这篇文章,我们继续聊聊,如何折腾 AI 应用,把不 AI 的东西,“AI 起来”。在不折腾复杂的检索系统的前提下,快速完成轻量的 RAG 实践。
写在前面
连续忙了两周后,脸皮终于架不住几位朋友的“提醒”,接下来先写两篇简单的实践:聊聊如何快速完成一个 AI 时代的 RAG 应用。
为了“拔掉之前承诺朋友的 Flags”,本文将展开聊聊以下内容:
- 快速将已有数据库、数据接口内容,通过 AI 的方式来进行输出。
- 快速搭建私有化的搜索引擎,并以最轻量化的方案运行,降低运行和维护成本。
- 如何制作一个 Dify RAG 应用,通过简单的接口拼接,而非复杂的 Prompt 流水线编排和精妙的 Prompt 编写(Prompt Tricks)。
- 如何在不折腾复杂的搜索引擎打分、召回的前提下,满足比较准的内容召回。
本文中使用的程序和配置,我开源在 soulteary/dify-with-classical-search,有需要可以自取,欢迎“一键三连”。
好啦,开始我们的实战吧。
准备工作
准备过程分为:准备 Docker 环境、启动 Dify 程序、启动 Meilisearch 搜索引擎,和准备搜索引擎要检索的数据。
本文的复现依旧很简单,如果你有 Docker 环境,将极大的减少不必要的折腾过程。
Docker 运行环境
想顺滑的完成实践,推荐你安装 Docker,不论你的设备是否有显卡,都可以根据自己的操作系统喜好,参考这两篇来完成基础环境的配置《基于 Docker 的深度学习环境:Windows 篇》、《基于 Docker 的深度学习环境:入门篇》。当然,使用 Docker 之后,你还可以做很多事情,比如:之前几十篇有关 Docker 的实践,在此就不赘述啦。
使用 Docker 快速启动 Dify 项目
你可以参考下面的内容来完成 Dify 项目的一键启动:
- 《使用 Dify 和 AWS Bedrock 玩转 Anthropic Claude 3》中的“快速完成 Dify 的配置和启动”。
- 《使用 Dify 和 Moonshot API 构建你的 AI 工作流(一):让不 AI 的应用 AI 化》中的 “优化后的 Dify Docker 配置”。
唯一需要注意的是,文章内容提到的 dify docker 配置中版本号,可以更新为 0.6.8 啦:
langgenius/dify-web:0.6.8langgenius/dify-api:0.6.8
使用 Docker 一键启动 Meilisearch 搜索引擎
Meilisearch 是一个轻量但功能强大的开源搜索引擎, 搜索即服务 Algolia 的开源平替。
如果你搜索的场景没有 TB 以上的数据,你完全可以使用它来替代使用 ELK(Elasticsearch, Kibana, Beats & Logstash)或者 EFK 技术栈中,复杂的技术架构,和极大的减少所需要运行搜索引擎而准备的计算和存储资源。
我们可以使用下面的配置,快速启动一个本地的搜索引擎(soulteary/dify-with-classical-search/meilisearch/docker-compose.yml):
name: meli
# https://www.meilisearch.com/docs/learn/configuration/instance_options
services:
meilisearch:
image: getmeili/meilisearch:v1.8.0
container_name: meilisearch
restart: always
ports:
- 7700:7700
volumes:
- ./meili_data:/meili_data
environment:
MEILI_MASTER_KEY: "soulteary"
MEILI_NO_ANALYTICS: "true"
MEILI_LOG_LEVEL: "info"
MEILI_MAX_INDEXING_MEMORY: "200 MB"
MEILI_MAX_INDEXING_THREADS: "2"
MEILI_HTTP_PAYLOAD_SIZE_LIMIT: "500 MB"
# MEILI_HTTP_ADDR: 0.0.0.0:7700
# MEILI_DB_PATH: /meili_data
在上面的配置中,我们定义了一个 API 鉴权密钥为 soulteary 的搜索引擎,它支持我们提交最大单个数据文件为 500MB,并使用双线程最多使用 200MB 内存来进行索引,当搜索引擎启动后,我们可以通过 http://localhost:7700 来访问服务。
将上面的配置保存为 docker-compose.yml,并根据自己的需求进行相应的调整,接着使用 docker compose up -d 启动服务,就完成了。
我们使用 docker logs meilisearch -f,能够看到服务的具体运行情况:
# docker logs meilisearch -f
888b d888 d8b 888 d8b 888
8888b d8888 Y8P 888 Y8P 888
88888b.d88888 888 888
888Y88888P888 .d88b. 888 888 888 .d8888b .d88b. 8888b. 888d888 .d8888b 88888b.
888 Y888P 888 d8P Y8b 888 888 888 88K d8P Y8b "88b 888P" d88P" 888 "88b
888 Y8P 888 88888888 888 888 888 "Y8888b. 88888888 .d888888 888 888 888 888
888 " 888 Y8b. 888 888 888 X88 Y8b. 888 888 888 Y88b. 888 888
888 888 "Y8888 888 888 888 88888P' "Y8888 "Y888888 888 "Y8888P 888 888
Config file path: "none"
Database path: "./data.ms"
Server listening on: "http://0.0.0.0:7700"
Environment: "development"
Commit SHA: "c668043c4f4d2616cc5dee1598742c3f87303bfb"
Commit date: "2024-05-02T14:55:32Z"
Package version: "1.8.0"
Anonymous telemetry: "Disabled"
A master key has been set. Requests to Meilisearch won't be authorized unless you provide an authentication key.
Meilisearch started with a master key considered unsafe for use in a production environment.
A master key of at least 16 bytes will be required when switching to a production environment.
We generated a new secure master key for you (you can safely use this token):
>> --master-key Pbnpc8A0IBVqDmLghU0Yj3KvZRgjBbZXNJSeDBhmdAk <<
Restart Meilisearch with the argument above to use this new and secure master key.
Check out Meilisearch Cloud! https://www.meilisearch.com/cloud?utm_campaign=oss&utm_source=engine&utm_medium=cli
Documentation: https://www.meilisearch.com/docs
Source code: https://github.com/meilisearch/meilisearch
Discord: https://discord.meilisearch.com
2024-05-20T06:42:22.290321Z INFO actix_server::builder: starting 8 workers
2024-05-20T06:42:22.290339Z INFO actix_server::server: Actix runtime found; starting in Actix runtime
2024-05-20T06:42:31.820935Z INFO HTTP request{method=POST host="127.0.0.1:7700" route=/indexes/movies/documents query_parameters= user_agent=Meilisearch Go (v0.26.3) status_code=202}: meilisearch: close time.busy=13.3ms time.idle=327ms
2024-05-20T06:42:31.824691Z INFO milli::update::index_documents::enrich: Primary key was not specified in index. Inferred to 'id'
2024-05-20T06:42:35.533861Z INFO index_scheduler::batch: document indexing done indexing_result=DocumentAdditionResult { indexed_documents: 15309, number_of_documents: 15309 }
2024-05-20T06:42:35.700474Z INFO index_scheduler: A batch of tasks was successfully completed with 1 successful tasks and 0 failed tasks.
准备 AI 模型服务
这里你可以选择参考之前的博客内容,自己搭建一个模型服务,并将 API 接入 Dify 使用。也可以选择更简单易一些,在你能够轻松获取的大模型服务中选择一家的大模型 API 使用。
我个人推荐最近刚刚更新了大参数量版本的,使用成本低、效果还不错的零一万物 yi-medium 或 yi-large,你可以在这里申请 API Keys。
如果你有其他家模型服务,并且可以有免费使用额度,也可以根据自己情况进行效果验证和替换。
一般情况,只有两点需要注意:
- 你搜索回来的数据内容,加上模型要生成的内容长度之和,在你选择的模型上下文长度支持范围内。
- 选择的模型要对你提供的语言内容有理解和生成能力,比如你要双语输入或输出,就不要选择单语言模型或者某一个语言输出能力很糟糕的模型。
准备搜索引擎数据
为了让你更快的上手,并加速搜索引擎的索引构建过程,我对官方提供的搜索数据示例(电影数据库)进行了精简,你可以在 soulteary/dify-with-classical-search/meilisearch/data/movies.json 下载到不到 10MB 大小的数据集,包含了 1 万 5000 千部电影简介。
数据样本类似下面这样:
{
"id": 10515,
"title": "Castle in the Sky",
"overview": "A young boy and a girl with a magic crystal must race against pirates and foreign agents in a search for a legendary floating castle.",
"genres": ["Adventure", "Fantasy", "Animation", "Action", "Family", "Romance"],
"poster": "https://image.tmdb.org/t/p/w500/npOnzAbLh6VOIu3naU5QaEcTepo.jpg",
"release_date": 523324800
}
你可以根据你的实际需求来调整数据字段(增加、减少),不论你如何配置你的数据字段,搜索引擎都能够完成数据检索。
将数据下载到本地,我们稍后使用。
步骤一:让搜索引擎完成数据索引
为了让服务稳定、高效(跑的快,用的资源少),我选择使用 Golang 来编写“胶水程序”。
如果你喜欢其他的语言,可以参考本文用你喜欢的语言来实现逻辑。
我们可以使用下面的 50 行左右的代码,来完成将上文中的 JSON 数据,灌入搜索引擎的工作。完整的代码在 soulteary/dify-with-classical-search/meilisearch/main.go:
package main
import (
"encoding/json"
"fmt"
"os"
"github.com/meilisearch/meilisearch-go"
)
type Movie struct {
ID int `json:"id"`
Title string `json:"title"`
Overview string `json:"overview"`
Genres []string `json:"genres"`
Poster string `json:"poster"`
ReleaseDate int `json:"release_date"`
}
func main() {
client := meilisearch.NewClient(meilisearch.ClientConfig{
Host: "http://127.0.0.1:7700",
APIKey: "soulteary",
})
// 创建一个名为 'movies' 的索引,用来存储后续的数据
index := client.Index("movies")
// 如果索引 'movies' 不存在,Meilisearch 会在第一次添加文档时创建它
// documents := []map[string]interface{}{
// {"id": 1, "title": "Carol", "genres": []string{"Romance", "Drama"}},
// {"id": 2, "title": "Wonder Woman", "genres": []string{"Action", "Adventure"}},
// {"id": 3, "title": "Life of Pi", "genres": []string{"Adventure", "Drama"}},
// }
buf, err := os.ReadFile("data/movies.json")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
var documents []Movie
err = json.Unmarshal(buf, &documents)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
task, err := index.AddDocuments(documents)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(task.TaskUID)
}
当我们使用 go run main.go 运行程序的时候,一切顺利,将得到一个包含了正在执行的索引任务的数字 ID 结果:
# go run main.go
0
如果此时我们在观察日志,将能够看到搜索引擎一秒就完成了这个数据的索引工作:
2024-05-20T06:30:40.771571Z INFO HTTP request{method=POST host="127.0.0.1:7700" route=/indexes/movies/documents query_parameters= user_agent=Meilisearch Go (v0.26.3) status_code=202}: meilisearch: close time.busy=3.46ms time.idle=4.30ms
2024-05-20T06:30:40.776351Z INFO milli::update::index_documents::enrich: Primary key was not specified in index. Inferred to 'id'
2024-05-20T06:30:40.807314Z INFO index_scheduler::batch: document indexing done indexing_result=DocumentAdditionResult { indexed_documents: 1, number_of_documents: 1 }
2024-05-20T06:30:40.809256Z INFO index_scheduler: A batch of tasks was successfully completed with 1 successful tasks and 0 failed tasks.
这时,如果我们访问 http://localhost:7700 将能够访问到搜索引擎自带的调试界面。通过这个界面,我们就能够对我们已索引的内容进行搜索调试啦。
输入我们的鉴权密钥,能够进入默人的检索页面。
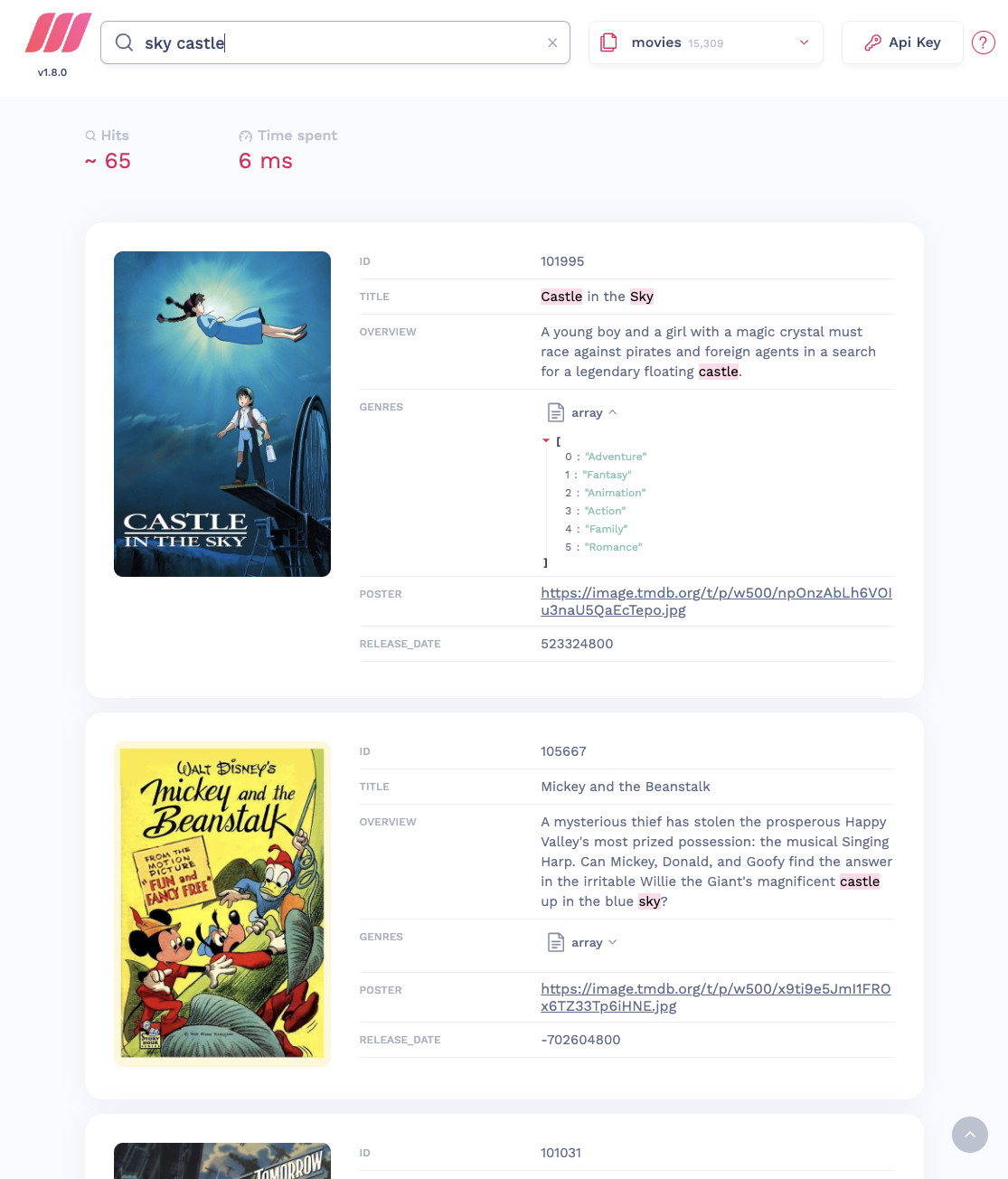
搜索引擎支持我们搜索多个词语。
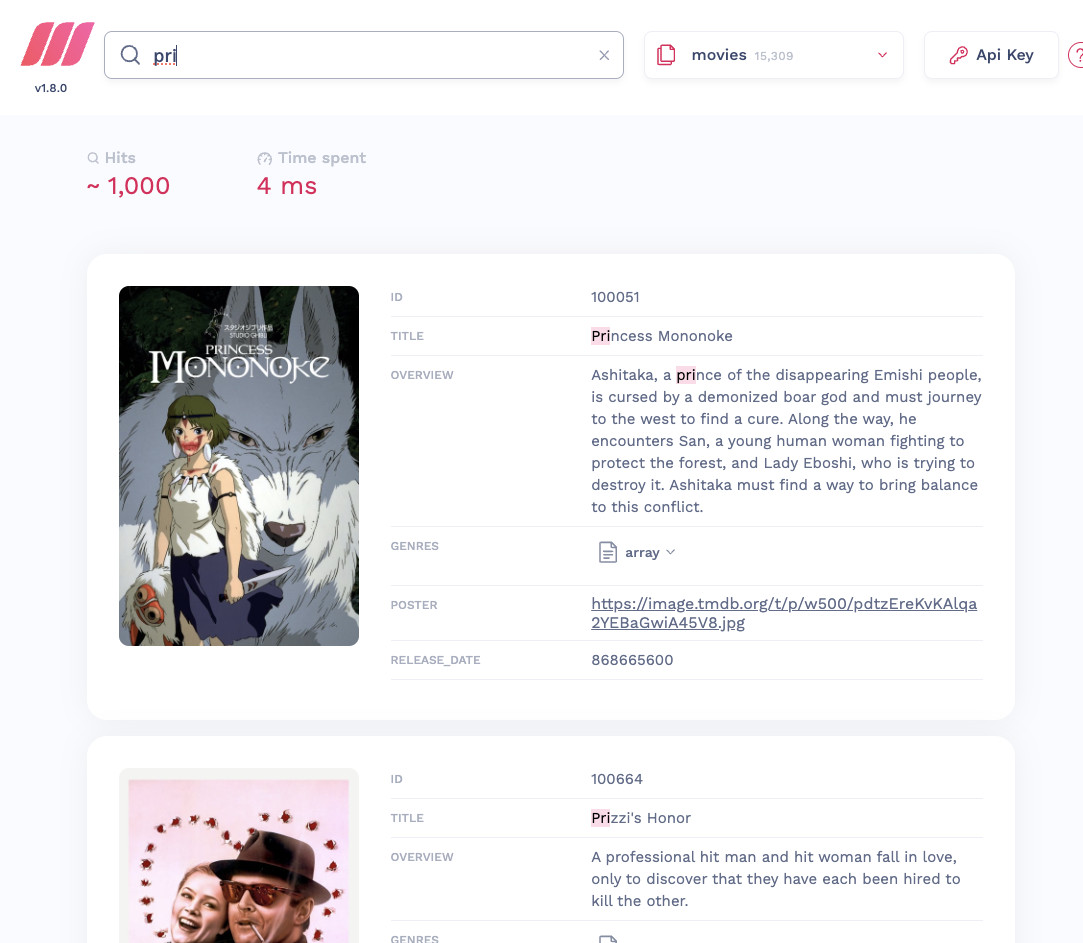
当然,也能够搜索单个关键词或部分关键词。
自定义搜索引擎前端界面
如果你想得到一个类似 Google 或者 Baidu 的搜索引擎界面,我们可以通过 MeiliSearch 的接口和 Algolia 推出的 instantsearch 开源项目中的模版。
当然,你也可以在官方项目(官方示例、官方文档、官方文章)中,找到适合 Strapi、FireStore、Gatsby、以及通用的 React 和 VUE 相关的实现。
我实现了一段大概 50 行的前端程序,你可以将下面的内容保存为 index.html(原始内容在 soulteary/dify-with-classical-search/meilisearch/index.html):
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@meilisearch/instant-meilisearch/templates/basic_search.css" />
<style>
.hit-name {
font-size: 1.2em;
font-weight: bold;
}
.hit-content {
font-size: 0.8em;
}
</style>
</head>
<body>
<div class="wrapper">
<div id="searchbox" focus></div>
<div id="hits"></div>
</div>
</body>
<script src="https://cdn.jsdelivr.net/npm/@meilisearch/instant-meilisearch/dist/instant-meilisearch.umd.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/instantsearch.js@4"></script>
<script>
const search = instantsearch({
indexName: "movies",
searchClient: instantMeiliSearch("http://localhost:7700", "soulteary").searchClient,
});
search.addWidgets([
instantsearch.widgets.searchBox({
container: "#searchbox",
}),
instantsearch.widgets.configure({ hitsPerPage: 8 }),
instantsearch.widgets.hits({
container: "#hits",
templates: {
item: `
<div>
<div class="hit-name">
{{#helpers.highlight}}{ "attribute": "title" }{{/helpers.highlight}}
</div>
<div class="hit-content">
{{#helpers.highlight}}{ "attribute": "overview" }{{/helpers.highlight}}
</div>
</div>
`,
},
}),
]);
search.start();
</script>
</html>
如果你使用浏览器打开这个文件,将能够看到下面的界面:
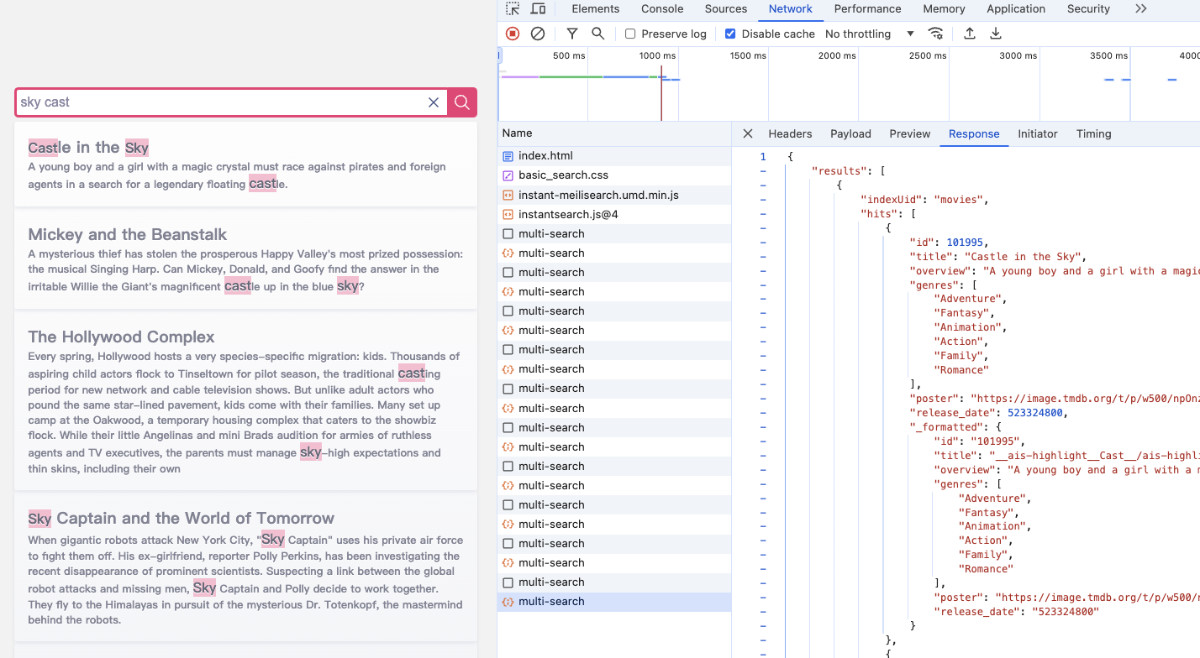
如果我们打开调试工具,将能够看到我们的页面是如何和搜索引擎交互的。简化其中的调用请求,我们将得到一个最简单的请求调用方法:
curl 'http://localhost:7700/multi-search' \
-H 'Authorization: Bearer soulteary' \
-H 'Content-Type: application/json' \
--data-raw '{"queries":[{"indexUid":"movies","q":"sky","limit":3,"offset":0}]}'
上面的脚本程序使用 curl 来访问浏览器,并使用 sky 关键词进行搜索,得到最符合搜索结果的三个内容。
{"results":[{"indexUid":"movies","hits":[{"id":101031,"title":"Sky Captain and the World of Tomorrow","overview":"When gigantic robots attack New York City, \"Sky Captain\" uses his private air force to fight them off. His ex-girlfriend, reporter Polly Perkins, has been investigating the recent disappearance of prominent scientists. Suspecting a link between the global robot attacks and missing men, Sky Captain and Polly decide to work together. They fly to the Himalayas in pursuit of the mysterious Dr. Totenkopf, the mastermind behind the robots.","genres":["Mystery","Action","Thriller","Science Fiction","Adventure"],"poster":"https://image.tmdb.org/t/p/w500/ceW9Zi43hEQPdxkPkohVCcG1CuT.jpg","release_date":1095379200},{"id":102112,"title":"Sky Fighters","overview":"Les Chevaliers du ciel (English: Sky Fighters) is a 2005 French film directed by Gérard Pirès about two air force pilots preventing a terrorist attack on the Bastille Day celebrations in Paris. It is based on Tanguy et Laverdure, a comics series by Jean-Michel Charlier and Albert Uderzo – of Astérix fame, which was also made into a hugely successful TV series from 1967 to 1969 making Tanguy and Laverdure, the two main heroes, part of popular Francophone culture.","genres":["Action","Adventure"],"poster":"https://image.tmdb.org/t/p/w500/fXyIF7W059RtNwSZViVUR9bUXWX.jpg","release_date":1129334400},{"id":102368,"title":"Sky High","overview":"Set in a world where superheroes are commonly known and accepted, young Will Stronghold, the son of the Commander and Jetstream, tries to find a balance between being a normal teenager and an extraordinary being.","genres":["Adventure","Comedy","Family"],"poster":"https://image.tmdb.org/t/p/w500/yk51E2OxA9zUdRqK0YvPTx6lfa7.jpg","release_date":1122595200}],"query":"sky","processingTimeMs":4,"limit":3,"offset":0,"estimatedTotalHits":113}]}
如果你不需要 “AI 之外的访问方式”,那么只需要记住上面的使用 API 调用搜索引擎的方法和搜索引擎返回的接口结果格式即可。
步骤二:实现一个简单的接口
除了上一篇文章《使用 Dify 和 Moonshot API 做一个懒人 AI 阅读工具(二):轻量 RAG 应用》中提到的,借用“内容审查”扩展接口,来完成 AI 生成使用的资料扩展外。
在 Dify 的官方文档中,我们还能够找到一个有趣的接口:外部 API 扩展。根据文档,我们可以简单的使用下面不到 50 行的代码,来完成一个 Dify 能够调用的外部接口的“框架”:
// base on: https://github.com/soulteary/dify-simple-rag-with-wp/blob/main/main.go
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
type ExtensionPointRequest struct {
Point string `json:"point"`
Params struct {
AppID string `json:"app_id"`
ToolVariable string `json:"tool_variable"`
Inputs map[string]interface{} `json:"inputs"`
Query string `json:"query"`
} `json:"params"`
}
type ExtensionPointResponse struct {
Result string `json:"result"`
}
func main() {
router := gin.Default()
router.POST("/new-api-for-dify", func(c *gin.Context) {
var req ExtensionPointRequest
if err := c.BindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
if req.Point == "ping" {
c.JSON(http.StatusOK, ExtensionPointResponse{Result: "pong"})
return
}
c.JSON(http.StatusOK, ExtensionPointResponse{Result: "data processed successfully"})
})
router.Run(":8084")
}
将上面的内容保存为 main.go,我们就有了一个运行在本地 8084 端口,支持 POST 请求的接口 /new-api-for-dify 接口。
当 Dify 程序对我们的接口发送 ping 请求进行健康检查的时候,我们的程序将自信的告诉 Dify:Pong,从而迅速完成接口的可用性检查。
使用 go run main.go 运行程序,然后开始配置 Dify 中的外部数据接口。
步骤三:在 Dify 中配置外部数据接口
打开 Dify,然后在右上角用户图标的下拉菜单中选择“设置”选项。
在打开的弹出窗口中选择“新增 API 扩展”。
在新的弹出窗口中填入我们上面完成的 “API 框架” 的基础信息,你可以根据你的需求来,我这里就起名为“电影检索”啦。
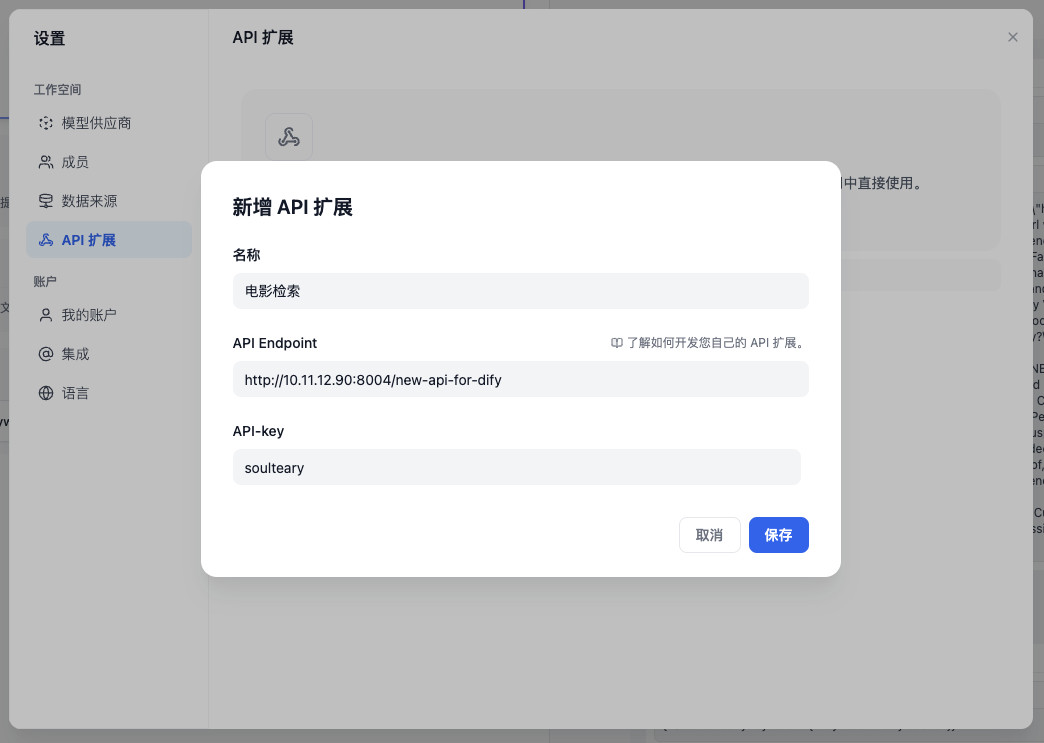
点击保存,如果一切顺利,你的 Dify 界面中将出现我们自定义的 API,让 Dify 访问我们自定义的 API 就完成啦。
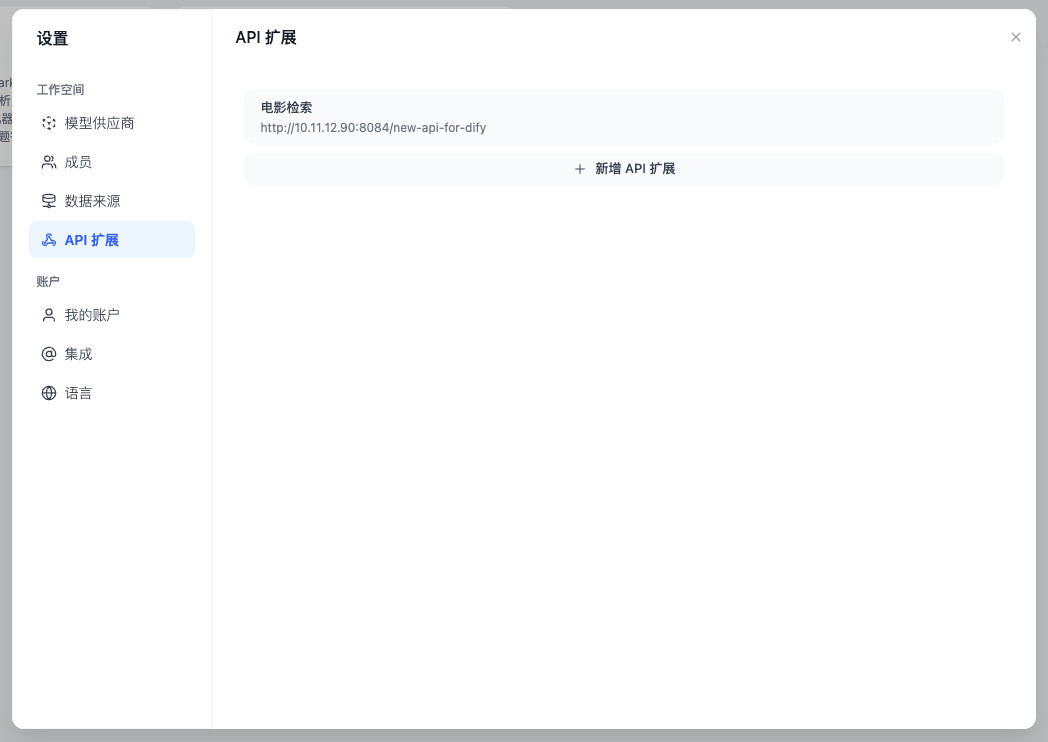
步骤四:创建调用外部数据 API 的 AI 应用
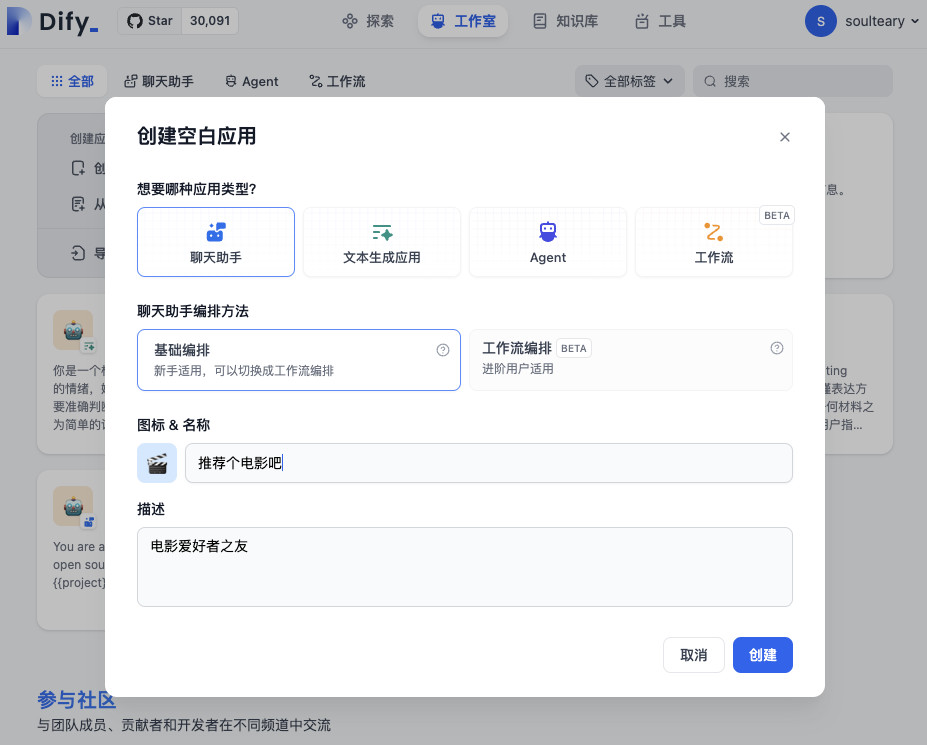
返回 Dify 的首页,选择 “创建空白应用”,根据你的喜好给应用起个名字,选个图标。
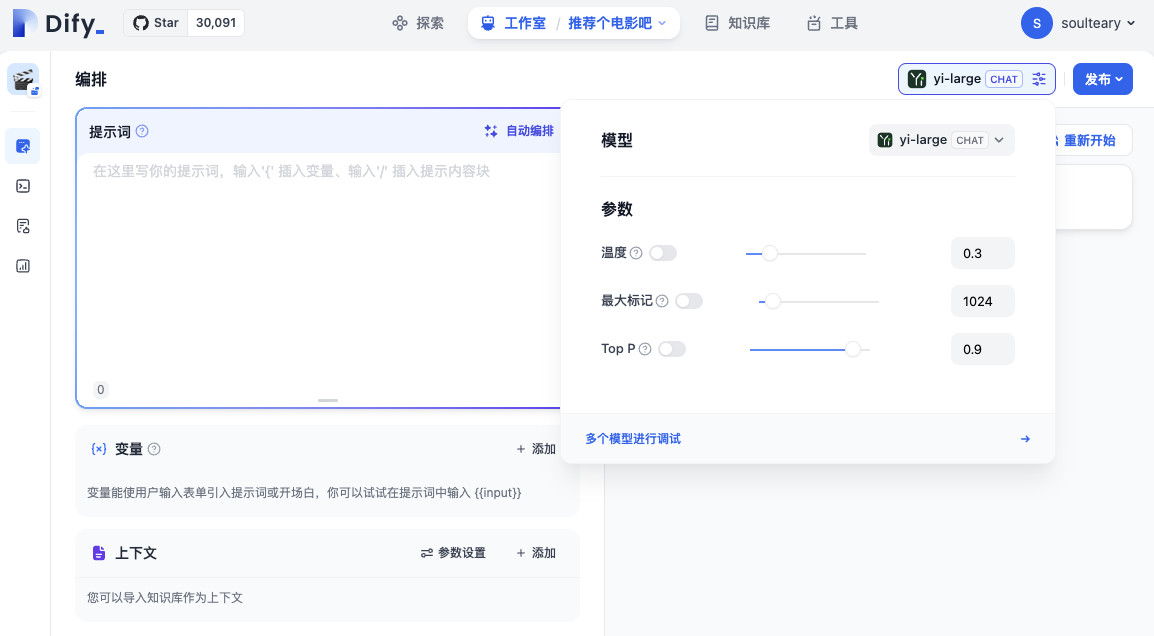
接着,在新应用的界面中,根据自己的具体情况更新模型参数。这里我们希望模型有一定的“自由发挥空间”,所以将温度设置为了 0.3,如果你希望模型能够多说一些,那么可以适当将“最大标记”调整到更高的数值。
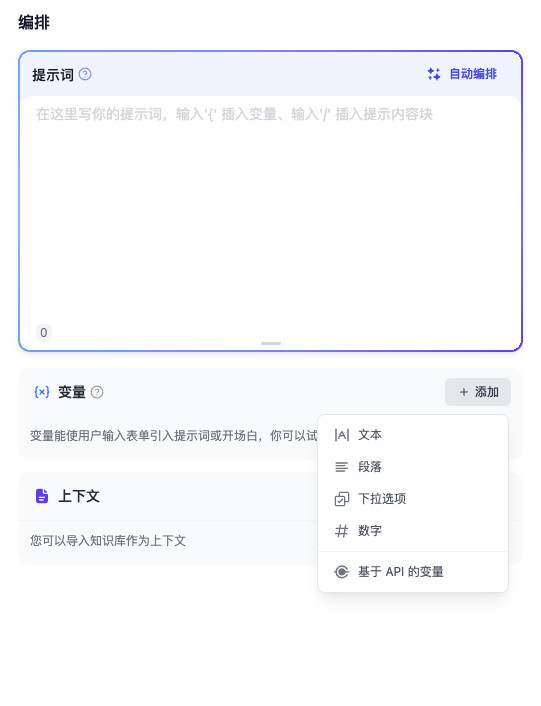
然后,我们点击“变量”模块的“添加”按钮,在下拉菜单中选择“基于 API 的变量”。
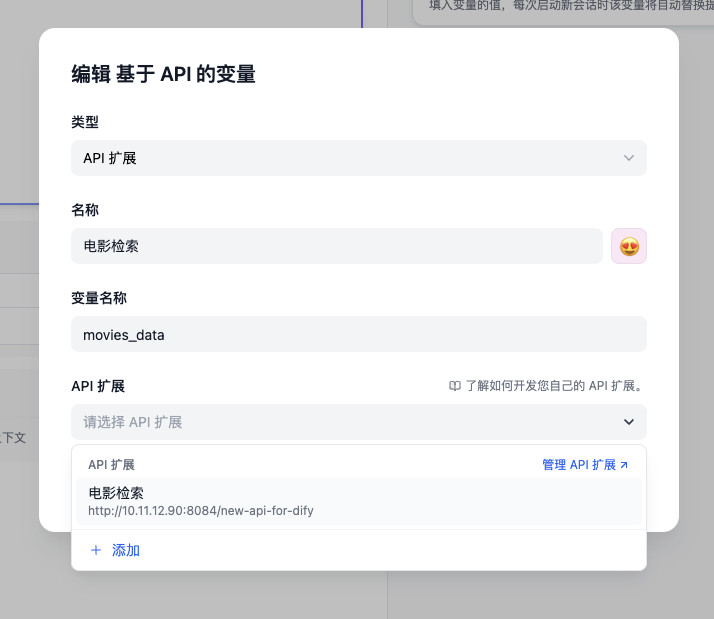
在新弹出的窗口中,完成“基于 API 的变量”的配置。

当我们配置完毕,就能够在编写 Prompt 的时候,调用这个 API 变量啦。
如果我们想在请求中调用外部 API 数据(搜索引擎结果),可以编写一个类似下面的简单的 Prompt:
你是一个资深的电影影评人,擅长根据“参考信息”来生成充满趣味性的回答,始终使用中文输出内容。
## 参考信息
{{movies_data}}
## 最终输出
因为我们一般会使用关键词来减少搜索引擎的数据查找范围,来更快的获取更准确的信息,所以我们可以再创建一个新的变量,来传递给搜索引擎 API。
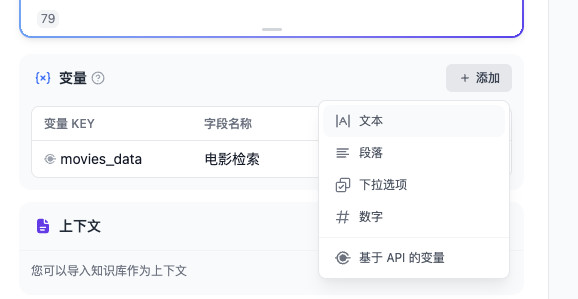
还是在“变量”模块选择“添加”,这次添加一个“文本变量”即可。
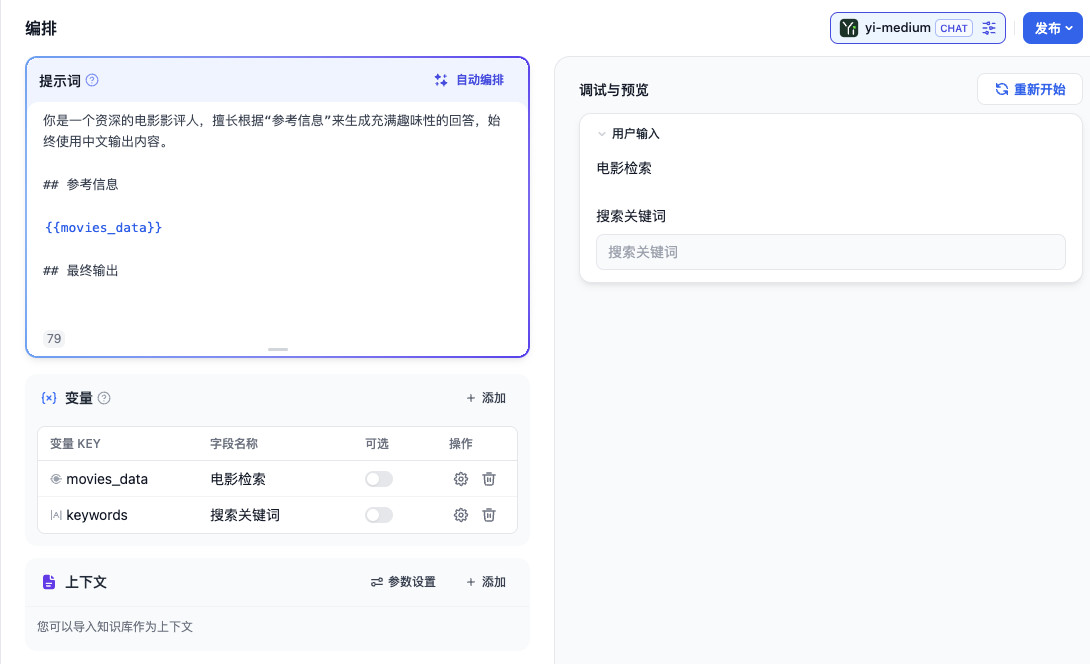
变量添加完毕,我们就能够在对话的过程中,在界面中预先定义要搜索的内容是什么了,这个变量不需要在 Prompt 中体现,所以我们不需要修改 Prompt 的内容。
接下来,我们来完善步骤二的接口,“让程序 AI 起来”。
步骤五:完成 AI 接口,让程序 AI 起来
首先,我们可以在步骤二中的程序中添加两行代码,来将我们的 API 程序接收到的来自 Dify 的请求都打印出来,帮助我们更快的完成 API 接口的最终实现。
router.POST("/new-api-for-dify", func(c *gin.Context) {
var req ExtensionPointRequest
if err := c.BindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
if req.Point == "ping" {
c.JSON(http.StatusOK, ExtensionPointResponse{Result: "pong"})
return
}
// 打印请求信息
dump, _ := json.Marshal(req)
fmt.Println(string(dump))
c.JSON(http.StatusOK, ExtensionPointResponse{Result: "data processed successfully"})
})
完成代码修改后,我们使用 go run main.go 重新启动程序,然后在 Dify 中随便搜索一个关键词(我使用的是 sky),然后对 AI 提问:“为什么推荐这几部电影?”
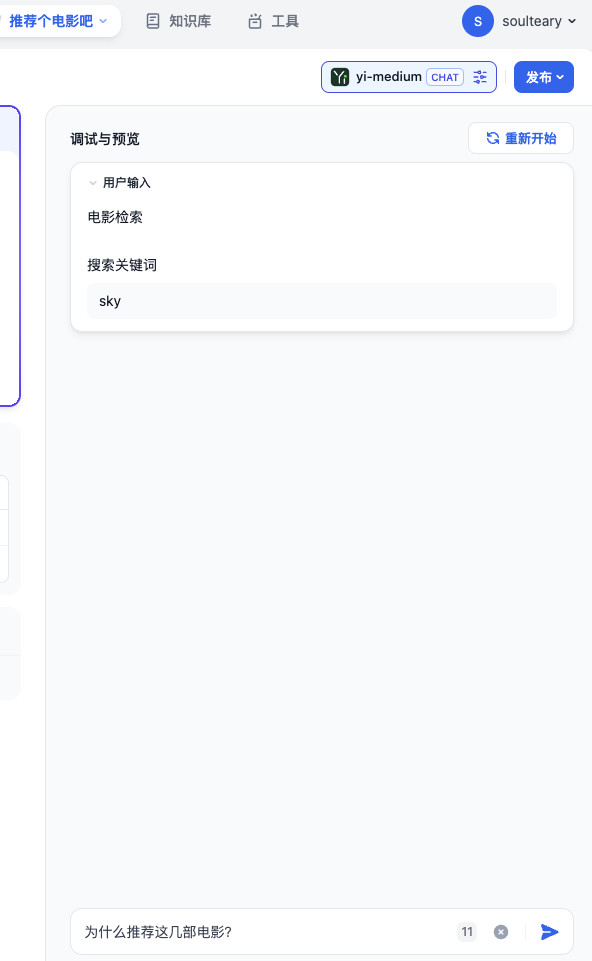
虽然我们已经将我们的 API 服务和 Dify 连接了起来,但是目前 API 服务和搜索引擎还没有连接起来,所以我们可以忽略这个时候的模型回答。只关注 API 服务的日志信息:
{"point":"app.external_data_tool.query","params":{"app_id":"55f2f15b-3731-494b-b034-240cd169d0cb","tool_variable":"movies_data","inputs":{"keywords":"sky"},"query":"为什么推荐这几部电影?"}}
[GIN] 2024/05/20 - 21:56:17 | 200 | 1.08275ms | 10.11.12.90 | POST "/new-api-for-dify"
从 API 的请求日志中,我们能够看到 Dify 使用外部数据 API 的参数请求详情:
{"point":"app.external_data_tool.query","params":{"app_id":"55f2f15b-3731-494b-b034-240cd169d0cb","tool_variable":"movies_data","inputs":{"keywords":"sky"},"query":"为什么推荐这几部电影?"}}
有了上面的请求数据示例,我们只需要在程序里添加几个判断,就能够将 Dify 的请求参数 sky 传递给我们的搜索引擎了。
// ...
if req.Point == "ping" {
c.JSON(http.StatusOK, ExtensionPointResponse{Result: "pong"})
return
}
// 之前的代码
if req.Point != "app.external_data_tool.query" {
c.JSON(http.StatusBadRequest, gin.H{"error": "invalid point"})
return
}
keywords, exist := req.Params.Inputs["keywords"]
if !exist {
c.JSON(http.StatusBadRequest, gin.H{"error": "missing keyword"})
return
}
s := strings.TrimSpace(fmt.Sprintf("%s", keywords))
if s == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "empty keyword"})
return
}
movies, err := GetSearchResult(s, 3, "movies", 0, "soulteary")
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
在完成了用户查询内容的向后传递后,我们来实现 API 服务和搜索引擎的“联动”。在步骤一的“自定义搜索引擎前端界面”中,我们得到了如何使用接口来请求搜索引擎的示例,结合请求的数据结构和接口返回的数据结构,很简单就可以写出类似下面的代码定义(如果你不会,可以让模型来帮你写):
type QueryPayload struct {
Queries []QueryBody `json:"queries"`
}
type QueryBody struct {
IndexUID string `json:"indexUid"`
Q string `json:"q"`
Limit int `json:"limit"`
Offset int `json:"offset"`
}
type SearchResults struct {
Results []SearchResult `json:"results"`
}
type SearchResult struct {
IndexUID string `json:"indexUid"`
Hits []struct {
ID int `json:"id"`
Title string `json:"title"`
Overview string `json:"overview"`
Genres []string `json:"genres"`
Poster string `json:"poster"`
ReleaseDate int `json:"release_date"`
} `json:"hits"`
Query string `json:"query"`
ProcessingTimeMs int `json:"processingTimeMs"`
Limit int `json:"limit"`
Offset int `json:"offset"`
EstimatedTotalHits int `json:"estimatedTotalHits"`
}
func GetSearchResult(search string, count int, indexes string, page int, token string) (result SearchResults, err error) {
client := &http.Client{}
var queryBody QueryBody
queryBody.IndexUID = indexes
queryBody.Q = search
queryBody.Limit = count
queryBody.Offset = page
var queryPayload QueryPayload
queryPayload.Queries = append(queryPayload.Queries, queryBody)
payload, err := json.Marshal(queryPayload)
if err != nil {
return result, err
}
var data = strings.NewReader(string(payload))
req, err := http.NewRequest("POST", "http://localhost:7700/multi-search", data)
if err != nil {
return result, err
}
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", token))
req.Header.Set("Content-Type", "application/json")
resp, err := client.Do(req)
if err != nil {
return result, err
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
return result, err
}
err = json.Unmarshal(bodyText, &result)
if err != nil {
return result, err
}
return result, nil
}
在上面定义的 GetSearchResult 函数中,从左到右的参数含义分别是:
- 从 Dify 获取到的用户搜索关键词
- 预设只获取三条搜索结果
- 只获取第一页的搜索结果
- 调用搜素引擎的 Token 为
soulteary
好了,当我们完成了上面的核心接口内容后,只需要最后完成数据拼合操作,将搜索结果使用指定数据结构返给 Dify,所有的工作就都完成啦。
movies, err := GetSearchResult(s, 3, "movies", 0, "soulteary")
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
// 之前的代码
var result string
for _, movie := range movies.Results {
for _, hit := range movie.Hits {
result += fmt.Sprintf("- 标题:%s\n", hit.Title)
result += fmt.Sprintf("- 简介:%s\n\n", hit.Overview)
}
}
c.JSON(http.StatusOK, ExtensionPointResponse{Result: result})
我们将获取到的三条数据结果,使用 Markdown 列表方式拼合,你也可以使用你喜欢的格式,对于不同模型来说,会有不同的效果,需要耐心试验。
完整代码实现
上面内容的完整代码可以在开源仓库中找到(soulteary/dify-with-classical-search/dify/main.go),算上空行大概 150 行左右,是不是非常简单:
// base on: https://github.com/soulteary/dify-simple-rag-with-wp/blob/main/main.go
package main
import (
"encoding/json"
"fmt"
"io"
"net/http"
"strings"
"github.com/gin-gonic/gin"
)
type QueryPayload struct {
Queries []QueryBody `json:"queries"`
}
type QueryBody struct {
IndexUID string `json:"indexUid"`
Q string `json:"q"`
Limit int `json:"limit"`
Offset int `json:"offset"`
}
type SearchResults struct {
Results []SearchResult `json:"results"`
}
type SearchResult struct {
IndexUID string `json:"indexUid"`
Hits []struct {
ID int `json:"id"`
Title string `json:"title"`
Overview string `json:"overview"`
Genres []string `json:"genres"`
Poster string `json:"poster"`
ReleaseDate int `json:"release_date"`
} `json:"hits"`
Query string `json:"query"`
ProcessingTimeMs int `json:"processingTimeMs"`
Limit int `json:"limit"`
Offset int `json:"offset"`
EstimatedTotalHits int `json:"estimatedTotalHits"`
}
func GetSearchResult(search string, count int, indexes string, page int, token string) (result SearchResults, err error) {
client := &http.Client{}
var queryBody QueryBody
queryBody.IndexUID = indexes
queryBody.Q = search
queryBody.Limit = count
queryBody.Offset = page
var queryPayload QueryPayload
queryPayload.Queries = append(queryPayload.Queries, queryBody)
payload, err := json.Marshal(queryPayload)
if err != nil {
return result, err
}
var data = strings.NewReader(string(payload))
req, err := http.NewRequest("POST", "http://localhost:7700/multi-search", data)
if err != nil {
return result, err
}
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", token))
req.Header.Set("Content-Type", "application/json")
resp, err := client.Do(req)
if err != nil {
return result, err
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
return result, err
}
err = json.Unmarshal(bodyText, &result)
if err != nil {
return result, err
}
return result, nil
}
type ExtensionPointRequest struct {
Point string `json:"point"`
Params struct {
AppID string `json:"app_id"`
ToolVariable string `json:"tool_variable"`
Inputs map[string]interface{} `json:"inputs"`
Query string `json:"query"`
} `json:"params"`
}
type ExtensionPointResponse struct {
Result string `json:"result"`
}
func main() {
router := gin.Default()
router.POST("/new-api-for-dify", func(c *gin.Context) {
var req ExtensionPointRequest
if err := c.BindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
if req.Point == "ping" {
c.JSON(http.StatusOK, ExtensionPointResponse{Result: "pong"})
return
}
if req.Point != "app.external_data_tool.query" {
c.JSON(http.StatusBadRequest, gin.H{"error": "invalid point"})
return
}
keywords, exist := req.Params.Inputs["keywords"]
if !exist {
c.JSON(http.StatusBadRequest, gin.H{"error": "missing keyword"})
return
}
s := strings.TrimSpace(fmt.Sprintf("%s", keywords))
if s == "" {
c.JSON(http.StatusBadRequest, gin.H{"error": "empty keyword"})
return
}
movies, err := GetSearchResult(s, 3, "movies", 0, "soulteary")
if err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
var result string
for _, movie := range movies.Results {
for _, hit := range movie.Hits {
result += fmt.Sprintf("- 标题:%s\n", hit.Title)
result += fmt.Sprintf("- 简介:%s\n\n", hit.Overview)
}
}
c.JSON(http.StatusOK, ExtensionPointResponse{Result: result})
})
router.Run(":8084")
}
验证程序
好了,一切就绪,让我们来重新使用这个 AI 应用。再次在关键词中搜索“sky”,并问模型应用“为什么推荐这几部电影”。
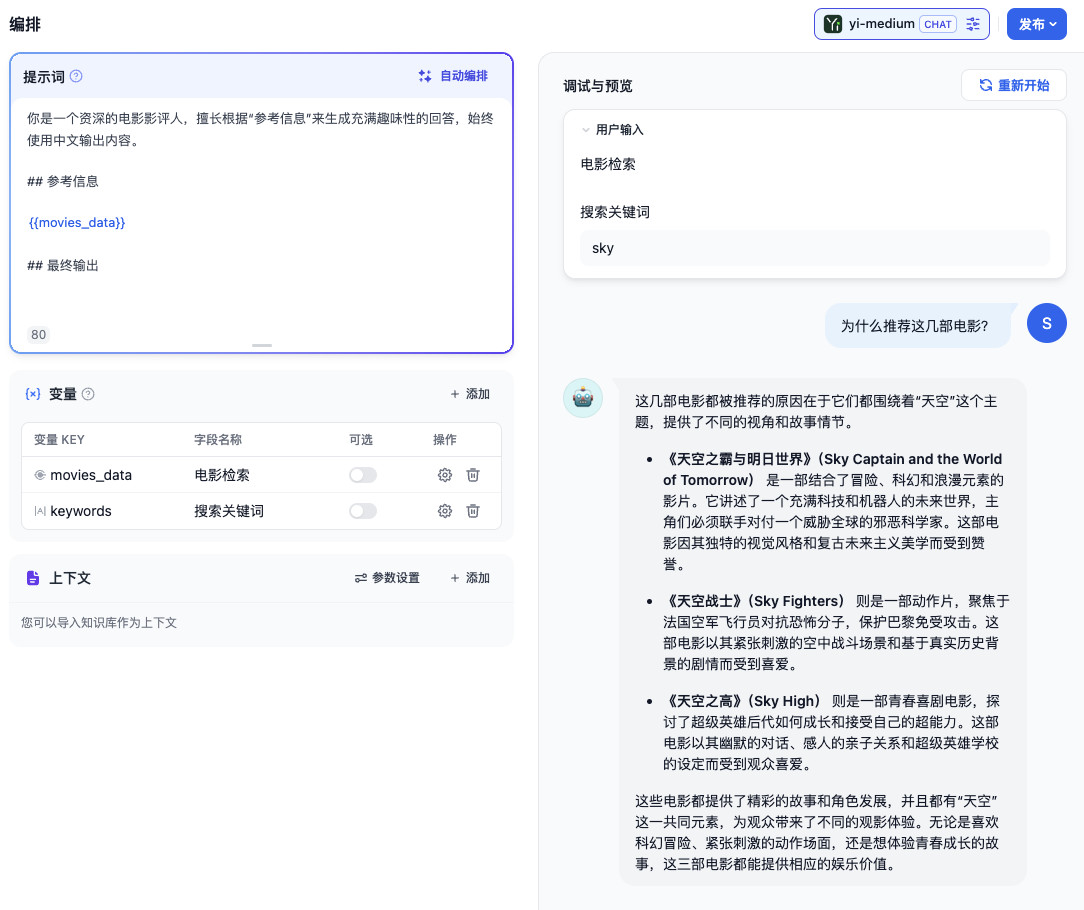
模型会将搜索引擎中得到的前三条电影填充到 Prompt 中,并提交到模型服务中,进行结果推理。因为设置了 Prompt 始终使用中文输出,所以即便是搜索引擎搜索回的内容都是英文数据,也还是被翻译为了不错的中文结果。
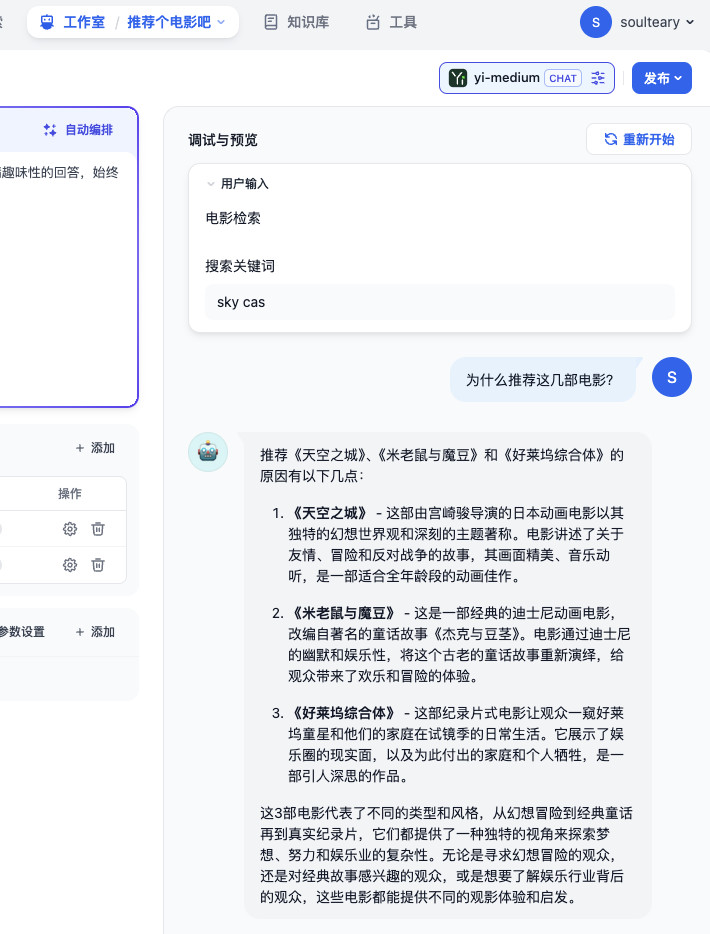
让我们来验证下多个关键词的检索能力,修改搜索关键词为“sky cas”(我只拼了一部分的“城堡”单词),然后重新提问。
稍等片刻,我们能够看到,模型应用在后台更新了搜索词,输出了包含天空之城在内的新的搜索结果的答案,并给出了一段还可以的总结。
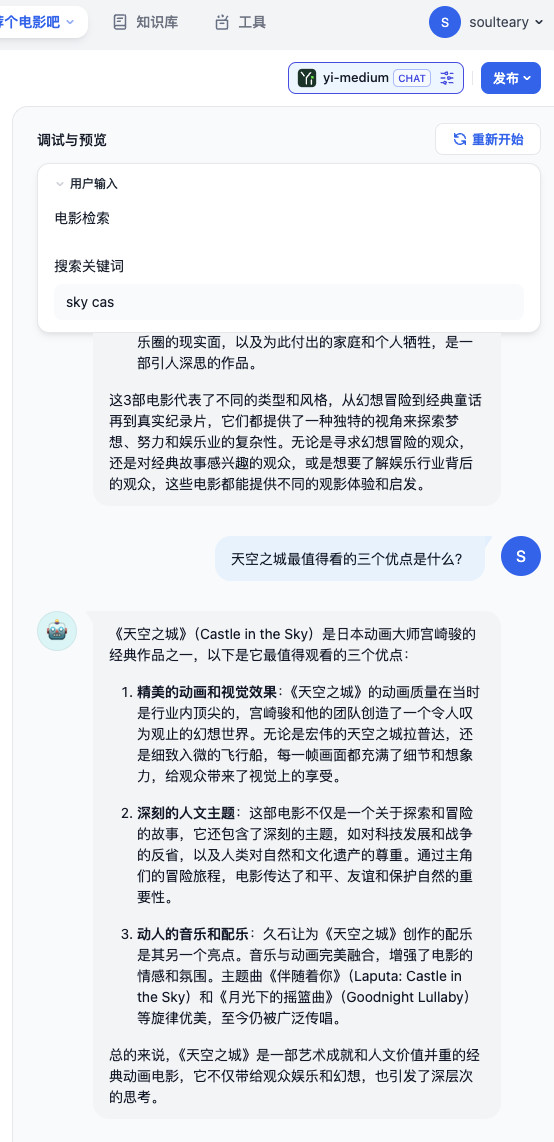
因为我们创建的是一个 Dify 聊天应用,所以我们可以对模型进行追问,来了解自己更想了解的内容。相比完全让模型“抹黑”生成内容,在提供了必要的准确上下文后,模型的输出结果明显更靠谱了,对吧?
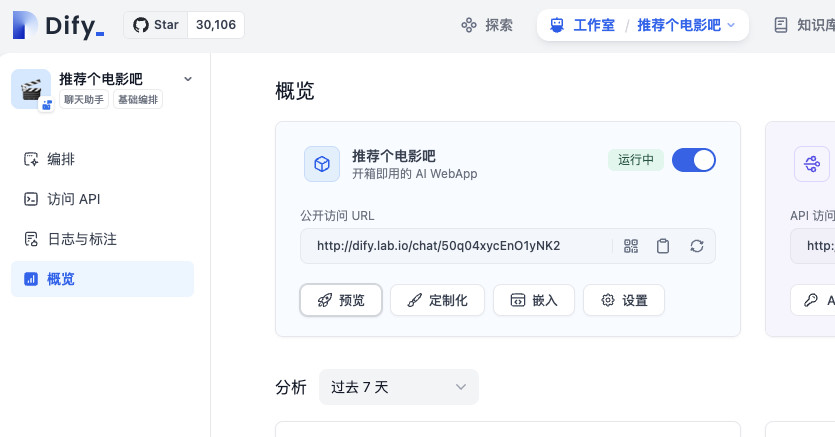
到这里,我们就完成了整个 AI 应用的基础搭建,你可以根据你自己的具体情况来做进一步的优化和完善。
访问构建好的 AI Chat 应用
当我们完成了应用调整后,访问这个 AI 应用的“概览页面”,找到模型应用的“预览”按钮。点击它,浏览器将打开一个新窗口,在这个新窗口中,我们能够访问我们配置好的 Chat 应用。
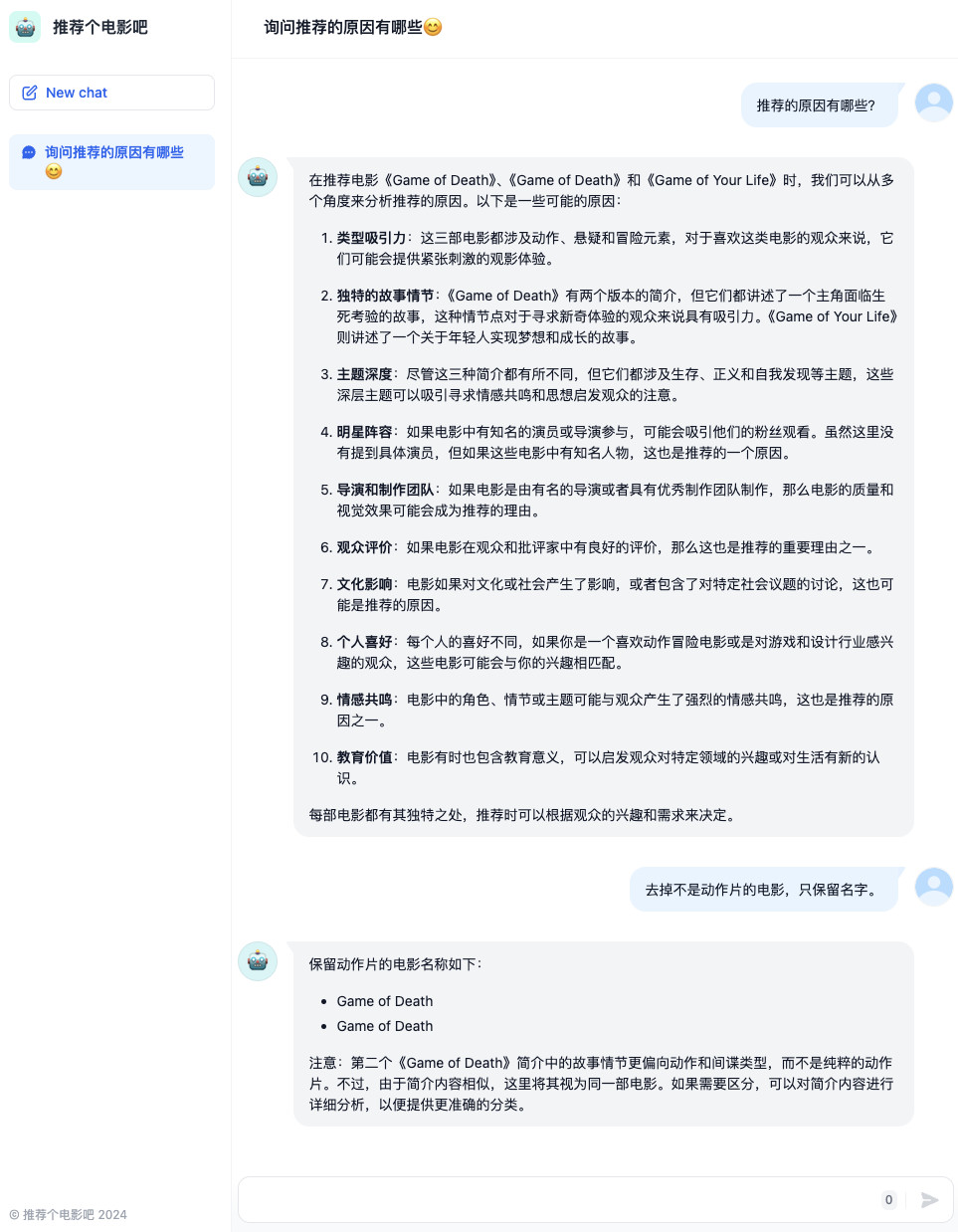
在这个界面中,我们就可以使用自然语言的方式,随意的向我们的搜索引擎提问啦。
其他:提升搜索引擎准确度
通常情况下,我们想要搜索的内容,可能会带有一些标签属性,我们可以通过配置 “faceted_search”或“过滤器”、甚至通过限制“日期”、“地理坐标”来完成更高精度的内容检索。
通常情况下,你可以在不需要对搜索召回内容打分的情况下,得到更好的搜索结果。
这部分的代码,参考上面的文档链接,对本文中的 API 调用程序的参数进行更新即可实现,比较简单,就不做过多赘述啦。
最后
好了,这篇文章就先写到这里吧。下篇文章再见。
—EOF