo 的历史记录使用本地 JSON 文件。
目前它做的事情很克制:
保存在用户配置目录下
最多保留最近 50 条
支持搜索 input 和 output
支持清空历史
用 mutex 保护读写
兼容旧格式字段名
这个方案适合当前阶段:不需要数据库,文件也方便排查。
但它不适合承担长期知识库的角色。因为它没有加密、标签、收藏、导出、按语言筛选、按模型筛选、全文索引和长期数据迁移策略。
所以当前历史更适合找回最近译文。如果将来希望把 Kakapo 做成长期写作和翻译辅助工具,历史模块应该单独设计,而不是继续在 JSON 里堆字段。就比如 SQLite 就是个很适合的选型。
TTS 先用系统能力
Kakapo 里有一个朗读功能,目前在 macOS 上直接调用系统的 say 命令。
这个选择主要是为了简单。
朗读只是翻译流程里的辅助能力,没有必要第一版就再接一个云端 TTS 服务。使用系统能力的好处是,不需要额外申请 API Key,也不会因为朗读再多一次云端请求。实现上还做了一个小处理:新的朗读请求会取消上一段还没播放完的内容,避免几个声音叠在一起。
当然,这个方案的边界也很清楚。
它当前主要面向 macOS,依赖系统自带语音。不同系统、不同语言下的语音质量和可用性都不一样。如果后续要做跨平台,就需要分别补 Windows 和 Linux 的 TTS 实现。
如果想要更自然的声音,也可以接入云端语音服务。但那又会带来新的问题:费用、API Key 管理、网络请求,以及翻译内容是否会被再次发送到第三方服务。
所以在当前阶段,系统 TTS 是一个够用的起点。
它不追求完整语音能力,只解决一个很具体的问题:翻译完成后,能顺手听一下结果,尤其是在翻译单个字、词的场景。
Wails v3 的好处和代价
Kakapo 用 Wails v3 做“桌面壳”,这个选择和项目本身的需求有关。
它需要一个本地窗口,需要系统托盘、菜单、Dock Badge,也需要访问本地文件、Keychain 和系统命令。与此同时,主要业务逻辑在 Go 侧会更自然一些:读取配置、保存历史、请求模型接口、处理并发和超时。
如果用纯原生写界面,成本会高很多;如果用 Electron,又会引入一整套 Chromium 运行时。对 Kakapo 这种小工具来说,有些重。
Wails 介于两者之间:它允许用 Go 写后端和本地能力,用 Web 技术写界面。界面跑在系统 WebView 里,不需要随应用捆绑完整浏览器。窗口、菜单、托盘、事件和打包这些桌面应用常见能力,也都能放在同一个工程里处理。
对这个项目来说,这是比较合适的组合。
它的好处不是“功能最多”,而是启动成本比较低。我可以把主要精力放在模型调用、配置管理、历史记录和界面交互上,而不是先花很多时间处理桌面应用的基础设施。
当然,Wails 也不是没有代价。
首先,Wails v3 本身还比较新,API、文档和工具链都有继续变化的可能,文档里很多内容都有点问题。不过基于开源生态做事情,阅读源代码是必须的。好在 AI 时代,这个事情的时间成本无限降低。官方文档指路,实际基于源码和 AI Vibe 下就好了。
其次,它使用的是系统 WebView。这让应用更轻,但也意味着不同系统、不同版本之间会有差异。Kakapo 当前前端比较简单,影响不大;如果以后界面变复杂,兼容性测试就会变成实际成本。
最后,Wails 不会自动抹平所有平台差异。Keychain、TTS、托盘、菜单、Dock Badge、打包签名,这些事情仍然需要分平台处理。目前 Kakapo 现在也明显更偏 macOS,很多能力如果要扩展到 Windows 和 Linux,还需要继续补实现。
所以 Wails 的价值不是“消灭桌面应用复杂度”,而是可以降低了小型桌面工具的启动成本。
总的来说,如果项目的主要逻辑在 Go 侧,界面复杂度中等,又需要一些本地系统能力,Wails 是一个值得考虑的选择。但如果项目需要长期稳定的桌面框架 API、非常复杂的前端生态,或者强跨平台一致性,Electron、Tauri,甚至原生方案,都应该一起评估。
Go 适合处理这些本地逻辑
Kakapo 后端的大部分事情,放在 Go 里处理比较自然。
比如读取配置文件、保存历史、访问 Keychain、发起 HTTP 请求、处理超时、嵌入静态资源,以及管理 Wails 应用生命周期。这些都不是特别复杂的逻辑,但它们更接近“本地工具”的后端能力,而不是纯前端界面逻辑。
多模型翻译也是类似。
一次翻译可能会同时请求几个模型、几个目标语言。用 goroutine 和 channel 做并发控制,代码会比较直接,也不需要引入额外的调度框架。当前实现里,上游请求已经有 timeout,能避免某个模型一直卡住。
不过,timeout 和“完整取消链路”不是一回事。如果用户关闭窗口、马上重新发起翻译,或者未来前端增加“取消”按钮,取消信号最好能一路传到每个上游 HTTP 请求。
比较理想的链路应该是:
前端 AbortController
↓
Echo request context
↓
TranslateParallel context
↓
每个上游 http.Request context
↓
及时取消模型请求
不过,这不是第一版必须完成的事情。但如果后续支持长文本、流式输出,或者一次请求里包含更多模型,取消链路就会变得重要。否则用户已经不需要某次翻译结果了,后端还在继续请求模型,既浪费时间,也浪费上游额度。
Echo 作为一层 HTTP 边界
Kakapo 在 Wails Service 里挂了 Echo。
这不是唯一解。Wails 本身提供 Go 和前端之间的绑定调用,很多桌面应用直接用这套机制就够了。但 Kakapo 里,我还是保留了一层 HTTP 风格的接口。
主要原因是翻译这部分逻辑本身就很像一个小型 Web 服务:前端提交文本和目标语言,后端读取配置、拿 API Key、请求模型服务,然后把结果返回给前端。用 HTTP API 表达这件事很直观:
/translate/api/translate
/translate/api/settings
/translate/api/history
/translate/api/speak
路径清楚,状态码也清楚。
比如配置错误、API Key 缺失、上游限流、模型返回异常,都可以通过比较普通的 HTTP 响应表达出来。前端调用时也只是 fetch('/translate/api/...'),调试起来和普通 Web 项目差不多。这层边界还有一个好处:如果以后想把某些能力拆出去,或者临时用浏览器访问调试,迁移成本会低一些。
当然,它也有代价。
使用 HTTP API 之后,前端和后端之间的类型约束会弱一些。请求体和响应体需要自己维护,Go 里的 DTO 和前端对象结构也要保持一致。
项目规模小的时候,这个问题不明显。但接口一多,就需要更认真地管理契约。比如引入 TypeScript 类型、补 OpenAPI 描述、增加契约测试,或者把一部分内部调用重新放回 Wails 绑定里。
所以这里没有绝对正确的选择。
如果项目更像一个 Web 服务搬进桌面应用里,Echo 这层边界会比较自然。
如果项目更看重桌面应用内部调用的类型安全,Wails 绑定会更直接。
Kakapo 当前选择 Echo,主要是因为它的翻译服务本身更接近 HTTP API:输入明确、输出明确、错误也适合用状态码和 JSON 表达。
前端先保持简单
Kakapo 前端用了 Vite 和原生 JavaScript。
这个选择除了因为原生 JS 有性能优势外,对于高频场景收益更大之外,很重要的一点是当前界面还没复杂到必须引入框架。
翻译页主要做几件事:渲染语言列表、渲染服务商卡片、收集设置、调用翻译接口、按目标语言分组展示结果,以及处理复制、朗读、回译和历史搜索。
这些事情用原生 DOM API 都能完成。
这样做的好处是依赖少,构建简单,调试也直接。对于一个桌面小工具来说,第一版少引入一些前端复杂度,反而更容易把主流程跑通。
但这个选择也有边界。
现在页面里已经有不少状态:当前源语言、目标语言、最大输入长度、自动复制、最近一次翻译结果、服务商卡片、设置弹窗、历史弹窗、结果卡片等等。
功能少的时候,这些状态散在页面脚本里还可以接受。如果继续增加流式输出、卡片重试、收藏、标签、提示词模板、导入导出,继续依赖全局变量和 DOM 状态就会变得难维护。
当然,这也不是说后续要立刻引入 React 或 Vue。相比之下,更重要的是先把状态边界拆清楚:
settingsState
providersState
translationState
historyState
uiState
等这些状态关系真的开始变复杂,再考虑 TypeScript 或轻量前端框架会更合适。
Bun、Vite 和 Task
Kakapo 的前端用 Vite 构建,用 Bun 安装依赖和运行前端工具和脚本,用 Taskfile 组织常用命令。
粗看,这只是几个工具选择。但桌面应用和普通 Web 项目不太一样,它不只是把前端 build 一下就结束了。
实际开发时,会反复遇到这些事情:
安装前端依赖
生成 Wails bindings
构建多页面前端
把静态资源嵌入 Go 应用
生成图标
构建应用
运行应用
打包 macOS App
检查许可证头
这些命令如果都靠手敲,很快就会变得不好维护。所以,项目里用 Taskfile 把它们收拢起来。例如:开发、构建、运行、打包这些动作,都可以通过相对固定的任务入口完成。这样做不是为了追求工具链复杂,而是为了让项目在不同阶段都能按同一套流程重复执行。
代价也很明显。
从源码运行 Kakapo 时,开发者需要准备 Go、Wails CLI、Bun、Task,以及对应平台的打包环境。
好在,使用者只需要关心:
下载应用
配置服务商
开始翻译
而开发者才需要关心:
安装依赖
启动开发模式
构建前端
生成绑定
打包应用
架构取舍
我们将上面提到的内容放进一张表格里,大概是这个样子:
| 选择 | 带来的好处 | 需要承担的成本 |
|---|---|---|
| Wails v3 | 可以用 Go 写本地逻辑,用 Web 技术写界面,应用也不需要捆绑完整浏览器 | v3 仍然比较新,系统 WebView 和平台能力差异需要自己处理 |
| Go 后端 | 处理文件、HTTP 请求、并发、超时和本地系统能力都比较自然 | 如果团队主要是前端背景,上手和调试成本会高一些 |
| Echo API | 翻译能力可以按 HTTP API 来组织,路径、状态码和错误表达都比较清楚 | 类型约束弱于 Wails 绑定,需要维护前后端请求结构 |
| 原生 JS | 依赖少,第一版启动快,不需要过早引入框架复杂度 | 页面状态变多之后,需要更早整理状态边界 |
| OpenAI Compatible | 可以比较容易接入不同模型服务 | “兼容”不等于完全一致,模型参数和 endpoint 规则仍然要处理 |
| Keychain | API Key 不落在普通配置文件里 | 当前实现更偏 macOS,跨平台密钥存储还需要补齐 |
| JSON 历史 | 简单、可排查,不需要引入数据库 | 不适合长期历史、复杂筛选和敏感内容存储 |
这张表不是为了说明哪种技术更好。
很多时候,技术选择没有脱离场景的绝对答案。Kakapo 当前更像一个本地小工具,所以更看重启动成本、实现清晰度和可维护性。
如果它以后要变成面向更多用户的跨平台应用,取舍就会不一样。比如,历史记录可能需要从 JSON 迁移到 SQLite;模型参数适配可能需要从硬编码变成 Profile;前端也可能需要更明确的状态管理方式。
所以这里真正值得记录的不是“用了什么技术”,而是这些技术在当前阶段解决了哪些问题,又把哪些问题留到了后面。
当前项目边界
Kakapo 目前更接近个人工具和工程样例。
它解决的是文本片段翻译、多模型比较和本地模型接入的问题,不是网页翻译、语言学习工具,也不是完整的翻译项目管理系统。
做任何项目,边界设置其实非常重要。
因为一旦把目标放大,后面要补的东西会很多:跨平台密钥存储、Windows / Linux TTS、历史加密、流式输出、自动更新、签名、公证、崩溃上报、模型能力描述、服务商配置校验。
这些都不是不能做。只是它们会把项目从“一个本地翻译工作台”慢慢推向“完整桌面产品”。精力的投入会无限放大。
当前阶段,项目能够满足文章开头提到的需求,其实就足够啦。
如果你也想采用这套架构
如果你也想用 Wails v3、Go 和 WebView 做类似的小工具,最先要看的不是框架本身,而是项目形态。
这套组合比较适合这样的场景:
需要一个本地窗口
需要访问本地文件、系统命令或系统密钥链
主要逻辑更适合放在 Go 侧
界面复杂度中等
希望应用比 Electron 更轻
可以接受系统 WebView 的平台差异
可以接受 Wails v3 当前阶段的不稳定性
如果项目大致符合这些条件,Wails 会比较顺手。
尤其是那种“本地能力 + Web 界面 + 少量系统集成”的工具,Go 和 Wails 的组合启动成本不高,也容易把项目结构收住。
但如果项目面向大量普通用户公开分发,或者非常依赖跨平台一致性、复杂前端生态、自动更新、签名、公证、崩溃上报和长期稳定 API,那么就需要更谨慎。
这不是说 Wails 做不了。
而是这些事情不会因为用了 Wails 就自动消失。
做这类项目时,我觉得有几件事最好一开始就想清楚。
第一,平台能力要尽早列出来。
比如:密钥存储、TTS、托盘、菜单、通知、文件路径、打包、签名、自动更新。
这些能力在 macOS、Windows 和 Linux 上往往不是一套实现。越早列出来,越不容易后面才发现某个平台缺一块。
第二,模型服务最好抽象成能力描述。
OpenAI 兼容接口可以降低接入门槛,但不同服务商之间仍然会有参数、endpoint、错误结构和流式输出格式的差异。长期依赖模型名前缀判断,会让后续维护越来越被动。
第三,历史记录要提前考虑隐私边界。
默认保存历史很方便,但如果用户可能翻译敏感内容,最好一开始就支持“不保存历史”或者“隐私模式”。
第四,前端可以先轻,但状态边界不要太晚整理。
第一版用原生 JS 没问题。真正容易出问题的不是有没有框架,而是状态散在全局变量、DOM 和事件回调里。等到流式输出、卡片重试、收藏、标签这些功能加进来之后,状态边界会变得越来越重要。
第五,错误信息要尽量可排查。
多服务商工具里,配置阶段经常比翻译本身更容易出问题。API Key、Base URL、模型名、参数兼容性、限流、网络代理,都可能导致失败。
如果界面只显示“请求失败”,用户会很难判断下一步该改什么。
这些建议并不只针对 Kakapo。
只要是把本地桌面工具、模型服务和多平台能力放在一起,类似的问题基本都会遇到。
最后
Kakapo 解决的是一个很具体的问题:在本地桌面环境里,把多个 OpenAI 兼容模型组织成一个可以比较结果的翻译工作台。它不是为了替代 Mate、DeepL、Google Translate 这类成熟翻译产品,也不是完整的翻译管理系统。
它更像是一个从日常使用里长出来的小工具。当翻译内容主要来自复制粘贴,当结果不再只是“有没有译文”,而是“哪个模型的表达更合适”,这类工具就有了存在空间。
从实现上看,Kakapo 已经跑通了主链路:配置模型服务、保存 API Key、输入文本、并行请求多个模型、展示结果、回译、朗读和保存历史。
这些能力单独看都不复杂。真正有价值的是把它们放进一个本地桌面应用里,并且让这个应用可以继续被修改、被接入新的模型服务、被调整成更贴近自己习惯的工具。
当然,它当前还有不少边界问题。跨平台能力还不完整,历史记录没有加密,模型参数适配还比较依赖代码里的规则,流式输出和请求取消链路也还可以继续补。
但对当前阶段来说,Kakapo 已经完成了最初想解决的事情。它把散落在多个页面、多个模型和多个服务商之间的翻译动作收拢到一个地方,让我能更快地比较结果,并把选择权留在自己手里。
顺便也借这个项目验证了一遍 Wails v3、Go、Echo 和系统 WebView 这套组合。从这点看,它既是一个翻译工具,也是一篇桌面应用技术栈实践的代码注脚。
下一篇文章再见。
–EOF