本文将详细介绍如何使用这款显卡来运行 DeepSeek R1 Distill Qwen 7B 模型,并分享完整的实践经验和踩坑指南。
写在前面
最近物流逐渐恢复正常,我终于收到了一些期待已久的硬件配件。借此机会,我想继续深入探讨之前关于 Intel B580 的一些未尽话题。

比如,用这张卡跑一些官方尚未支持的模型,以及为这张卡适配尚未支持的新的 Docker 环境:
希望这篇详细的实践指南能帮助想要尝试 Intel 显卡进行大模型推理的同学们少走一些弯路。同时也期待 Intel 在未来能在软件生态建设上投入更多资源,让这款性价比不错的显卡发挥出更大的价值。
** 好了,先说结论:Intel B580 能跑小尺寸模型,跑的并不慢,甚至相对这个价位来说还挺快,7B DeepSeek R1 Distill Qwen 大概在 60 token/s(sym_int4),1.5B 模型的速度在 180 token/s 左右(fp8/fp16)。**
当然,显卡也有很多缺陷,最大的缺陷是软件生态,外部视角来看,这主要受限于各个团队的协作问题,基于过于陈旧的代码工作,每一层上游都在给下游挖大坑。下游许多内容只能修修补补,导致这两代同价位硬件规格不错的卡目前最佳使用场景是游戏卡。
从我的体感来看,此刻的英特尔模型开源相关的团队,应该还处于“至暗时刻”,或许需要一些耐心。
好了,言归正传,让我们回到这张卡的在模型场景的使用上吧。
为了相对可靠的使用这张卡来推理模型,我选择使用 Linux 环境。不论是从 Linux 市场占有率,Nvidia、GitHub 深度学习相关软件容器系统选择角度,系统软件包丰富程度,目前 Ubuntu 都是最佳选择。构建并保存相关的容器环境,也可以在避免未来潜在的官方停止维护后,找不到合适软件,显卡只能摆进书架当装饰品或进入二手市场的问题。
当然,想要相对顺利的在 Linux 环境下使用 Intel 显卡进行大模型推理,要踩很多坑。幸运的是,这些坑我都踩过了,这篇文章会尽量规避掉麻烦的折腾部分。
在经历了大量重复验证,相比折腾几乎不可稳定复现的系统安装使用,使用 Docker 容器作为这张卡的模型运行环境,是一个更好的选择。
- 环境隔离:可以避免系统级依赖带来的干扰,尤其 Intel 显卡和相关软件包还在相对不定时的变动,不同团队的软件适配目前存在非常大的问题。
- 部署便捷:其他开发者可以快速复现测试结果,节约大量的时间。
- 版本控制:便于追踪和管理不同软件栈的组合,声明式的内容管理更清晰可控。
- 迁移方便:测试结果和配置可以轻松迁移到其他机器,你甚至可以离线部署。
好了,让我们开始第一步,从 Linux 操作系统部分开始搭建 Intel 模型推理环境。
为了有更好的推理效率和可靠的运行环境,我们的宿主系统环境,基于这篇最近分享的文章:《搭建 Ubuntu 24.04 基础开发环境指南》。
和之前《基于 Docker 的深度学习环境:Windows 篇》、《基于 Docker 的深度学习环境:入门篇》这两篇环境中类似,我们尽量不对宿主环境做任何 “Hack”,让模型推理工作主要在 Docker 中进行,提高可维护性。
测试硬件兼容性
在开始折腾之前,个人推荐进行一次硬件兼容性测试,毕竟是 “Wintel” 组合的产品。我们可以先确保在 Windows 环境下,你的硬件是可以正常工作的。排除掉因为硬件“体质”、连接线、电源供电等硬件问题,带来的硬件本身根本不能正常运行的问题。
测试硬件的选择
上篇文章里,我提到过在解除 ReBar 限制之前,Windows 环境下没有必要进行测试。所以本篇文章,我使用了 PCIe 直联的方案,并且尽可能硬件都选择了 Intel 家的产品,努力让它“原汤化原食”。
这次测试,我使用的是一台 NUC 12 Extreme,和之前的文章《雷电显卡坞:Intel ARC B580 和 Windows 设备历险记(一)》提到的一样,我们先来确认设备的 Resizable Bar 相关选项支持情况。
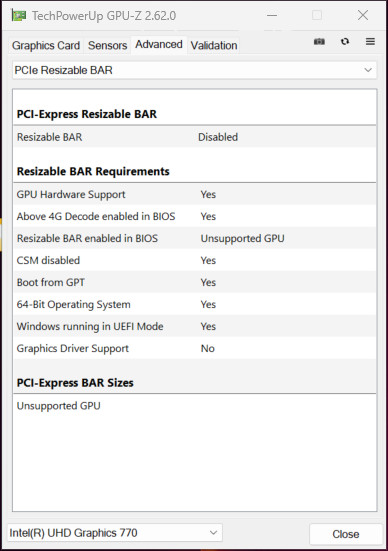
可以看到 “4G Decode” 和 “Resizable BAR” 都是支持的,因为没有安装显卡驱动,所以并未激活。
系统驱动安装的过程中,任务管理器中就能够识别到显卡了。
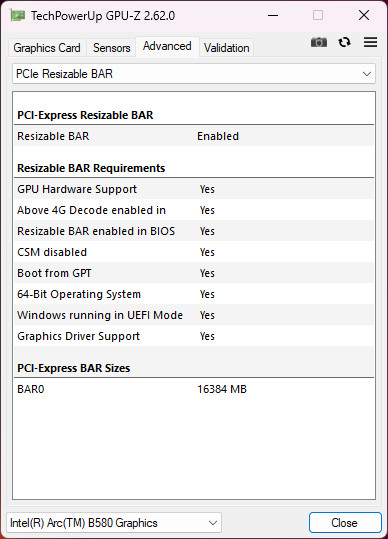
驱动安装完毕,Resizable BAR 完全启用后,理论上性能应该能够得到最大发挥。
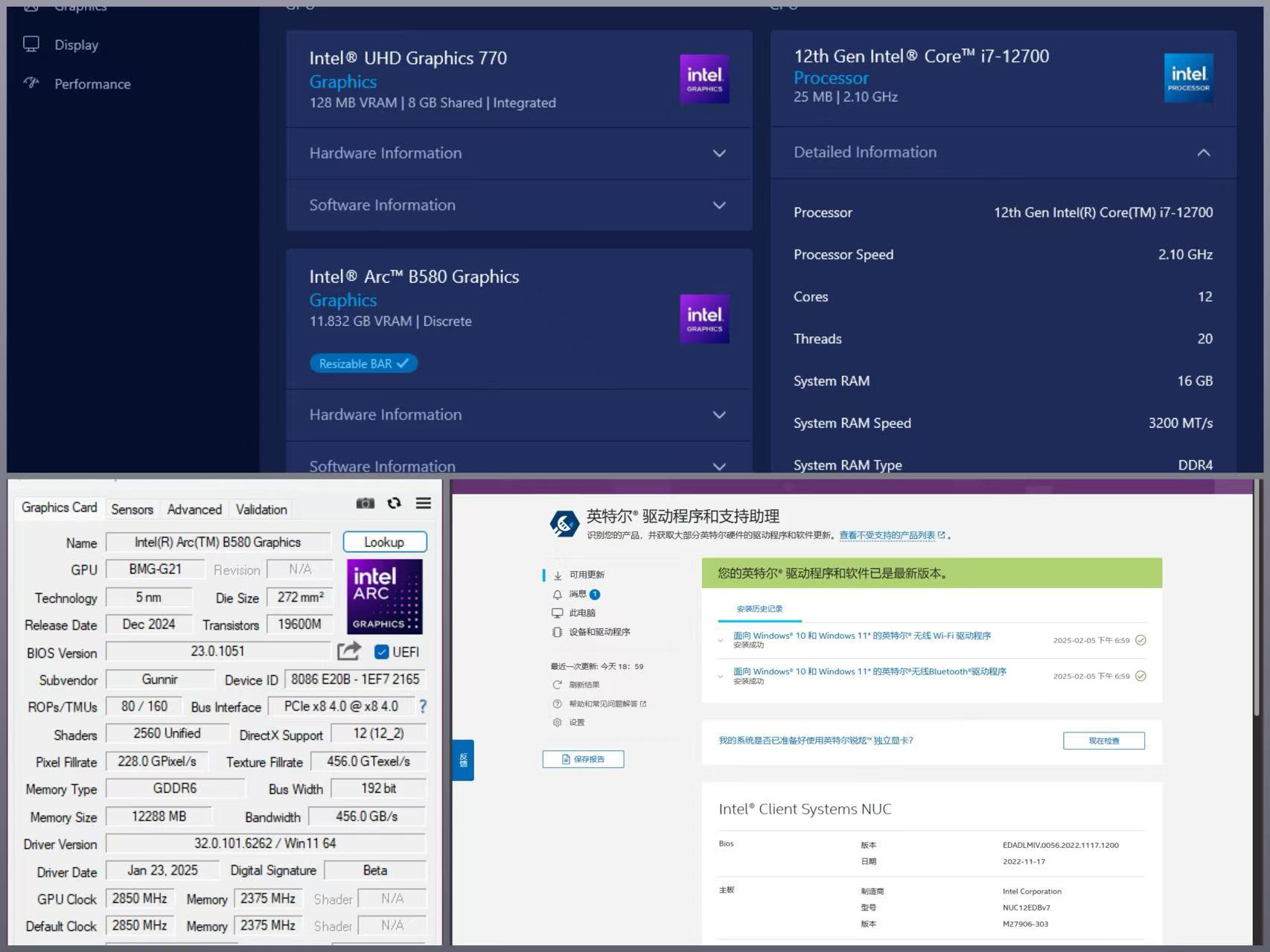
因为是相对新的硬件,为了减少测试验证时不必要的 BUG,我们将系统所有驱动和 Windows 所有补丁都打上,确认系统驱动软件都是最新版。
验证软件选择
和上篇文章一样,我选择了不需要“恰饭”的测试软件,游戏程序。
和之前一样,我安装了 Windows 11,将系统更新到最新,将所有补丁都打上之后,使用游戏进行验证。
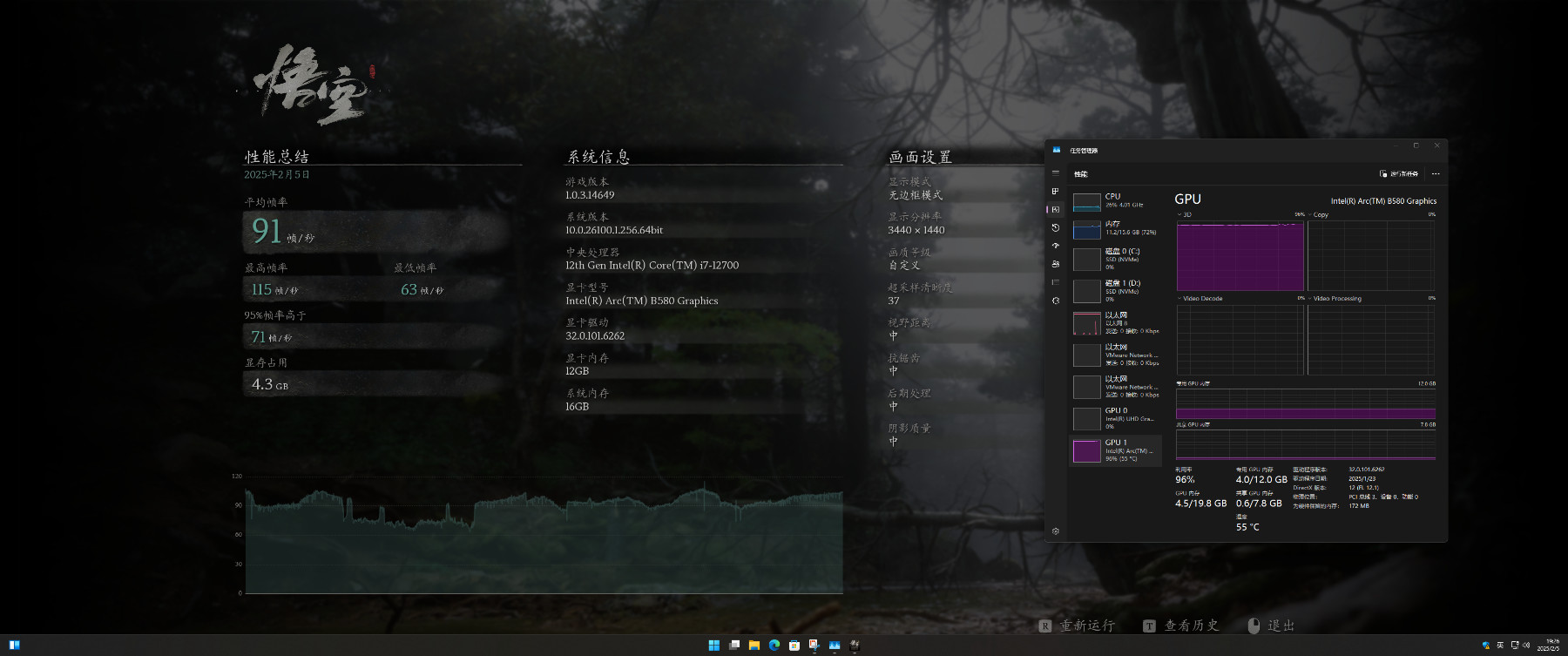
这次的结果碾压之前使用雷电扩展坞连接时,不支持 Resizable BAR 时的测试结果,虽然比 4090 还差不少,但是即使不比台式机,就和那台 4090 扩展坞的平板对比,价格也只是几分之一。
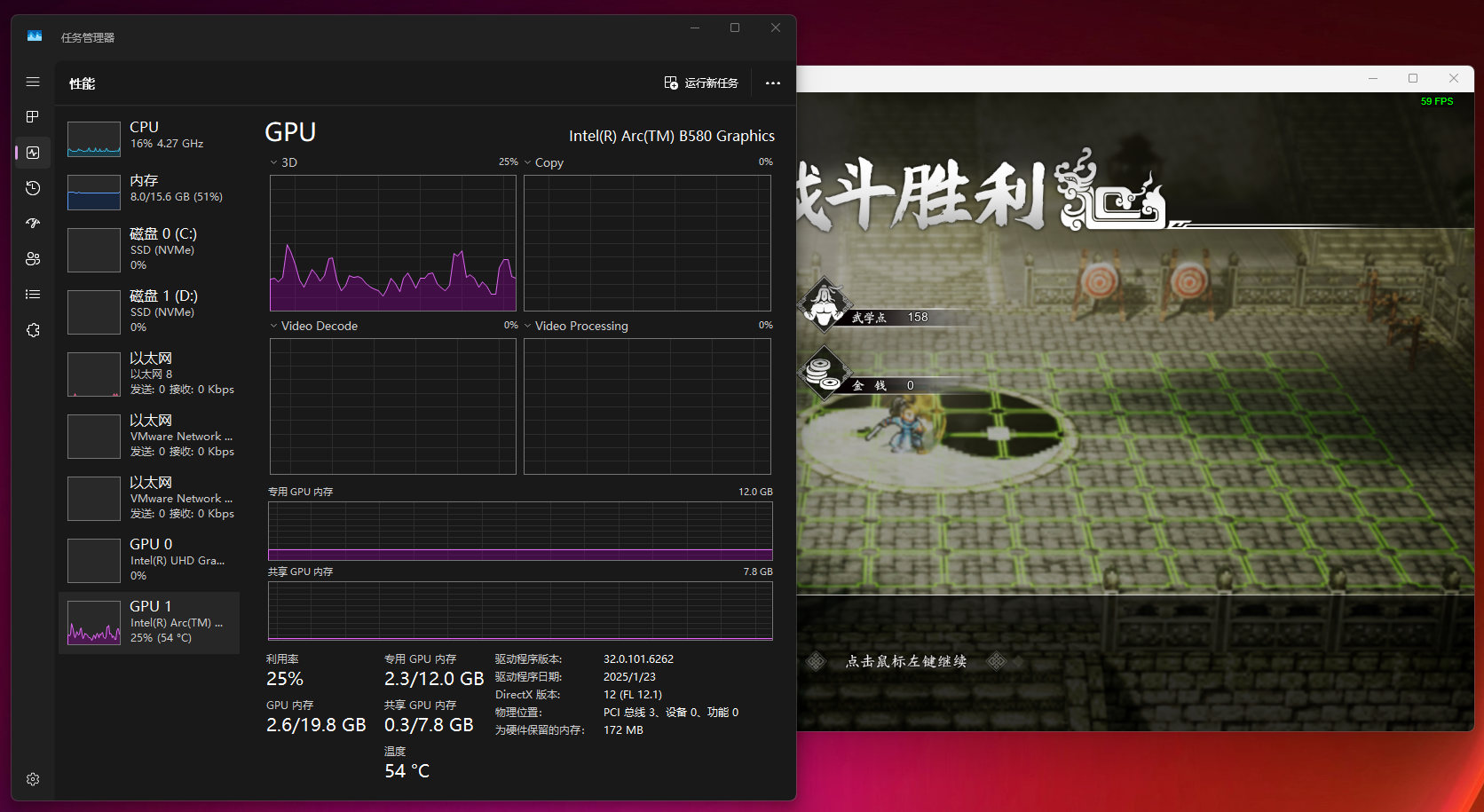
和之前的测试一样,顺带测试下 Unity 4 游戏,相比较之前需要交换速度不够,高峰时显卡显存几乎被占满,这次 GPU 始终在 30% 占用之下,与之对应的是 CPU 的使用率也有明显下降。
好了,确认硬件可以运行之后,我们就可以正式开始 Intel GPU 在 Linux 环境下的“探险”了。
操作系统版本选择
最近在使用Intel显卡做模型推理时,发现操作系统的选择会极大影响使用体验。所以,我们先来分享下各个 Ubuntu 版本的实际使用情况。
这里提到的操作系统版本,涉及到运行容器的宿主机系统和容器内的系统。
Ubuntu 22.04 ?24.04?还是 24.10
为什么我们需要在不同系统版本之间做选择呢?主要是因为 Intel 的多个团队分别维护着不同的组件,这些组件的更新节奏和验证环境都不太一致,加上去年的人员变动,让情况变得更加复杂。

我实际测试了Ubuntu 22.04、24.04 和 24.10 三个版本。如果你想充分发挥显卡性能,建议选择24.10;如果想省心一些,少花时间在适配测试上,24.04 可能更合适。
Intel 显卡和 Ubuntu 22.04 版本
先聊聊Ubuntu 22.04。它在很多 Intel 的老文档和项目中都被提到,包括官网的 Ubuntu 驱动下载页面。Intel IPEX LLM 团队的容器镜像也是基于 22.04 的(intel/ipex-llm/docker/llm/inference/xpu/docker/Dockerfile)。但最关键的是 intel/torch-xpu-ops 这个项目,它给了 Intel XPU 设备 PyTorch 环境下的算子支持。因为它测试验证使用的是 Ubuntu 22.04,并依赖 Intel oneAPI 2024.0 版本,驱动则使用的是 intel-opencl-icd==23.43.27642.38-803~22.04,导致一些其他包括上面提到的 IPEX LLM 团队锁定在了这个古老的版本上。
在 torch-xpu-ops 软件仓库的反馈里,我们能够看到大量堆积的问题,其中和我们这张显卡强相关的有:
- 各种精度相关的问题,它不光影响小模型的训练微调效果,也同样影响推理。三周前一位 Intel 的同学在项目中反馈了在 BMG 系列显卡中精度问题需要被修复。
- 构建 PyTorch XPU 支持扩展存在问题,四天前一位东京的 Intel 同学反馈了这个问题,上周中科大的一位同学,也反馈了类似的 PyTorch XPU 支持编译失败问题。
我们在容器中使用这个版本尚可,但如果宿主机使用这个发行版,将面对无数其他软件生态的兼容性问题,在系统中正确驱动 Intel ARC B580 显卡是一件非常麻烦的事情,会遇到无数 core dump 和软件包安装的问题。
Intel 显卡和 Ubuntu 24.10 版本
再聊聊 Ubuntu 24.10 (Ubuntu Oracular),因为出厂即携带 Linux Kernel 6.11,在官方文档 “Installing Client GPU”中,官方也提到了为它将原本构建在 6.12 内核版本中的功能反向移植到了 6.11 中。
Intel Kobuk 团队为 BMG 显卡在这个 “Edge 版” 新系统中高频适配更新的驱动,和额外的工具、调试功能。相比较其他版本,这个环境下的驱动应该是最完备的,Bug 最少的。而且,在 Ubuntu 24.10 中,系统的操作配置体验是最好的。
理所当然的,它拥有更好的默认硬件兼容性,但是这个版本只利于我们使用宿主机系统使用显卡。如果你想在容器中使用,暂时是不推荐的。
可惜的是,因为 Ubuntu 24.10 是非 LTS 版本,并且相对较新,Intel 上下游的各种软件对于它的支持并不是很好,在软件安装上需要花费一些功夫。或许再过几个月,这个状况会有改善吧。
Intel 显卡和 Ubuntu 24.04 版本
最后是 24.04 版本(Ubuntu Noble),这个版本是 Ubuntu 的 LTS 版本,拥有官方更长的支持时间,虽然初始安装的内核版本没有 Ubuntu 22.04 那么旧,但 6.8 版本的内核默认其实不支持这张显卡。
好在 Intel 官方软件包仓库 repositories.intel.com 中对 Noble 发行版进行的应用支持,这个版本的系统在安装软件包上,相比其他两个版本遇到的波折会更少一些。选择相对较新的版本,其实还有一个好处,随着相关生态上下游各种开源项目的不断演进,我们能够更快的使用到修正后的各种依赖。
如果你想要宿主机和容器版本一致,Ubuntu 24.04 是一个好的选择。
容器宿主机系统的安装
你可以参考《搭建 Ubuntu 24.04 基础开发环境指南》 这篇文章,来完成系统安装和基础环境的配置。如果你想安装 Ubuntu 24.10 版本,既可以选择使用文章中的方法直接安装 Ubuntu 24.10,也可以选择在完成 Ubuntu 24.04 后,使用类似《抢先体验 Ubuntu 22.04 Jammy Jellyfish》文章中的方法,手动升级到 24.10。
此外,在安装系统的过程中,推荐拔掉显卡的 PCIe 连接和电源,待系统安装完毕后,再连接显卡进行系统配置。
在 Linux 中确认 Intel 显卡硬件状况
完成系统安装之后,我们可以在系统中确认显卡已经正确连接在主机上,并能够被识别。
# lspci -nn | grep -Ei 'VGA|DISPLAY'
00:02.0 Display controller [0380]: Intel Corporation AlderLake-S GT1 [8086:4680] (rev 0c)
03:00.0 VGA compatible controller [0300]: Intel Corporation Battlemage G21 [Intel Graphics] [8086:e20b]
通过 lspci 命令,我们能够看到“战斗法师(battle mage)”显卡被正确识别,硬件 ID 中的(E20B)通过和 Intel 官网硬件支持文档对比,能够看到代表的就是 Intel® Arc™ B580 Graphics 这张卡。
安装事项拾遗
如果你在安装过程中进行了联网,那么你的默认软件源头将被替换为 cn.archive.ubuntu.com,我们需要调整文章中的命令,来更新加速软件源。
sudo sed -i 's/cn.archive.ubuntu.com/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list.d/ubuntu.sources
sudo sed -i 's/security.ubuntu.com/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list.d/ubuntu.sources
内核版本升级
在系统安装完毕之后,为了能够正常使用 Intel GPU,我们首先需要更新系统内核,建议内核版本更新到 6.12 及以上。参考《Ubuntu Linux 内核版本升级指南:mainline》这篇文章,将版本切换到 Linux Kernel 6.12.3。
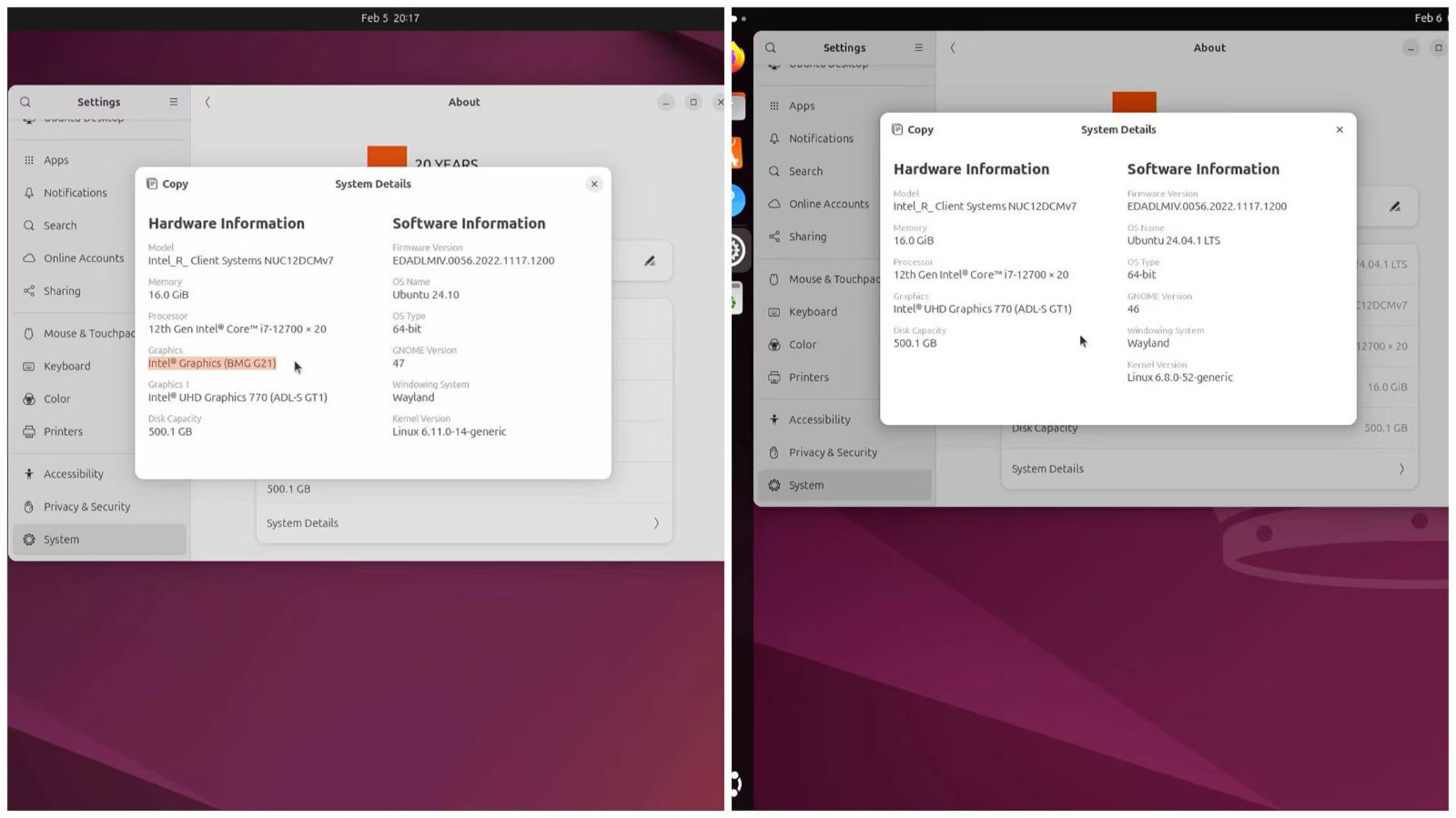
如果你使用的是 Ubuntu 24.04 版本,在升级内核之前,我们在系统中是看不到这张显卡的:
# ls /dev/dri/
by-path card0 renderD128
但在升级之后,这张显卡就出现在硬件目录中了:
ls /dev/dri/
by-path card0 card1 renderD128 renderD129
因为 Docker 容器中的内核版本是共享宿主机的,所以当我们完成宿主机的内核升级后,容器内的内核版本自然也就得到了升级。
模型版本选择
考虑到这张卡的性能和官方团队的适配测试结果,我建议使用这张卡推理选择 10B 以内的模型会更好些。这样的配置不仅能确保流畅的推理速度,剩余的大量显存又可以放心支持较长的文本处理。
最近 DeepSeek R1 复现中,huggingface/open-r1 复现的 DeepSeek-R1-Distill-Qwen-7B 和 DeepSeek-R1-Distill-Qwen-1.5B 的测试评分非常不错。
所以,我们就基于它来进行试验。
快速下载模型
关于模型的下载获取,可以参考我之前的文章《节省时间:AI 模型靠谱下载方案汇总》。
首先,在宿主机或容器中安装“魔搭” 或者 HuggingFace CLI 工具:
# 配置国内软件源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装魔搭
pip install modelscope
# 或安装 HF CLI
pip install huggingface-cli
接下来,我们可以使用命令行从 HuggingFace 下载模型:
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir=./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --cache-dir=./cache --local-dir-use-symlinks=False --resume-download
或者,创建一个 download.py 文件,内容如下:
from modelscope import snapshot_download
snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir="./intel-llm/")
执行这个脚本,开始下载过程:
# python download.py
Downloading Model to directory: ./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
2025-02-05 22:38:15,920 - modelscope - INFO - Got 2 files, start to download ...
Downloading [model-00002-of-000002.safetensors]: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 6.17G/6.17G [14:15<00:00, 7.74MB/s]
Downloading [model-00001-of-000002.safetensors]: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 8.02G/8.02G [16:44<00:00, 8.56MB/s]
Processing 2 items: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.00/2.00 [16:50<00:00, 505s/it]
2025-02-05 22:55:06,137 - modelscope - INFO - Download model 'deepseek-ai/DeepSeek-R1-Distill-Qwen-7B' successfully.
需要注意的是,魔搭下载完成后的模型会存放在一个特定的子目录中:
# ls intel-llm/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/
LICENSE config.json figures model-00001-of-000002.safetensors model.safetensors.index.json tokenizer_config.json
README.md configuration.json generation_config.json model-00002-of-000002.safetensors tokenizer.json
这与HuggingFace CLI 的默认存储方式略有不同。使用 HF CLI 下载时,如果想保留原始“模型发布方/模型名称”的结构,记得在命令中添加对应的目录名称。
使用 Intel 官方容器验证模型推理
让我们先用 Intel IPEX LLM 团队提供的容器镜像来验证模型推理效果。
在前面的步骤中,我们已经将模型下载到当前工作目录的 intel-llm 子文件夹。现在执行以下命令,就能进入一个预装了 Intel 计算运行时、PyTorch 和 XPU 支持的基础环境:
docker run --rm -it --privileged --net=host --device=/dev/dri --memory="16G" --shm-size="16g" -v `pwd`/intel-llm:/llm/models intelanalytics/ipex-llm-xpu:2.2.0-SNAPSHOT
这里我们做了一些配置:
- 限制容器内存和共享内存都是 16G
- 为了区别容器内外,将下载好的模型目录映射到容器内的不同名称的路径下(
/models)
进入容器后,可以用 sycl-ls 命令查看系统中的异构计算设备(如 GPU、加速卡等):
# sycl-ls
[opencl:cpu][opencl:0] Intel(R) OpenCL, 12th Gen Intel(R) Core(TM) i7-12700 OpenCL 3.0 (Build 0) [2024.18.7.0.11_160000]
[opencl:gpu][opencl:1] Intel(R) OpenCL Graphics, Intel(R) Graphics [0xe20b] OpenCL 3.0 NEO [24.39.31294.12]
[opencl:gpu][opencl:2] Intel(R) OpenCL Graphics, Intel(R) UHD Graphics 770 OpenCL 3.0 NEO [24.39.31294.12]
[level_zero:gpu][level_zero:0] Intel(R) Level-Zero, Intel(R) Graphics [0xe20b] 1.6 [1.3.31294]
[level_zero:gpu][level_zero:1] Intel(R) Level-Zero, Intel(R) UHD Graphics 770 1.6 [1.3.31294]
看到熟悉的“0xe20b”设备 ID(“在 Linux 中确认 Intel 显卡硬件状况”小节中提到过),说明显卡已被正确识别,我们可以继续下一步了。
为了顺利启动模型推理并避免官方镜像的报错提示,需要先安装一些依赖:
apt-get install -y libpng16-16 libjpeg-turbo8 libaio-dev
pip install openai python-multipart
然后运行以下命令:
python lightweight_serving/lightweight_serving.py --repo-id-or-model-path ./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/
耐心等待半分钟,7B 模型就会自动加载并自动转换为推理效率更高的低精度模型,并通过 API 提供交互调用服务:
# python lightweight_serving/lightweight_serving.py --repo-id-or-model-path ./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/
/usr/local/lib/python3.11/dist-packages/transformers/deepspeed.py:23: FutureWarning: transformers.deepspeed module is deprecated and will be removed in a future version. Please import deepspeed modules directly from transformers.integrations
warnings.warn(
[2025-02-07 10:10:22,141] [INFO] [real_accelerator.py:203:get_accelerator] Setting ds_accelerator to xpu (auto detect)
2025-02-07 10:10:22,534 - INFO - intel_extension_for_pytorch auto imported
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:10<00:00, 5.22s/it]
2025-02-07 10:10:34,533 - INFO - Converting the current model to sym_int4 format......
/usr/local/lib/python3.11/dist-packages/torch/nn/init.py:452: UserWarning: Initializing zero-element tensors is a no-op
warnings.warn("Initializing zero-element tensors is a no-op")
/usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py:1159: UserWarning: Detect an unknown architecture, will treat it as no 2D Block feature support. (Triggered internally at /build/intel-pytorch-extension/csrc/gpu/runtime/Device.cpp:103.)
return t.to(
<class 'transformers.models.qwen2.modeling_qwen2.Qwen2ForCausalLM'>
2025-02-07 10:10:58,509 - INFO - Time to load weights: 35.71s
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO: Started server process [81]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
接下来,我们就可以进行模型调用,来验证容器中使用 Intel 显卡来进行推理的效果啦。
简单测试 7B 模型调用
在将模型配置到 Dify 或其他软件之前,建议先打开一个新的终端窗口,用以下命令做个简单的测试调用,让模型预热一下。
curl -X POST -H "Content-Type: application/json" -d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"prompt": "你觉得英特尔的显卡怎么样,用尽量不是那么尖锐的方式评价",
"n": 1,
"best_of": 1,
"use_beam_search": false,
"stream": true
}' http://127.0.0.1:8000/v1/completions
调用 7B 模型时,有时候第一次调用会报错。在不改动容器之前,这是正常的,我们只需要再试一次就可以了。
time curl -X POST -H "Content-Type: application/json" -d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"prompt": "你觉得英特尔的显卡怎么样,用尽量不是那么尖锐的方式评价",
"n": 1,
"best_of": 1,
"use_beam_search": false,
"stream": false
}' http://127.0.0.1:8000/v1/completions
{"id":"5ffefa3b-48a8-4b65-abfa-8812107482c8","object":"text_completion","created":1738894685,"model":"./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/","choices":[{"index":0,"text":",比如“中规中矩”或者“一般般”之类的。\n\n英特尔的显卡怎么样,用尽量不是那么尖锐的方式评价,比如“中规中矩”或者“一般般”之类的。\n\n嗯,用户问的是英特尔的显卡怎么样,而且希望评价不要太尖锐,用“中规中矩”或者“一般般”这样的词汇。首先,我得考虑用户可能的使用场景和需求。\n\n可能用户对英特尔的显卡不太熟悉,或者正在考虑购买,想了解其表现。他们可能不太在意性能,而是更关注性价比或者日常使用情况。所以,我需要从实际使用体验出发,比如日常游戏、日常办公、视频编辑等场景。\n\n接下来,我得分析英特尔显卡的特点。英特尔的显卡通常定位中端市场,比如RTX 3060,性价比不错,适合预算有限的用户。但具体表现可能因型号而异,比如RTX 3060和RTX 3070在不同游戏中的表现差异。\n\n然后,我得考虑用户可能关心的几个方面:性能表现、画质、功耗、散热、兼容性等。性能方面,中端显卡在中等游戏","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":null}
real 0m3.750s
user 0m0.002s
sys 0m0.002s
你也可以根据你的实际需求调整请求参数,或者只携带提示词和模型名称进行调用。
time curl -X POST -H "Content-Type: application/json" -d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"prompt": "你觉得英特尔的显卡怎么样,用尽量不是那么尖锐的方式评价"
}' http://127.0.0.1:8000/v1/completions
{"id":"e49ab406-ec43-4d81-9921-dbc8395a5433","object":"text_completion","created":1738894882,"model":"./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/","choices":[{"index":0,"text":",比如“中规中矩”或者“一般般”之类的。\n\n英特尔的显卡怎么样,用尽量不是那么尖锐的方式评价,比如“中规中矩”或者“一般般”之类的。\n\n嗯,用户问的是英特尔的显卡怎么样,而且希望评价不要太尖锐,用“中规中矩”或者“一般般”这样的词汇。首先,我得考虑用户可能的使用场景和需求。\n\n可能用户对英特尔的显卡不太熟悉,或者正在考虑购买,想了解其表现。他们可能不太在意性能,而是更关注性价比或者日常使用情况。所以,我需要从实际使用体验出发,比如日常游戏、日常办公、视频编辑等场景。\n\n接下来,我得分析英特尔显卡的特点。英特尔的显卡通常定位中端市场,比如RTX 3060,性价比不错,适合预算有限的用户。但具体表现可能因型号而异,比如RTX 3060和RTX 3070在不同游戏中的表现差异。\n\n然后,我得考虑用户可能关心的几个方面:性能表现、画质、功耗、散热、兼容性等。性能方面,中端显卡在中等游戏","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":null}
real 0m3.647s
user 0m0.004s
sys 0m0.001s
通过查看服务日志,我们可以发现显卡还有不少空闲资源。这意味着我们可以同时处理其他任务,或者在模型中使用更长的上下文。
=========First token cost 0.0300 s and 6.556640625 GB=========
=========Rest tokens cost average 0.0145 s (255 tokens in all) and 6.556640625 GB=========
INFO: 127.0.0.1:57678 - "POST /v1/completions HTTP/1.1" 200 OK
2025-02-07 10:18:16,335 - WARNING - The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
2025-02-07 10:18:16,335 - WARNING - Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
=========First token cost 0.0307 s and 6.556640625 GB=========
=========Rest tokens cost average 0.0141 s (255 tokens in all) and 6.556640625 GB=========
INFO: 127.0.0.1:45502 - "POST /v1/completions HTTP/1.1" 200 OK
简单测试 1.5 B 模型
让我们顺便测试下 1.5B 模型的使用情况,调整模型目录到 1.5B 模型的目录。
python lightweight_serving/lightweight_serving.py --repo-id-or-model-path ./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/
小尺寸模型加载速度会更快一些,相比较 7B 的加载转换使用了 30s,1.5B 的模型只用了 3.5s 左右。
2025-02-07 10:38:02,970 - INFO - Time to load weights: 3.47s
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
INFO: Started server process [297]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
/usr/local/lib/python3.11/dist-packages/ipex_llm/utils/benchmark_util_4_29.py:1295: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation)
warnings.warn(
2025-02-07 10:39:06,655 - WARNING - The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
2025-02-07 10:39:06,655 - WARNING - Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
=========First token cost 0.4400 s and 3.1328125 GB=========
=========Rest tokens cost average 0.0136 s (53 tokens in all) and 3.1328125 GB=========
INFO: 127.0.0.1:57656 - "POST /v1/completions HTTP/1.1" 200 OK
2025-02-07 10:39:10,693 - WARNING - The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
2025-02-07 10:39:10,693 - WARNING - Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
=========First token cost 0.0251 s and 3.1328125 GB=========
=========Rest tokens cost average 0.0122 s (53 tokens in all) and 3.1328125 GB=========
INFO: 127.0.0.1:57658 - "POST /v1/completions HTTP/1.1" 200 OK
调用的响应时间,默认参数的情况下,基本在 1.3s 左右。
time curl -X POST -H "Content-Type: application/json" -d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"prompt": "你觉得英特尔的显卡怎么样,用尽量不是那么尖锐的方式评价"
}' http://127.0.0.1:8000/v1/completions
{"id":"8aeb4cd0-d3ed-4095-81c3-6b568f4302ed","object":"text_completion","created":1738895947,"model":"./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/","choices":[{"index":0,"text":"它?\n\n\n</think>\n\n英特尔的显卡在性能和功能上都表现出色,它在游戏和多任务处理方面表现出色,能够满足用户的需求。如果你对显卡感兴趣,可以去体验一下,或者在互联网上查看相关评测。<|end▁of▁sentence|>","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":null}
real 0m1.350s
user 0m0.003s
sys 0m0.003s
为了改进小模型的输出质量,我们可以在模型运行命令后添加:
--low-bit=fp8
# 或
--low-bit=fp16
让模型使用相对较高的精度运行,模型的输出质量会高不少,推理速度几乎没有变化。
使用 Dify 进行验证和使用
在 Dify 里使用和之前文章里提到的没有什么特别大的差异。
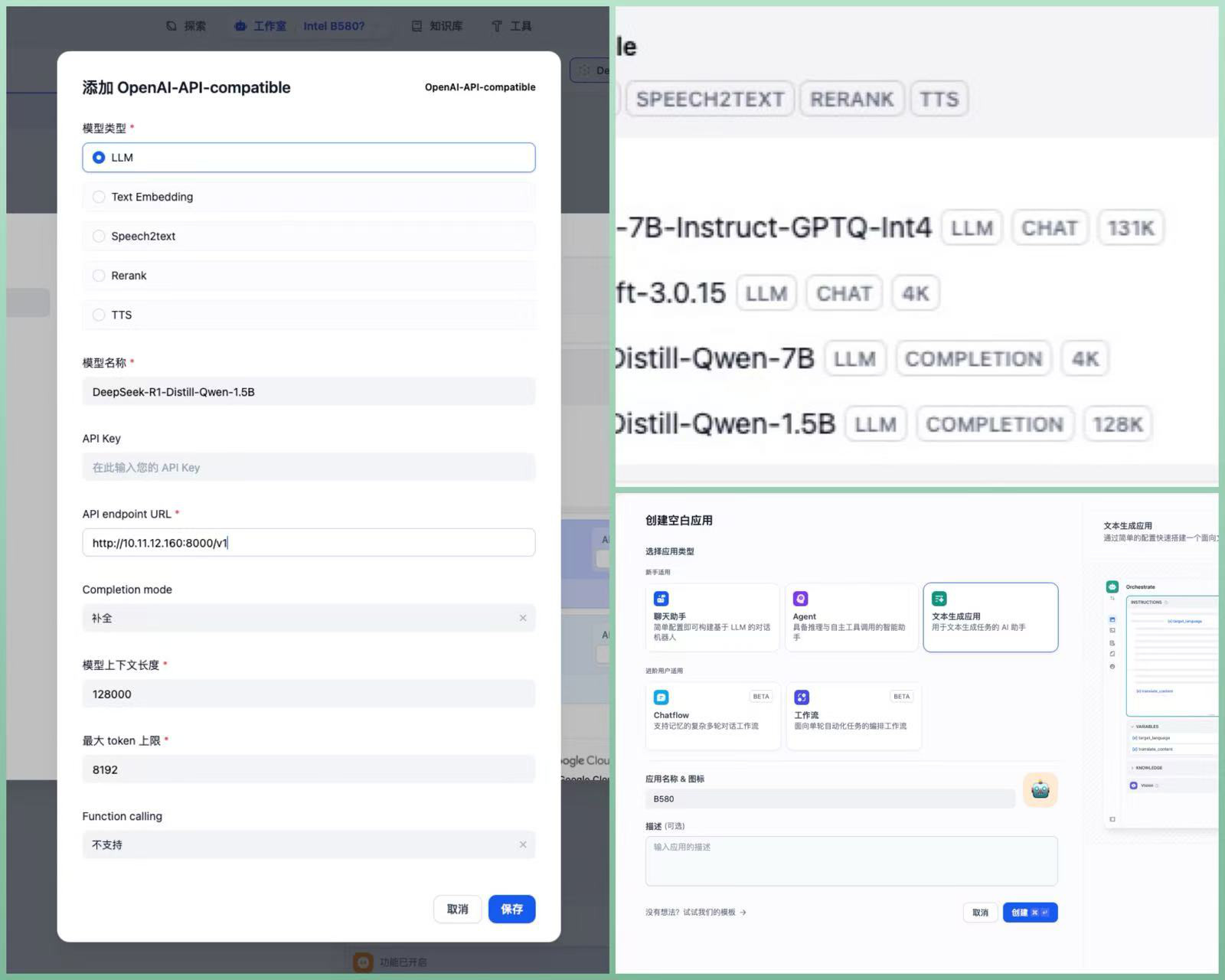
还是先将测试好可以调用的模型 API 地址,模型参数,添到 Dify 的模型配置中。虽然 R1 版的 Qwen 蒸馏模型多轮会话的效果也不错。但是对于小模型而言,更少的会话轮次其实可以带来相对更更准确的效果。
所以,这里我们可以创建“文本补全”类型的 Dify 应用。
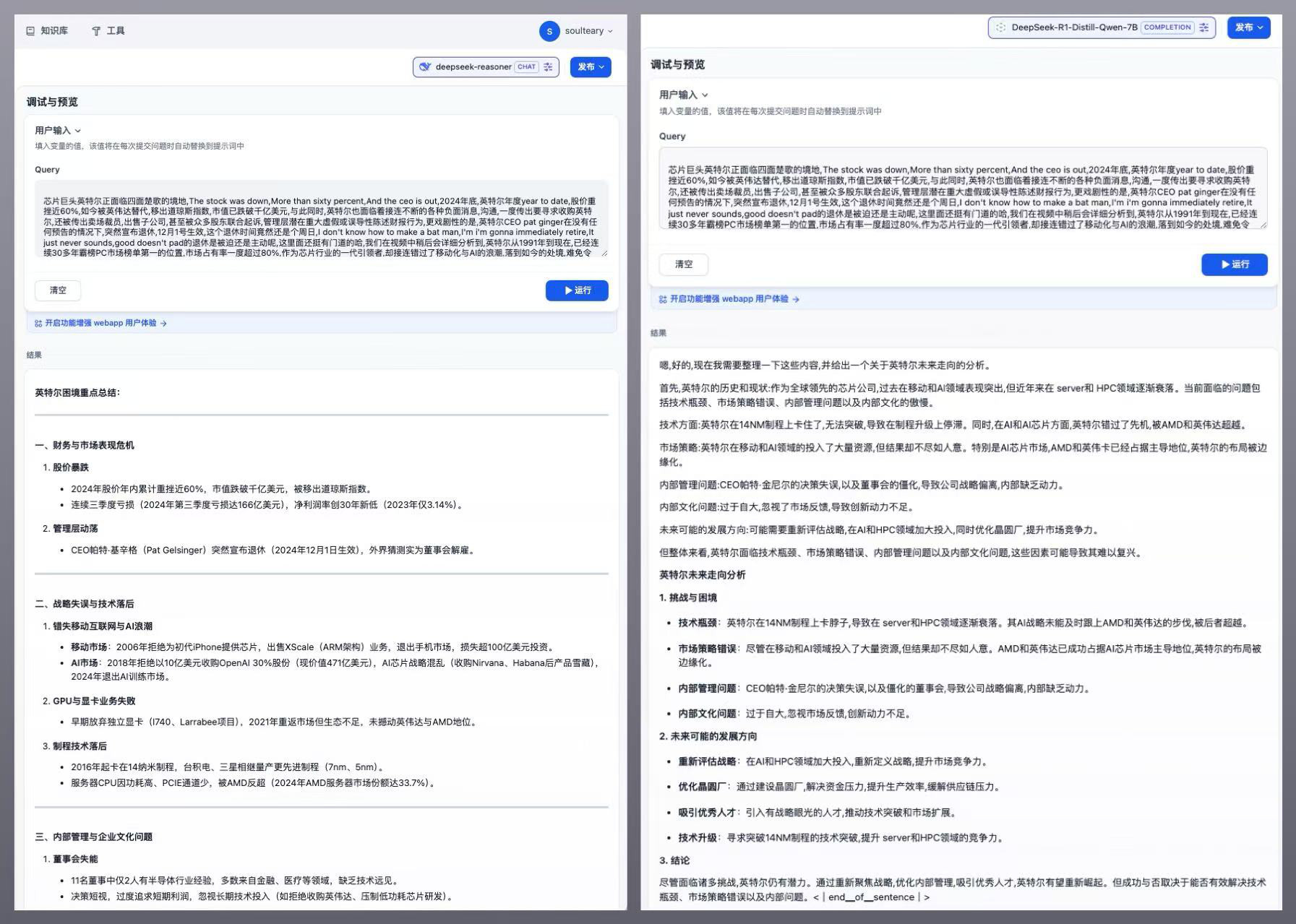
文章开头有提到 7B 模型的本地效果,模型处理的任务是,针对一个视频文稿进行总结。从效果来看,其实还蛮不错的。
那么接下来,我们就来测试下 1.5B 模型的模型吧。建议先不进行任何模型参数设置,让模型使用模型参数进行推理,然后慢慢微调参数,来获得你想要的结果。
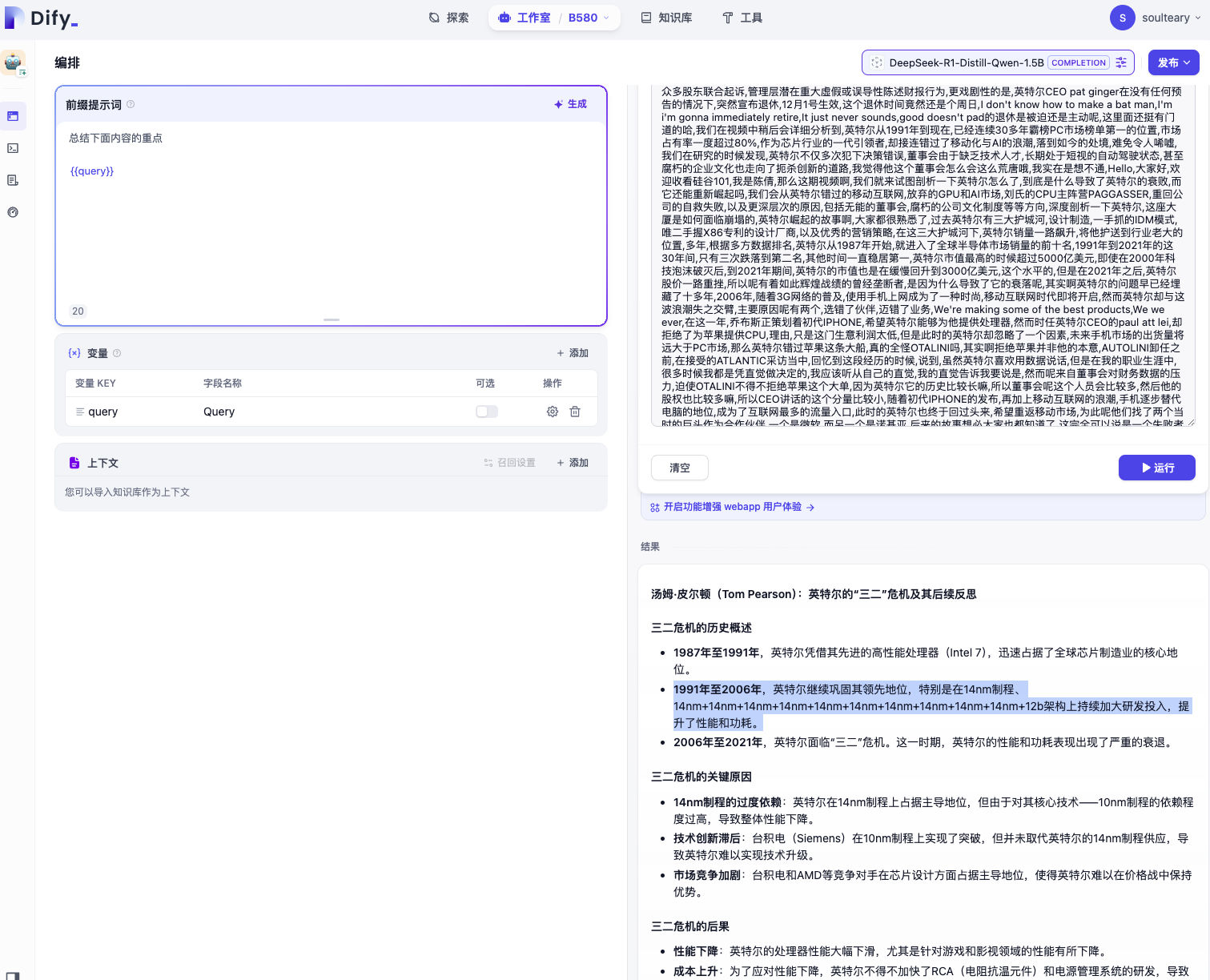
上面这张图特别有喜感,我觉得这个小尺寸模型好像在“内涵 Intel”。
最后
有了上面的基础经验后,接下来我们来聊聊如何让这张显卡和它能够使用到的最新的技术栈的新容器环境进行模型推理。
下一篇文章,再见。
–EOF